
We’re witnessing the AI revolution. To be able to make good selections, the units outfitted with AI want tons and plenty of information. And making sense of that information wants energy and velocity. That is the place AI accelerators come into the image.
As IoT techniques are getting increasingly more environment friendly, information acquisition is getting simpler. This has elevated the demand for AI and ML purposes in all good techniques. AI based mostly duties are data-intensive, power-hungry, and name for increased speeds. Due to this fact, devoted {hardware} techniques referred to as AI accelerators are used to course of AI workloads in a sooner and extra environment friendly method.
Co-processors like graphics processing models (GPUs) and digital sign processors (DSPs) are frequent in computing techniques. Even Intel’s 8086 microprocessor will be interfaced with a math co-processor, 8087. These are task-driven additions that had been launched as a result of CPUs alone can’t carry out their capabilities. Equally, CPUs alone can’t effectively care for deep studying and synthetic intelligence workloads. Therefore, AI accelerators are adopted in such purposes. Their designs revolve round multi-core processing, enabling parallel processing that’s a lot sooner than the standard computing techniques.

On the coronary heart of ML is the multiply-accumulate (MAC) operation. Deep studying is primarily composed of numerous such operations. And these must occur parallelly. AI accelerators have the capability to considerably scale back the time it takes to carry out these MAC operations in addition to to coach and execute AI fashions. In actual fact, Intel’s head of structure, Raja Koduri, famous that sooner or later each chip can be a neural internet processor. This yr, Intel plans to launch its Ponte Vecchio HPC graphics card (accelerator), which, Intel claims, goes to be a game-changer on this area.

Consumer-to-hardware expressiveness
‘Consumer-to-hardware expressiveness’ is a time period coined by Adi Fuchs, an AI acceleration architect in a world-leading AI platforms startup. Beforehand, he has labored at Apple, Mellanox (now NVIDIA), and Philips. Based on Fuchs, we’re nonetheless unable to routinely get the most effective out of our {hardware} for a model new AI mannequin with none handbook tweaking of the compiler or software program stack. This implies we’ve got not but successfully reached an inexpensive user-to-hardware expressiveness.

It’s shocking how even slight familiarity with processor structure and the {hardware} counterpart of AI will help in bettering the efficiency of our coaching fashions. It will possibly assist us perceive the varied bottlenecks that may trigger the efficiency of our fashions to lower. By understanding processors, and AI accelerators specifically, we will bridge the hole between writing code and having it carried out on the {hardware}.

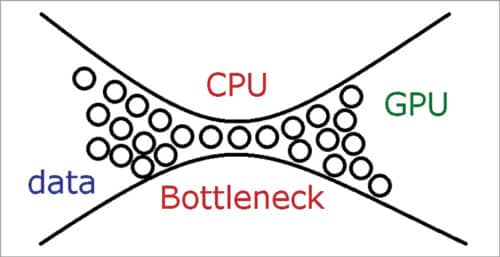
Bottleneck in AI processing
As we add a number of cores and accelerators to our computing engines to spice up efficiency, we should remember that every of them has a unique velocity. When all these processors work collectively, the slowest one creates a bottleneck. For those who use your PC for gaming, you’d most likely have skilled this drawback. It doesn’t matter how briskly your GPU is that if your CPU is sluggish.
Equally, it might not matter how briskly {hardware} accelerators are if the learn/write information switch is sluggish between RAM storage and the processor. Therefore, it’s essential for designers to pick the best {hardware} for all parts to be in sync.
 Well-liked AI accelerator architectures
Well-liked AI accelerator architectures
Listed below are some widespread AI architectures:
Graphics processing unit (GPU)
Nicely, GPUs weren’t initially designed for ML and AI. When AI and deep studying had been gaining reputation, GPUs had been already out there and had been used as specialised processors for laptop graphics. Now we’ve got programmable ones too, referred to as general-purpose GPU (GPGPU). Their means to deal with laptop graphics and picture processing makes them a sensible choice for utilization as an AI accelerator. In actual fact, GPU producers are actually modifying their architectures to be used in AI or ML.

In 2012, Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton from the College of Toronto introduced a paper on AlexNet, a deep neural community. It was skilled on available, programmable shopper GPUs by NVIDIA (NVIDIA GTX 580 3GB GPU). It’s mainly a GPU implementation of a CNN (convolutional neural community). AlexNet received the 2012 ImageNet Giant Scale Visible Recognition Problem (ILSVRC).
FPGAs and ASICs. FPGAs are semiconductor units that, because the title suggests, are area programmable. Their inner circuitry is just not mapped if you purchase them; you must program them proper on the sphere utilizing {hardware} description languages (HDLs) like VHDL and Verilog. Which means that your code is transformed right into a circuit that’s particular to your software. The truth that they are often customised provides them a pure benefit over GPUs.
Xilinx and an AI startup referred to as Mipsology are working collectively to allow FPGAs to exchange GPUs in AI accelerator purposes, simply utilizing a single command. Mipsology’s software program Zebra converts GPU code to run on Mipsology’s AI compute engine on an FPGA, with none code modifications.

FPGAs are cheaper, reprogrammable, and use much less energy to perform the identical work. Nevertheless, this comes at the price of velocity. ASICs, then again, can obtain increased speeds and devour low energy. Furthermore, if ASICs are to be manufactured in bulk, the prices aren’t that prime. However they can’t be reprogrammed on the sphere.
Tensor processing unit (TPU). Tensor processing unit is an AI accelerator constructed by Google particularly for neural community machine studying. Initially, it was utilized by Google solely, however since 2018, Google has made it out there for third-party use. It helps TensorFlow code and permits you to run your personal applications on the TPU on Google Cloud. The documentation supplied by Google is complete and consists of a number of person guides. The TPU is particularly designed for vector-by-matrix multiplication, an operation that occurs a number of instances in any ML software.
 On-edge computing and AI
On-edge computing and AI
On-edge computing provides an engine the facility to compute or course of regionally with low latency. This results in sooner decision-making on account of sooner response time. Nevertheless, the most important benefit could be the flexibility to ship simply the processed information to the cloud. Therefore, with edge computing, we’ll now not be as depending on the cloud as we’re at the moment. Which means that lesser cloud space for storing is required, and therefore decrease vitality utilization and decrease prices.

The ability consumed by AI and ML purposes isn’t any joke. So, deploying AI or machine studying on edge has disadvantages by way of efficiency and vitality that will outweigh the advantages. With the assistance of on-edge AI accelerators, builders can leverage the pliability of edge computing, mitigate privateness considerations, and deploy their AI purposes on edge.
Boards that use AI accelerator
As increasingly more corporations make a mark within the area of AI accelerators, we’ll slowly witness a seamless integration of AI into IoT on edge. Corporations like NVIDIA are, in truth, identified for his or her GPU accelerators. Given under are just a few examples of boards that characteristic AI accelerators or had been created particularly for AI purposes.
Google’s Coral Dev Board. Google’s Coral Dev Board is a single-board laptop (SBC) that includes an edge TPU. As talked about earlier than, TPUs are a sort of AI accelerator developed by Google. The sting TPU within the Coral Dev Board is accountable for offering high-performance ML inferencing with a low energy value.
The Coral Dev Board helps TensorFlow Lite and AutoML Imaginative and prescient Edge. It’s appropriate for prototyping IoT purposes that require ML on edge. After profitable prototype growth, you’ll be able to even scale it to manufacturing degree utilizing the onboard Coral system-on-module (SoM) mixed along with your customized PCB. Coral Dev Board Mini is Coral Dev Board’s successor with a smaller type issue and lower cost.
BG24/MG24 SoCs from Silicon Labs. In January 2022, Silicon Labs introduced the BG24 and MG24 households of two.4GHz wi-fi SoCs with built-in AI accelerators and a brand new software program toolkit. This new co-optimised {hardware} and software program platform will assist deliver AI/ML purposes and wi-fi excessive efficiency to battery-powered edge units. These units have a devoted safety core referred to as Safe Vault, which makes them appropriate for data-sensitive IoT purposes.

The accelerator is designed to deal with complicated calculations shortly and effectively. And since the ML calculations are occurring on the native gadget relatively than within the cloud, community latency is eradicated. This additionally signifies that the CPU needn’t do this form of processing, which, in flip, saves energy. Its software program toolkit helps among the hottest device suites like TensorFlow.
“The BG24 and MG24 wi-fi SoCs signify an superior mixture of business capabilities, together with broad wi-fi multiprotocol assist, battery life, machine studying, and safety for IoT edge purposes,” says Matt Johnson, CEO of Silicon Labs. These SoCs can be out there for buy within the second half of 2022.
MAX78000 Growth Board by Maxim Built-in. The MAX78000 is an AI microcontroller constructed to allow neural networks to execute at ultra-low energy. It has a {hardware} based mostly convolutional neural community (CNN) accelerator, which permits battery-powered purposes to execute AI inferences.
Its CNN engine has a weight storage reminiscence of 442kB and may assist 1-, 2-, 4-, and 8-bit weights. Being SRAM based mostly, the CNN reminiscence permits AI community updates to occur on the fly. The CNN structure could be very versatile, permitting networks to be skilled in standard toolsets like PyTorch and TensorFlow.
Kria KV260 Imaginative and prescient AI Starter Equipment by Xilinx. It is a growth platform for Xilinx’s K26 system on module (SOM), which particularly targets imaginative and prescient AI purposes in good cities and good factories. These SOMs are tailor-made to allow fast deployment in edge based mostly purposes.
As a result of it’s based mostly on an FPGA, the programmable logic permits customers to implement customized accelerators for imaginative and prescient and ML capabilities. “With Kria, our preliminary focus was Imaginative and prescient AI in good cities and, to some extent, in medical purposes. One of many issues that we’re centered on now and transferring ahead is increasing into robotics and different manufacturing unit purposes,” says Chetan Khona, Director of Industrial, Imaginative and prescient, Healthcare & Sciences markets at Xilinx.
Gluon AI co-processor by AlphaICs. The Gluon AI accelerator is optimised for imaginative and prescient purposes and supplies most throughput with minimal latency and low energy. It comes with an SDK that ensures straightforward deployment of neural networks.
AlphaICs is at present sampling this accelerator for early clients. It’s engineered for OEMs and answer suppliers focusing on imaginative and prescient market segments, equivalent to surveillance, industrial, retail, industrial IoT, and edge gateway producers. The corporate additionally presents an analysis board that can be utilized to prototype and develop AI {hardware}.

Intel’s Neural Compute Stick 2 (Intel NCS2). Intel’s NCS2 appears like a USB pen drive however really brings AI and laptop imaginative and prescient to edge units in a very simple method. It comprises a devoted {hardware} accelerator for deep neural community interfaces and is constructed on the Movidius Myriad X Imaginative and prescient processing unit (VPU).
Aside from utilizing the NCS2 for his or her PC purposes, designers may even use it with edge units like Raspberry Pi 3. This can make prototyping very straightforward and can improve purposes like drones, good cameras, and robots. Organising and configuring its software program atmosphere is just not complicated, and detailed tutorials and directions on varied tasks are supplied by Intel.
An extended method to go
The sphere of AI accelerators remains to be area of interest, and there may be nonetheless a variety of room for innovation. “Many nice concepts had been carried out up to now 5 years, however even these are a fraction of the staggering variety of AI accelerator designs and concepts in tutorial papers. There are nonetheless many concepts that may trickle-down from the educational world to business practitioners,” says Fuchs.
The creator, Aaryaa Padhyegurjar, is an Business 4.0 fanatic with a eager curiosity in innovation and analysis

{kind=link}