Utilized Reinforcement Studying
The Machine Studying Structure Behind AlphaGO Defined

In 2016 AlphaGo beat the world’s finest participant on the recreation of go. Then, it appeared unimaginable; now, it’s remembered as a key milestone within the historical past of machine studying.
Recreation of Go and Machine Studying
Video games, whether or not they’re board video games or video-games, are the proper platform to check, consider and enhance machine studying fashions. Video games typically have a really clear scoring system, and due to this fact current a transparent and efficient approach to quantify and measure progress.
Previously, there have been key milestones within the historical past of know-how marked by different board video games. When DeepBlue beat the world chess champion Garry Kasparov in 1997, this was seen as an unbelievable achievement on the planet of computing. On the time, many thought it might take many extra many years, and a few thought it might by no means occur.
This mannequin labored because of human enter (by different chess grandmasters) and uncooked computing energy. It was in a position to look many strikes forward, beating people. Some criticise DeepBlue’s strategy, like Michio Kaku, in his 2008 e book “Physics of the Unimaginable”, by saying that this occasion was a victory of “uncooked laptop energy, however the experiment taught us nothing about intelligence”. He provides, “I used to assume chess required thought”. He attributed the victory of machine over human to the truth that DeepBlue may calculate strikes positions approach sooner or later, with out creativity or intelligence.
The sport of Go is far more advanced than chess. At any given place in chess, the anticipated variety of authorized strikes is round 35, in GO, it’s 250. In truth, there are extra potential configurations in a GO board than there are atoms within the universe. Computing strikes sooner or later just isn’t a technique that may work, and due to this fact to unravel the sport of go, actual thought, creativity and intelligence is required.
This is the reason defeating the world’s finest people on the recreation of Go was such an vital milestone of the world of Machine Studying, and on this article, I wish to undergo how Google’s DeepMind was in a position to grasp this recreation and beat a number of the finest gamers in historical past.
The Guidelines of GO
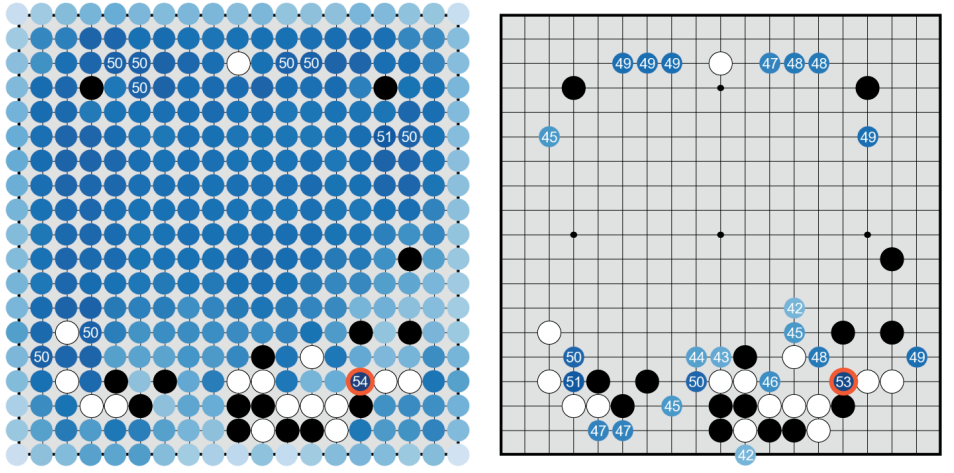
Earlier than I get into the ML, a quick description of the sport of Go. The sport of Go is kind of easy. Every participant locations a chunk on the board, separately. The objective is to encompass empty house together with your items. You win factors by surrounding empty house. In case you encompass your opponent’s items, these are captured (see the pale black items on the underside left of the picture above). On the finish of the sport, the participant that controls probably the most empty house wins. Within the remaining place above, white controls extra empty house, so white wins.
I attempted enjoying Log on, and did terribly. The excellent news is you don’t want to know Go or be any good at it to know the machine studying behind AlphaGo.
Reinforcement Studying, the Fundamentals
“Even in the event you took all of the computer systems on the planet, and ran them for 1,000,000 years, it wouldn’t be sufficient to compute all potential variations {within the recreation of GO}” Demis Hassabis, co-founder and CEO of Deep Thoughts.
Reinforcement studying is the class of fashions in machine studying that study by enjoying. These fashions study a bit like a human would, they play the sport over quite a lot of iterations, enhancing as they win or unfastened. I’ve one other article explaining how reinforcement studying works in far more element. You may test it out right here.
For a fast recap, the core of reinforcement studying could be understood by means of the next definitions:
The agent is the algorithm that’s enjoying the sport.
The atmosphere is the platform on which the sport is enjoying, within the case of GO it’s the board.
A state is the present place of all of the items within the atmosphere.
An motion is the transfer that the agent might take at a given state on the atmosphere.
The worth signifies the probability of profitable a recreation given a state or an motion/state pair.
The coverage is the tactic with which the agent chooses the following motion, primarily based on the expected values of the following states (do you all the time go for what you assume is the most effective motion in keeping with the worth perform? do you have to discover every so often to study one thing new?).
The objective of an RL algorithm is to study the optimum worth perform, which is able to permit it to find out at any given state what’s the motion that may consequence within the highest probability of it profitable the sport.
Mastering the sport of Go along with Deep Neural Networks and Tree Search
Paper by David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel & Demis Hassabis. Revealed on Nature, 2016.
Right here I’ll undergo AlphaGo’s structure. While studying this part, be at liberty to refer again to the definitions above.
AlphaGo consists of two kinds of neural networks, coverage networks and a worth networks.
Coverage Networks
BLUF: The objective of the coverage community is to find out the possibilities of the following motion given a state. The coaching of the coverage community is damaged down into 2 steps. First, a coverage community is educated by means of supervised studying ( the SL Coverage Community) on skilled recreation knowledge. Then, the weights of this mannequin are used because the initialisation for the coverage community educated utilizing reinforcement studying (the RL Coverage Community).

Supervised Studying (SL) Coverage Community: The enter of the coverage community is the state. The state, as mentioned above, represents the positions of the items. The board is 19×19. To enhance the enter, they develop it utilizing 48 function maps, making the enter 19x19x48 formed. These function maps assist the algorithm seize the place of the board, this can be by highlighting the empty areas round items, the conglomerations of items and so on. This growth helps the algorithm study.
The SL coverage community is a supervised studying classification mannequin (thus far, no reinforcement studying). It’s educated utilizing skilled participant video games. The coverage community is then given the duty to foretell the following almost definitely motion after a given state p(a|s). The coverage community is a Convolutional Neural Community (CNN), and it outputs a sequence of possibilities for what the following motion ought to be (a 19×19 output).

The weights (σ) of the coverage community (p) could be up to date proportionally to the time period proven above. That is principally cross-entropy loss in a supervised studying classification setting. Right here we’re updating the weights to maximise the probability of a human transfer (a) given the state (s).
The rollout coverage is a a lot smaller community, educated in the identical approach. It’s a linear layer, and it’s educated on much less knowledge. It’s a lot quicker to compute future positions, and due to this fact it turns into helpful in a while when performing a tree-search.
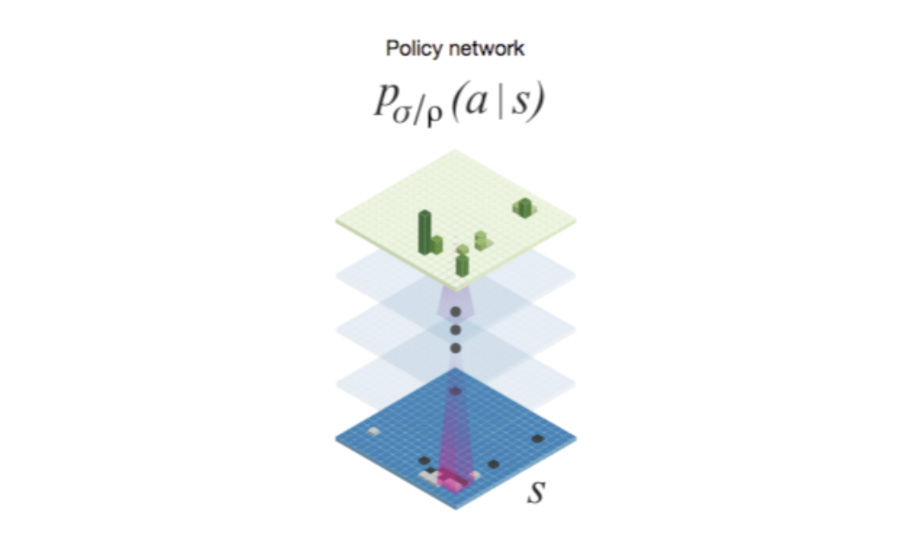
RL Coverage Community: Thus far the coverage networks have been supervised studying fashions, and all they do is imitate skilled gamers utilizing their coaching knowledge. These fashions nonetheless haven’t learnt to play the sport by itself. To take action, the SL coverage community is improved by means of reinforcement studying.
The RL coverage community is initialised with the weights of the SL coverage community. It’s then educated by means of self play, the place you’re taking a pool of those fashions, they usually play towards each-other. On the finish of a recreation, the chance that the mannequin performs the wining mannequin’s actions ought to improve, and the alternative is true for the loosing mannequin’s actions. By having the mannequin play itself, we are actually instructing the mannequin to win video games, quite than to simply imitate grand masters.

The replace perform of the weights is just like that of the SL coverage community. This time nonetheless, we wait till the top of the sport to carry out the replace. z is the reward primarily based on the end result of the sport. If the agent gained, then z is the same as +1, and if it misplaced it is the same as -1. This fashion we make the mannequin want strikes that it performed when it gained, and is much less more likely to play strikes that it performed when it misplaced a recreation.
The Worth Community
BLUF: The worth community predicts the chance of an agent wining a recreation given the state. With an ideal worth community, you may decide the most effective transfer in every place, by selecting the motion that ends in the state with highest worth. In actuality, the authors used a Tree Search technique to find out the following finest motion, nonetheless utilizing this approximate worth perform.
To coach the worth community, 30 million video games are generated by self-play (having the SL coverage networks play themselves). Then, the worth community is educated as a regression on random states from every of these video games, to find out whether or not the place is wining or loosing. That is as soon as once more a supervised studying activity, though this time a regression activity.

The replace of the gradients of the worth perform is proven above. The scaling time period on the proper hand aspect is a perform of the end result z and the output of the worth perform v(s). If when given a state the worth perform appropriately predicts that the agent will win, the scaling time period stays constructive. Nevertheless, if the worth perform predicts that the agent will unfastened, however finally ends up profitable, the scaling time period is unfavorable and we replace the gradients in the wrong way. The magnitude of this scaling time period will increase with how unsuitable the worth perform’s prediction was in regards to the probability of wining the sport. That is principally L2 loss in a supervised regression activity.
Tree Search
To be able to decide the following finest transfer, a tree search is carried out.

The tree search begins at a given state s. An motion is chosen primarily based on Q and u(P).

Q is the motion worth perform, which determines the worth of an motion quite than a state.
u(s|a) is the output of a tree search algorithm, the place the output is proportional to the prior (numerator within the equation above, the prior is taken from the SL coverage community). u(s|a) can also be inversely proportional to the variety of visits to leaf within the tree given an motion (N(s, a)). In the beginning, the algorithm to discover new strikes, and belief much less the Q worth perform (taking the u a part of the argmax, since N(s, a) might be small), however after the search algorithm converges on the identical leaf many occasions, it begins relying extra on Q, permitting it to discover deeper into promising branches which were visited typically.

To calculate Q (the motion worth perform), they first consider every leaf utilizing V, which is a weighted common between the worth perform (v) of the ensuing state, and the rollout end result (z). The rollout end result is the end result of the sport (win or unfastened) when making use of the rollout coverage community and enjoying out the sport from that leaf state. As a result of the rollout coverage community is small, it’s fast to judge, and due to this fact it may be used as a part of the tree-search to play out the entire recreation many occasions for every leaf, and think about these end result when selecting the ultimate motion. Lastly, to get Q from the leaf analysis V, you merely divide V by the variety of visits of that edge.
Outcomes and Additional Analysis
The AlphaGo fashions have been in actuality a sequence of fashions, every new iteration enhancing on the earlier. Two papers have been revealed, the primary in 2016, “Mastering the sport of Go along with Deep Neural Networks and Tree Search” (the one I went by means of), and a second one in 2017, “Mastering the Recreation of GO With out Human Data”. This second paper presents AlphaGo Zero, which makes use of no prior information (no skilled participant coaching knowledge) and easily depends on the RL coverage community, the Worth Community, and the tree search. The mannequin is solely primarily based on reinforcement studying, and it generalised to play different board video games equivalent to chess, the place it was in a position to beat the most effective engine in chess, stockfish.

AlphaGo Lee was the mannequin that famously defeated Lee Sedol 4 to 1 in 2016, one of many strongest gamers within the historical past of Go. AlphaGo Grasp then went on to defeat a sequence of world chess champions scoring 60 to 0. Lastly, AlphaGo Zero, a greater iteration that used no skilled coaching knowledge (see the Elo rankings above).
Conclusion
On this article, I described the structure of AlphaGo, the machine studying mannequin that defeated the a number of the high Go gamers of all time. I first went by means of a number of the fundamentals of reinforcement studying, after which I broke down the structure of the mannequin.
Now you could be questioning, why put a lot effort into fixing a board recreation? In spite of everything, this isn’t actually serving to anyone. Analysis is about furthering our information as a complete, and video games like Go permit us to quantify progress very simply. The progress that we handle to make on these board video games can then be utilized to unravel better challenges. DeepMind works on fashions to save lots of vitality, id illness and speed up science throughout the globe. This type of analysis is vital because it furthers our information and understanding of AI, and sooner or later it’s more likely to act because the catalyst for a lot of life altering applied sciences.
Assist me
Hopefully, this helped you, in the event you loved it you may observe me!
You can too change into a medium member utilizing my referral hyperlink, and get entry to all my articles and extra: https://diegounzuetaruedas.medium.com/membership
Different articles you would possibly take pleasure in
References
[1] David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel & Demis Hassabis, “Mastering the sport of Go along with deep neural networks and tree search”, Nature, 2016. Obtainable: https://www.nature.com/articles/nature16961
[2] David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel & Demis Hassabis, “Mastering the sport of Go with out human information”, Nature, 2017. Obtainable: https://www.nature.com/articles/nature24270

{kind=link}