Environment friendly algorithms and strategies in machine studying for AI accelerators — NVIDIA GPUs, Intel Habana Gaudi and AWS Coaching and Inferentia

Likelihood is you’re studying this weblog put up on a contemporary laptop that’s both in your lap or on the palm of your hand. This contemporary laptop has a central processing unit (CPU) and different devoted chips for specialised duties resembling graphics, audio processing, networking and sensor fusion and others. These devoted processors can carry out their specialised duties a lot quicker and extra effectively than a normal function CPU.
We’ve been pairing CPUs with a specialised processor because the early days of computing. The early 8-bit and 16-bit CPUs of the 70s have been gradual at performing floating-point calculation as they relied on software program to emulate floating-point directions. As purposes like laptop aided design (CAD), engineering simulations required quick floating-point operations, the CPU was paired with a math coprocessor to which the CPU might offload all floating level calculations to. The mathematics coprocessor was a specialised processor designed to do a selected job rather more shortly and effectively than the CPU.

For those who’ve been following current developments in AI or the semiconductor business, you’ve in all probability heard of devoted machine studying processors (AI accelerators). Whereas the preferred accelerators are NVIDIA GPUs, there are others together with Intel Habana Gaudi, Graphcore Bow, Google TPUs, AWS Trainium and Inferentia. Why are there so many AI accelerator choices right this moment? How are they totally different from CPUs? How are algorithms altering to assist these {hardware}? How is {hardware} evolving to assist the newest algorithms? Let’s discover out. On this weblog put up I’ll cowl:
- Why do we’d like specialised AI accelerators?
- Categorizing machine studying {hardware} — CPUs, GPUs, AI accelerators, FPGAs and ASICs
- “{Hardware}-aware” algorithms and “algorithms-aware” {hardware}
- Co-evolution of AI accelerators and environment friendly machine studying algorithms
- AI accelerators and environment friendly algorithms for inference
- AI accelerators and environment friendly algorithms for coaching
- Way forward for AI accelerators
The three most essential causes for constructing devoted processors for machine studying are (1) vitality effectivity (2) quicker efficiency and (3) mannequin dimension and complexity. Current tendencies to enhance mannequin accuracy, have been to introduce bigger fashions with extra parameters and practice them on bigger knowledge units. We’re seeing this pattern throughout all purposes together with laptop imaginative and prescient, pure language and suggestion methods.
Language fashions resembling GPT-3 have 175 billion parameters, which was thought of excessive simply a few years in the past. Since then we’ve seen fashions like GLaM with 1.2 trillion parameters and NVIDIA’s MT-NLG with 530 billion parameters. If historical past is any indication, mannequin sizes will proceed to get bigger, and present processors gained’t have the ability to ship the processing energy wanted to coach or run inference on these fashions beneath tight time-to-train and inference latency necessities.
Nonetheless, the one most essential purpose we’d like specialised AI accelerators and to make the economics of growing a customized chip work is the necessity for vitality effectivity.
Why we’d like energy-efficient processors?
The bigger the machine studying mannequin the extra reminiscence entry operations you have to carry out. Computation operations like matrix-matrix and matrix-vector computations are way more vitality environment friendly operations than reminiscence entry. For those who take a look at how a lot vitality is consumed by learn entry from reminiscence vs. how a lot is consumed by addition and multiplication operations [source], the reminiscence entry operation is takes a few orders of magnitude extra vitality than computation operations. Since giant networks don’t slot in on-chip storage, there are much more vitality costly DRAM accesses.

When purposes like deep neural networks run on normal function processors, even small enhancements in efficiency by scaling come at enormous vitality consumption and gear prices.
General function processors like CPUs trade-off vitality effectivity for versatility and particular function processors (AI accelerators) commerce off versatility for vitality effectivity.
AI accelerators however will be designed with options to reduce reminiscence entry, provide bigger on-chip cache and embody devoted {hardware} options to speed up matrix-matrix computations. Since AI accelerators are function constructed units it’s “conscious” of the algorithms that it runs on and its devoted options will run it extra effectively than a normal function processor.
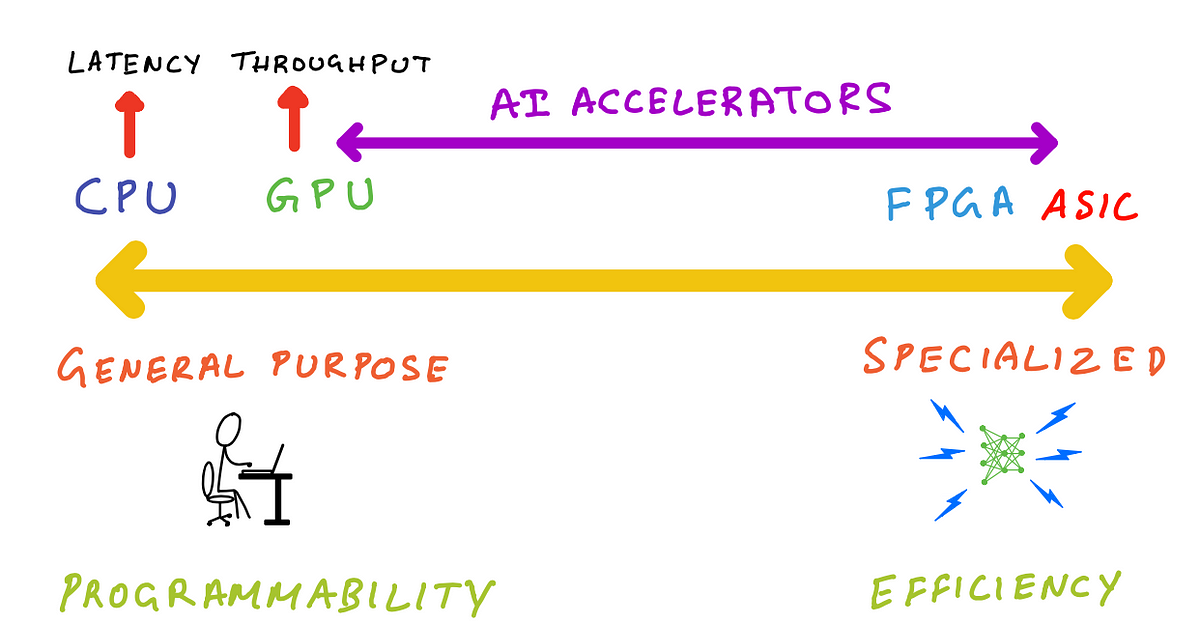
Let’s now check out various kinds of processors and the place they fall on a spectrum overlaying normal function and specialised processors.

One the left finish of the spectrum are CPUs, these are really normal function, as you possibly can run arbitrary code on them. You should utilize them to carry out any job {that a} devoted chip does from graphics, audio processing, machine studying and others. As mentioned earlier you’ll be giving up on efficiency and vitality effectivity.
On the opposite finish of the spectrum are Software Particular Built-in Circuits (ASICs). These are additionally known as fastened operate silicon, as a result of they exist to do only one or few issues, and are usually not usually programmable and don’t expose developer targeted APIs. An instance of that is the noise canceling processor in your headphones. It must be extremely vitality environment friendly to increase battery lifetime of your headphones, and simply highly effective sufficient to achieve the goal latency so that you don’t expertise delays or irritating out-of-sync points when utilizing them to look at your favourite TV present.
The left finish of the spectrum is about normal function and programmability, and the proper finish of the spectrum is about particular function and effectivity.
The place do processors like GPUs, FPGAs and AI accelerators fall on this spectrum?
Reply: Someplace between these two extremes.
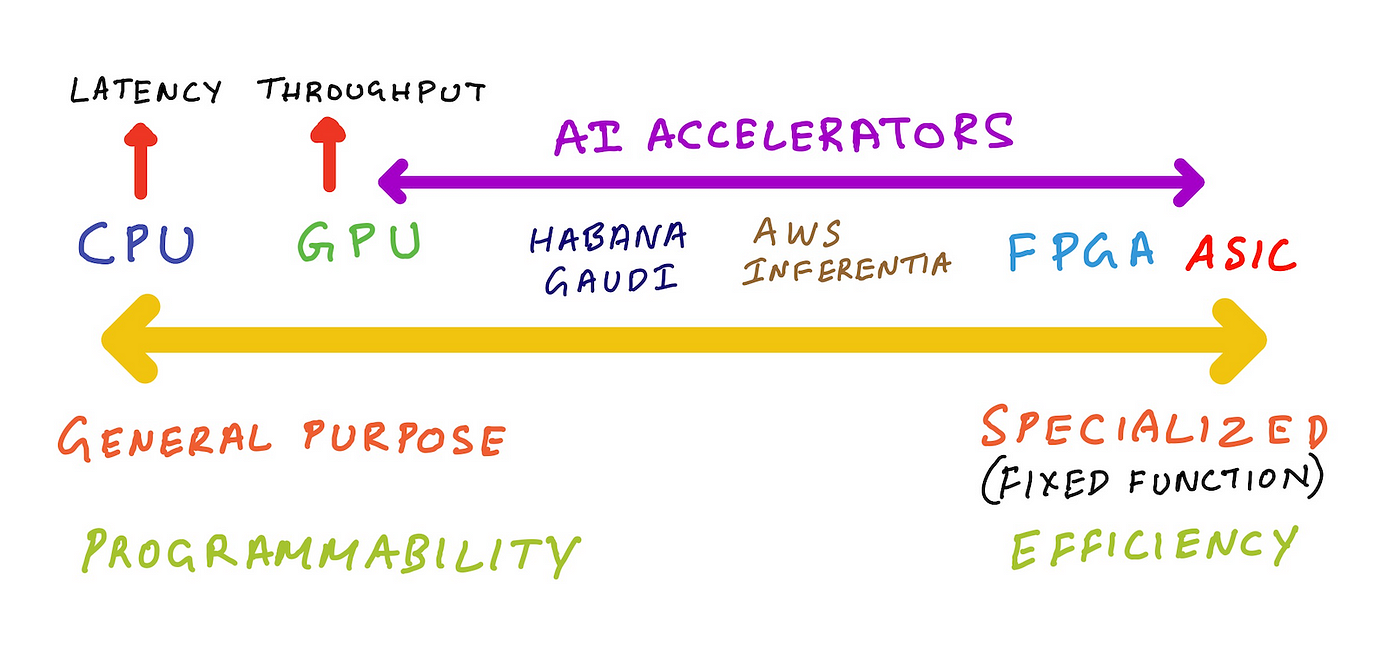
Nearer to the ASIC finish of the spectrum are Discipline Programmable Gate Arrays (FPGAs). As its identify implies it’s programmable, however you want {hardware} design expertise and information of a {hardware} description language (HDL) like verilog or VHDL. In different phrases, it’s too low-level and near the silicon that software program builders gained’t have the talents and instruments to program them.
To the proper of the CPU finish of the spectrum are GPUs. GPUs in contrast to CPUs are particular function processors that excel at parallel workloads like graphics shader computations and matrix multiplications. CPUs are higher fitted to latency sensitivity purposes, whereas GPUs are higher fitted to purposes that want high-throughput. GPUs are like CPUs within the sense that they’re programmable and utilizing languages like NVIDIA CUDA and OpenCL these parallel processors can run a smaller set of arbitrary features in comparison with a CPU, however actually excel at code that exploits parallelism.
AI accelerators resembling Intel Habana Gaudi, AWS Trainium and AWS Inferentia fall someplace to the proper of GPUs. Habana Gaudi gives programmability, however is much less versatile than a GPU so we will put it nearer to GPUs. AWS Inferentia shouldn’t be programmable, however gives a listing of supported operations it could speed up, in case your machine studying mannequin doesn’t assist these operations then AWS Inferentia implements CPU fall again mode for these operations. So, we will put AWS inferentia additional proper on that spectrum.
Now that we’ve a psychological mannequin for a way to consider various kinds of processors, let’s talk about how these processors work together with software program that runs on them.

The final function computing mannequin has two elements (1) software program and algorithms and (2) {hardware} processors that run the software program. For many components, these two are fairly unbiased within the sense that whenever you write software program you seldom take into consideration the place it’s operating. And when {hardware} options are designed, they’re designed to assist the widest vary of software program.

This mannequin begins to evolve for purposes like deep studying which calls for increased efficiency and vitality effectivity by bridging the hole between algorithm design and {hardware} design. The fashionable machine studying computing mannequin additionally contains two elements (1) machine studying algorithms and software program frameworks (2) a normal function processor paired with an AI accelerator.
In contrast to within the normal function computing mannequin, researchers develop machine studying algorithms that are “hardware-aware” i.e. the code they write reap the benefits of {hardware} particular options resembling a number of precision sorts (INT8, FP16, BF16, FP32), and goal particular silicon options (mixed-precision, structured sparsity). As a person you possibly can reap the benefits of these options by way of common machine studying software program frameworks. Equally, {hardware} designers construct AI accelerators which might be “algorithms-aware” i.e. they design devoted silicon options that that may speed up machine studying matrix computations (e.g. Tensor Cores).
This “hardware-algorithms consciousness” is feasible as a result of AI accelerator {hardware} and machine studying algorithms are co-evolving. {Hardware} designers are including options to AI accelerators which might be leveraged by machine studying algorithms, and machine studying researchers are creating new algorithms and approaches that may reap the benefits of particular options on the AI accelerator.
The {hardware} and software program work extra cohesively as a unit leading to increased efficiency and vitality effectivity.
AI accelerators fall into two classes — (1) AI accelerators for coaching (2) AI accelerators for inference. For the reason that objectives of coaching and inference are totally different and AI accelerators are devoted processors for specialised workloads, it is smart to design separate processors for every sort of workload.
The objective of the coaching accelerator is to scale back time to coach and coaching accelerators are designed with {hardware} options that coaching algorithms can reap the benefits of. This normally means coaching accelerators are increased powered processors, with extra reminiscence enabling increased throughput (knowledge processed per second). Since coaching accelerators are throughput targeted units, its vitality value/throughput will likely be decrease in case you maximize throughput or utilization. Coaching accelerators additionally embody assist for combined precision coaching utilizing devoted {hardware} options the place computation is carried out quicker in lower-precision and outcomes are gathered in high-precision, making them much more vitality environment friendly in comparison with normal function processors. We’ll talk about mixed-precision coaching in additional element within the AI accelerators for coaching part.
The objective of inference accelerators however is to scale back prediction latency for giant numbers of unbiased knowledge batches. An inference accelerator, subsequently, must be vitality environment friendly and have a low vitality value/prediction. You should utilize a coaching accelerator for inference (the ahead go of coaching is basically an inference job), nonetheless the vitality value/inference on a coaching accelerator will likely be a lot increased since will probably be beneath utilized for small batch inference requests.

A coaching accelerator is sort of a public transportation bus that’s solely vitality environment friendly if the bus is full on a regular basis in order that the fuel-cost/passenger is decrease. For those who use the bus to move only one particular person every journey the fuel-cost/passenger is increased. An inference accelerator however is sort of a sports activities coupe that’s quicker than a bus and extra vitality environment friendly than a bus for a single passenger (since much less fuel-cost/1 passenger is decrease). However if you wish to transport 50 folks in a sports activities coupe, it’ll be extremely inefficient and slower (to not point out unlawful).
Within the subsequent part we’ll take a more in-depth take a look at coaching and inference workflows individually. For every we’ll check out AI accelerators and software program options that ship the most effective efficiency and vitality effectivity for his or her job.
We all know that machine studying inference entails making use of a educated mannequin to new knowledge to get mannequin prediction outcomes. On this part we’ll talk about environment friendly algorithms that run on AI accelerators to make inference extra performant and vitality environment friendly.

Crucial {hardware} and software program trick that may make machine studying inference extra environment friendly is quantization. To totally admire quantization, we’ve to know quantity illustration in laptop {hardware}. Floating-point numbers in a digital laptop are discrete representations of steady actual valued numbers. Machine studying algorithms generally retailer and course of numbers which might be in single precision (FP32) based mostly on the IEEE 754 customary. IEEE 754 specifies extra floating-point sorts resembling half-precision (FP16) and double precision (FP64) sometimes supported in AI accelerators. Trendy AI accelerators additionally assist different non-IEEE 754 customary representations resembling bfloat16 (launched by Google Mind, supported by NVIDIA Ampere GPUs, AWS Inferential, AWS Tranium, Intel Habana Gaudi, Google TPUs) and TF32 (in NVIDIA Ampere structure and AWS Tranium accelerators). Inference accelerators additionally sometimes assist integer precisions resembling INT8 and INT4.
Advantages of quantization for inference
For inference duties, mannequin weights and activations will be quantized, i.e. transformed from FP32 (typical coaching precision) to lower-precision illustration resembling FP16, bfloat16 or INT8. Decrease-precision fashions means higher efficiency and vitality effectivity. Once you go from FP32 bit to FP16 operations, there’s 2 occasions knowledge dimension discount and about 4 occasions discount in vitality use and about 4 occasions discount within the silicon space for FP16 operations.
From an Inference-only {hardware} design perspective it is smart to construct smaller inference-only accelerators that solely assist decrease precision and are subsequently extra vitality environment friendly. Transferring from FP32 to INT8 outcomes will lead to even decrease vitality utilization attributable to 4 occasions knowledge dimension discount.
This enormous efficiency effectivity achieve usually comes at the price of mannequin prediction accuracy. Transferring to lower-precision illustration is a kind of compression, which suggests you’ll lose some knowledge whenever you quantize. FP32 has a big dynamic vary proven beneath, in comparison with FP16 and INT8. Subsequently the objective of quantization for inference is to retain solely the “sign” when quantizing to decrease precision and throw out the “noise” and there are a number of methods of doing this.
Quantization with NVIDIA GPUs
Newer era of NVIDIA GPUs based mostly on the NVIDIA Ampere and NVIDIA Turing structure assist a variety of precision sorts only for inference. Whereas FP16 precision sort was first launched in NVIDIA Pascal structure manner again in 2016, the newest NVIDIA Ampere and Turing based mostly GPU are examples of true “hardware-algorithm co-evolution”. I’ve mentioned the entire historical past of GPUs, GPU structure and their options in my weblog put up:
On this part I’ll give attention to each {hardware} and software program assist for quantization on GPUs.
Let’s take the instance of NVIDIA Ampere GPU structure. On AWS you possibly can entry Ampere based mostly NVIDIA A100 by launching the p4d Amazon EC2 occasion and NVIDIA A10G by launching GPUs from the G5 occasion sort. Each these NVIDIA Ampere based mostly GPUs assist FP64, FP32, FP16, INT8, BF16, TF32 precision sorts and likewise embody devoted silicon for mixed-precision arithmetic that NVIDIA calls Tensor Cores. For inference, the precision sorts that we solely care about are FP16 and INT8, and we’ll revisit the opposite precision sorts once we talk about coaching within the subsequent part.
Since most deep studying frameworks practice fashions in FP32 on NVIDIA GPUs, to run inference extra effectively NVIDIA supplies TensorRT, a compiler that may quantize mannequin weights and activations to FP16 or INT8. To carry out quantization, TensorRT will decide a scaling issue to map the FP32 tensor’s dynamic vary to FP16 or INT8’s dynamic vary. This may be significantly difficult for INT8 as a result of its dynamic vary is dramatically smaller than FP32’s dynamic vary. INT8 can solely symbolize 256 totally different values whereas FP32 can symbolize roughly a whooping 4.2 x 10⁹ values!
The ML analysis and {hardware} group has provide you with two approaches to reap the benefits of quantization with out dropping accuracy:
- Publish-training quantization (PTQ): You begin with a educated mannequin in FP32 and derive scaling elements to map FP32 -> INT8. TensorRT does this by measuring the distribution of activations for every layer and discovering a scaling issue that minimizes data loss (KL divergence) between reference distribution and the quantized distribution.
- Quantization-aware coaching (QAT): You compute the size elements throughout coaching, permitting the mannequin to adapt and decrease data loss.
Let’s take a second to understand this dynamic between {hardware} and algorithms. We will see that the {hardware} has developed to supply extra environment friendly silicon options like lowered precision, now algorithms must evolve to reap the benefits of the silicon options!
For code examples on how quantization works with NVIDIA TensorRT on GPUs learn my weblog put up:
Quantization with AWS Inferentia
Whereas NVIDIA GPUs have been initially created to speed up graphics and are evolving to turn into highly effective AI accelerators, AWS Inferentia was created with the one function of accelerating machine studying inference. Every AWS Inferentia chip has 4 NeuronCores, and every NeuronCore is a systolic-array matrix-multiply engine with two stage reminiscence hierarchy and a really giant on-chip cache. It helps FP16, BF16 and INT8 knowledge sorts and doesn’t assist increased precision codecs since you don’t want it for inference — it’s in spite of everything a specialised processor. Identical to NVIDIA’s TensorRT compiler for GPUs, AWS Neuron SDK and Compiler that helps quantization and optimization for environment friendly inference.
On the time of this writing, regardless that AWS Inferentia {hardware} helps INT8, AWS Neuron compiler solely helps FP16 and bfloat16 as quantization targets. A mannequin that’s educated in FP32 will mechanically be transformed to bfloat16 throughout the compilation course of. For those who quantize the weights manually from FP32 to FP16 earlier than you employ the AWS Neuron compiler, then it’ll retain the FP16 precision for inference.
In comparison with GPUs, AWS Inferentia accelerators are usually not programmable and subsequently falls to the proper of GPUs nearer to ASICs within the {hardware} spectrum we mentioned earlier. If the mannequin has operations which might be totally supported by AWS Inferentia, it may be extra vitality environment friendly than GPUs for a mix of particular fashions and batch dimension. Nonetheless, if the mannequin has operations that aren’t supported, AWS Neuron compiler will mechanically place these operations on the host CPU. This sadly leads to extra knowledge motion between CPU and the accelerator decreasing its efficiency and effectivity.
Machine studying coaching entails optimizing parameters of a mannequin to enhance mannequin’s prediction accuracy utilizing coaching knowledge. On this part we’ll talk about environment friendly algorithms that run on AI accelerators to make inference extra performant and vitality environment friendly.
Let’s revisit precision, however this time for coaching workflows. As we mentioned earlier throughout coaching weights and activations are saved in FP32 illustration which is an IEEE 754 floating-point customary which predates deep studying. ML researchers selected this because the default floating-point illustration as a result of throughout coaching FP16 couldn’t maintain sufficient data and FP64 was too giant and we don’t really need all that magnitude and precision. What they wanted was one thing in-between however there was no such factor in {hardware} that was obtainable at the moment.
In different phrases, the present {hardware} was not conscious of algorithm wants or “algorithm-aware” as we mentioned earlier.
If ML researchers had the power to decide on any floating-point illustration that labored nice for machine studying, then they might select a illustration that may look totally different from FP32 or use a mix of precision to enhance efficiency and effectivity. That is exactly the path AI accelerators took with mixed-precision coaching and it required co-design of {hardware} and algorithms to make it work.
Blended-precision coaching to enhance efficiency and effectivity
Matrix multiplication operations are the bread and butter of neural community coaching and inference and an AI accelerator spends most of its time multiplying giant matrices of enter knowledge and weights in numerous layers. The concept behind mixed-precision coaching is that matrix-multiplication throughout coaching occurs in lower-precision illustration (FP16, bfloat16, TF32) in order that they’re quicker and extra vitality environment friendly and outcomes are gathered in FP32 to reduce data loss, making the coaching extra environment friendly and quicker.
Blended-precision coaching with NVIDIA GPUs
In 2017 NVIDIA introduced Volta structure which featured devoted machine studying particular options in its silicon known as NVIDIA Tensor Cores. Tensor Cores enabled mixed-precision coaching utilizing FP16 math with FP32 accumulation. Newer generations of NVIDIA GPU architectures have prolonged assist past FP16 to different lowered precision codecs (bfloat16, TF32). On the silicon stage, Tensor Core performs reduced-precision fused multiply-add (FMA) with FP32 accumulation.
NVIDIA structure enhancements over every era is a good instance of hardware-algorithm co-design and co-evolution.
- NVIDIA Volta structure (2017) launched first era of Tensor Cores that solely supported FP16 math and FP32 accumulate for mixed-precision
- NVIDIA Turing (2018) prolonged Tensor Cores to assist INT8 and INT4 reduced-precisions (which primarily advantages inference, not coaching)
- NVIDIA Ampere (2020) prolonged Tensor Cores to assist bfloat16, TF32, which suggests it could carry out FP16, bfloat16 or TF32 math and accumulate in FP32 for mixed-precision
One of many challenges with mixed-precision coaching is that from a software program perspective it didn’t “simply work”. The person needed to carry out extra steps throughout coaching, resembling casting weights to FP16 knowledge sorts when doable, but in addition maintaining a duplicate of the FP32 weights and loss scaling. Whereas NVIDIA enabled deep studying frameworks to do these steps beneath the hood with minimal code modifications, it’s conceptually demanding from an finish person and never as easy as coaching in FP32.
With NVIDIA Ampere the {hardware} has developed to assist the brand new TF32 format that considerably addresses this person expertise downside. What’s thrilling about TF32 is that it has the vary of FP32 and the precision of FP16, which suggests deep studying frameworks can assist it out of the field with no need to carry out extra steps like casting and bookkeeping. Whereas TF32 delivers improved efficiency over FP32 with no developer overhead, NVIDIA nonetheless recommends utilizing FP16 or bfloat16 based mostly mixed-precision coaching for the quickest coaching efficiency.
Blended-precision coaching with different AI accelerators
Intel Habana Gaudi
Habana Gaudi accelerators assist mixed-precision in an analogous manner that NVIDIA helps it — with the assistance of a further device that you should utilize with the deep studying framework that may carry out casting and book-keeping for you. On AWS you possibly can entry Intel Habana Gaudi AI accelerators by launching Amazon EC2 DL1 situations which provides you with entry to eight x Gaudi accelerators.
AWS Tranium
AWS introduced AWS Tranium at re:invent 2021, an AI accelerator that was constructed by AWS’s Annapurna labs. On the time of this writing AWS Tranium shouldn’t be but typically obtainable. In this announcement speak AWS shared that AWS Tranium at launch will assist FP16, TF32, bfloat16, INT8 and an thrilling new format known as cFP8 which stands for customized 8-bit floating level will be personalized.
We’re dwelling in thrilling occasions for each machine studying algorithm analysis and machine studying {hardware} design. AI accelerators will proceed to evolve to ship higher-performance, higher vitality effectivity and turn into as seamless to make use of as normal function processors.
Trendy AI accelerators already embody anticipatory {hardware} options resembling assist INT1 and INT4 precision sorts which aren’t used for coaching or inference duties right this moment, however might sometime allow new machine studying algorithms. Networking for AI accelerators is one other essential space that’s seeing a metamorphosis. As mannequin sizes proceed to develop we’ll want bigger computing clusters with many AI accelerators linked to one another to assist bigger workloads. NVIDIA gives high-bandwidth inter-GPU interconnect with NVLink and NVSwitch and Intel Habana Gaudi has built-in on-chip and Ethernet-based RoCE RDMA. AI accelerators are right here to remain and can turn into a staple in trendy computing environments as increasingly purposes combine AI based mostly options.
An space I count on to see extra progress is person/developer expertise. Right now’s heterogeneous computing mannequin which entails working with a number of CPUs, AI accelerators and their networking and storage setups are very difficult for many knowledge scientists and builders. Whereas managed providers within the cloud like Amazon SageMaker removes all the necessity to handle infrastructure making it simple to scale machine studying, open-source frameworks nonetheless count on the person to be educated about underlying {hardware}, precision sorts, compiler choices, and networking primitives and so on.
Sooner or later, a developer will log right into a distant IDE and run code utilizing an open-source machine studying framework, and gained’t give a second thought to the place and the way it’s operating. They may solely specify value vs. velocity trade-offs — quicker outcomes value extra, slower outcomes saves value — that will likely be their solely cognitive burden. I’m an optimistic particular person and I believe we’re shut.
For those who discovered this text fascinating, take into account giving this an applause and following me on medium. Please additionally try my different weblog posts on medium or comply with me on twitter (@shshnkp), LinkedIn or go away a remark beneath. Need me to jot down on a selected machine studying matter? I’d love to listen to from you!

{kind=link}