
What our experiments discovered and your probability to attempt the mannequin out

Introduction
Can you are taking a common ML mannequin for sentiment evaluation, adapt it to a particular area, and give you acceptable outcomes? How a lot of a problem is that?
Because it seems, it’s doable with affordable effort. The ML group at Toloka lately tweaked a common sentiment mannequin to the monetary area, and I’m excited to share the outcomes of our experiments.
You’ll be able to attempt the fine-tuned sentiment evaluation mannequin right here or hold studying for extra particulars.
Baseline mannequin
The baseline mannequin we used is a RoBERTa-based classifier described in this paper.
It’s a common pure language processing mannequin that performs a easy sentiment evaluation activity. It types English texts into three lessons:
- Optimistic sentiment

- Impartial sentiment

- Damaging sentiment

This deep studying mannequin was comparatively good at recognizing the sentiment of brief, tweet-like texts just like what it was educated on, however that aptitude dropped off a cliff after we checked its efficiency within the monetary area. It was the right alternative for the ML group to adapt the mannequin to a particular space.
High-quality-tuned mannequin
We used the FinancialPhraseBank dataset. It consists of 4840 English sentences from monetary information categorized by sentiment. As soon as once more, we had three lessons:
- Optimistic sentiment
- Impartial sentiment
- Damaging sentiment
In our experiment we solely tuned the classification head utilizing a studying price of 1e-2, operating it for 5 epochs, and utilizing solely half of the information. Tuning solely the pinnacle (freezing the remainder of the weights) is an uncommon technique to practice deep studying fashions. This method is often utilized in CV and considerably reduces coaching complexity. It may be carried out on smaller GPUs, however the process doesn’t work on a regular basis — for a few of the duties it might be inadequate. Fortunately in our case, the mannequin educated that approach gave us spectacular outcomes on the check set and we determined to judge it utilizing a special set of monetary information.
Analysis Knowledge set
The dataset we used to judge each sentiment evaluation fashions is from Kaggle and will be downloaded right here. It’s a lengthy listing of monetary headlines annotated with a sentiment relative to the monetary entities in them. You’ll be able to see the primary few strains of this beneath.

As a result of our sentiment evaluation mannequin isn’t aspect-based, we needed to preprocess the dataset earlier than we might consider it. We determined to sentiment-label every title like this:
- If all entities talked about within the headline have the identical sentiment, we are able to assume that’s the sentiment for the entire headline
- If entities have combined sentiments, we take away them from the dataset
That resulted in a novel general sentiment for every headline as seen beneath.

We solely used 1000 entries, assuming that was sufficient for dependable analysis. You’ll be able to test this colab pocket book to seek out the code we used within the experiment and extra particulars on how we did carry out sentiment evaluation for every mannequin.
Sentiment evaluation outcomes
After we have now gathered sentiment evaluation predictions for each our machine studying fashions we might have constructed a good comparability between them by taking a look at accuracy, precision, recall, and f-score. We printed classification studies for each fashions utilizing the scikit-learn library.
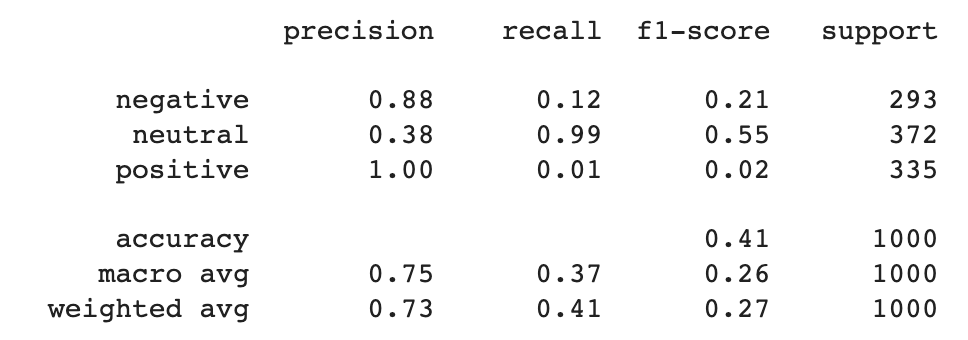

From the photographs above, you’ll be able to see that the fine-tuned model outperformed the baseline in all common metrics:
- Precision went from 0.73 to 0.77
- Recall went from 0.41 to 0.76
- F-score went from 0.27 to 0.77
The person outcomes present that the recall of optimistic and adverse lessons for the baseline mannequin was very low: 0.01 and 0.12, respectively. High-quality-tuning the brand new mannequin drove a recall of 0.71 for the optimistic class and 0.78 for the adverse class.
This excessive enchancment in recall, on this case, is an impact of area tuning. The baseline mannequin didn’t encounter in its coaching the monetary phrases current within the analysis information set and this is the reason it struggled with discovering optimistic and adverse phrases on this context. It definitively modified after the mannequin was tailored and uncovered to in-domain coaching information and resulted in a lift of a recall for optimistic and adverse lessons.
Recall for the impartial class, nevertheless, dropped from 0.99 to 0.8. Precision for adverse and optimistic fell barely as nicely. These are metrics we’d like to remember, although the excessive baseline scores have been attributable to the mannequin overpredicting the impartial class.
Confusion matrices illustrate the scenario.

A more in-depth look reveals the issues the baseline mannequin had labeling optimistic and adverse sentiments. It mislabeled optimistic headlines as impartial 331 occasions. Equally, the adverse class was mislabeled as impartial 258 occasions. That may be very poor efficiency on lessons that ought to be reliably detected in such sentiment classification duties.
The fine-tuned mannequin mounted that downside and gave us extra appropriate predictions. The optimistic class was solely mislabeled as impartial 85 occasions, whereas the adverse class was mislabeled as impartial 56 occasions. That is once more due to adapting the mannequin and the truth that throughout discover tuning it discovered what are optimistic and adverse indicators in monetary texts.
Abstract
Toloka ML group has proved {that a} sentiment mannequin educated on a special area will be fine-tuned to a brand new area making a customized sentiment evaluation mannequin with relative ease and never a lot information.
Our baseline mannequin was educated to detect sentiment for social media posts, making it susceptible to errors within the monetary area. However fine-tuning the mannequin within the monetary area, even with a totally completely different monetary dataset, improved the outcomes considerably.
You’ll be able to learn by the code for the experiment in this colab pocket book.
You’re additionally welcome to mess around with the fine-tuned mannequin and tell us what you concentrate on it within the feedback beneath.
PS: I’m writing articles that designate primary Knowledge Science ideas in a easy and understandable method on Medium and aboutdatablog.com. You’ll be able to subscribe to my e mail listing to get notified each time I write a brand new article. And in case you are not a Medium member but you’ll be able to be a part of right here.
Beneath there are another posts you might take pleasure in:

{kind=link}