An end-to-end instance of constructing a scalable and clever search engine on the cloud with the MovieLens dataset
· 1. Introduction
· 2. Dataset Preparation
· 3. Organising the OpenSearch
· 4. Index knowledge
· 5. Fundamental Question with Match
· 6. Fundamental Entrance-end Implementation with Jupyter Pocket book and ipywidgets
· 7. Some Superior Queries
∘ 7.1 Match Phrase Prefix
∘ 7.2 Match + Prefix with Boolean
∘ 7.3 Multi-field Search
· 8. Conclusion
· About Me
· References
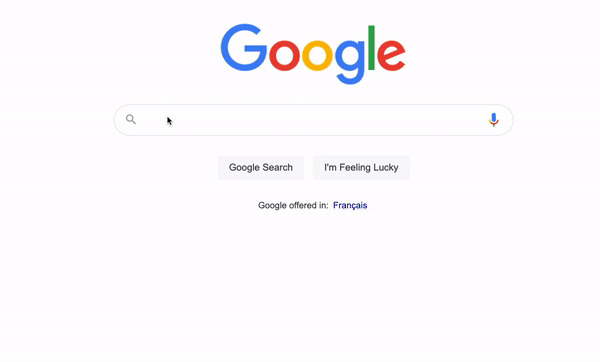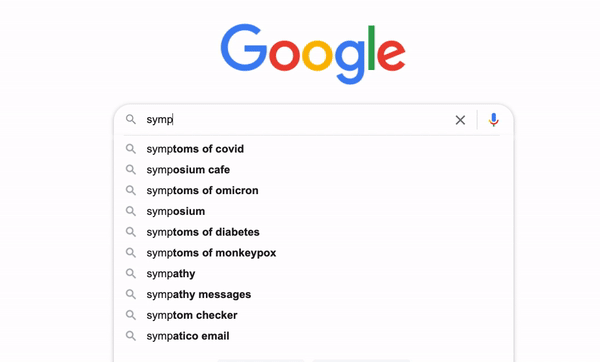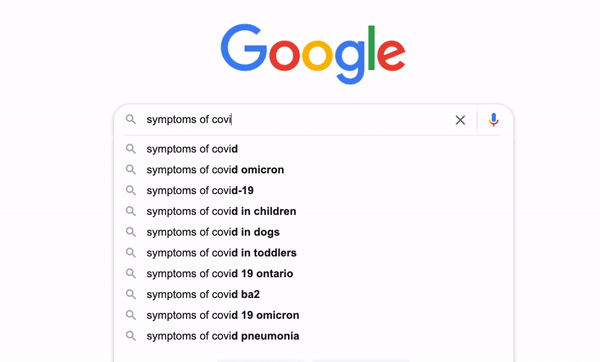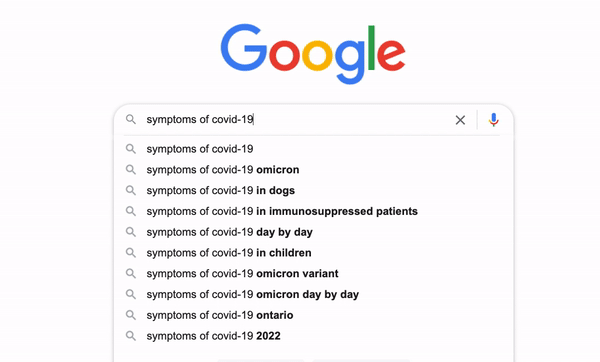
Have you ever ever considered how Google makes its search engine so clever that it may well predict what we expect and autocomplete the entire search time period even with out us typing the entire thing? It’s known as typeahead search. It’s a very helpful language prediction software that many search interfaces use to supply strategies for customers as they kind in a question. [1]
As an information scientist or anybody who works on the backend of the info, typically we might want such an interactive search engine interface for our customers to question structured/unstructured knowledge with minimal effort. This will at all times carry the person expertise to the subsequent degree.
Fortunately, we don’t need to construct it from scratch. There are numerous open-source instruments prepared for use, and one among them is Elasticsearch.
Elasticsearch is a distributed, free and open search and analytics engine for every type of information, together with textual, numerical, geospatial, structured, and unstructured. Identified for its easy REST APIs, distributed nature, pace, and scalability, Elasticsearch is the central element of the Elastic Stack, a set of free and open instruments for knowledge ingestion, enrichment, storage, evaluation, and visualization. [2]
However, AWS OpenSearch, created by Amazon, is a forked model of Elasticsearch match into its AWS ecosystem. It has a really comparable interface with underlying constructions with Elasticsearch. On this publish, to simplify the method of downloading, putting in, and establishing Ealsticsearch in your native machine, I’ll as an alternative stroll you thru an end-to-end instance of indexing and querying knowledge utilizing AWS Open Search.
In the actual world, one other nice purpose to make use of such cloud providers is scalability. We will simply modify the sources we have to accommodate any knowledge complexity.
Please keep in mind that despite the fact that we use AWS OpenSearch right here, you’ll be able to nonetheless observe the steps in Elasticsearch if you have already got it arrange. These instruments are very comparable in nature.
On this instance, we’re going to use the MovieLens 20M Dataset, which is a well-liked open film dataset utilized by many knowledge professionals in numerous tasks. It’s known as 20M as a result of there are 20 million scores included within the dataset. As well as, there are 465,000 tag functions, 27,000 motion pictures, and 138,000 customers included in the entire dataset.
This dataset incorporates a number of recordsdata and can be utilized for very complicated examples, however assuming we solely wish to construct a film search engine right here that may question film titles, years, and genres, we solely want one file motion pictures.csv.
It is a very clear dataset. The construction is proven beneath:
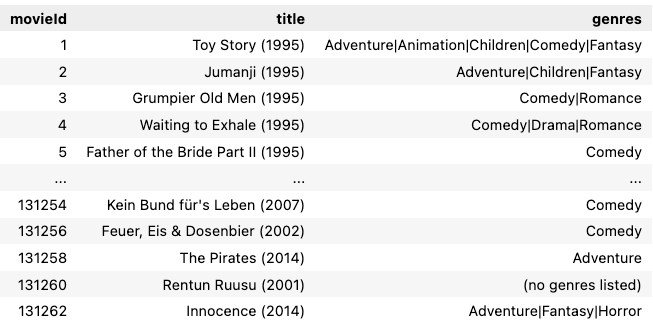
There are solely 3 fields: movieId, title (with years in parenthesis), and genres (separated by |). We’re going to index the dataset utilizing title and genres, however it seems like there are motion pictures with out genres specified (eg, movieId = 131260), so we could wish to substitute these genres as NA, to forestall them from being queried as undesirable style key phrases. A number of strains of processing ought to suffice:
import pandas as pd
import numpy as npdf = pd.read_csv('../knowledge/motion pictures.csv')
df['genres'] = df['genres'].substitute('(no genres listed)', np.NaN)
df.to_csv('../knowledge/movies_clean.csv', index=False)
With this tremendous quick chunk of code, now we have simply cleaned up the dataset and saved it as a brand new file known as movie_clean.csv . Now we will go forward and spin up an AWS OpenSearch area.
Right here is the official documentation from AWS OpenSearch. You’ll be able to observe it for a extra detailed introduction, or you’ll be able to learn by way of the simplified model I made beneath.
When you don’t have an AWS account, you’ll be able to observe this hyperlink to join AWS. You additionally want so as to add a cost technique for AWS providers. Nevertheless don’t panic but, as on this tutorial, we’ll use the minimal sources and the associated fee needs to be not more than $1.

After your account is created, merely log into your AWS administration console, and seek for the OpenSearch service, or click on right here to enter the OpenSearch dashboard.
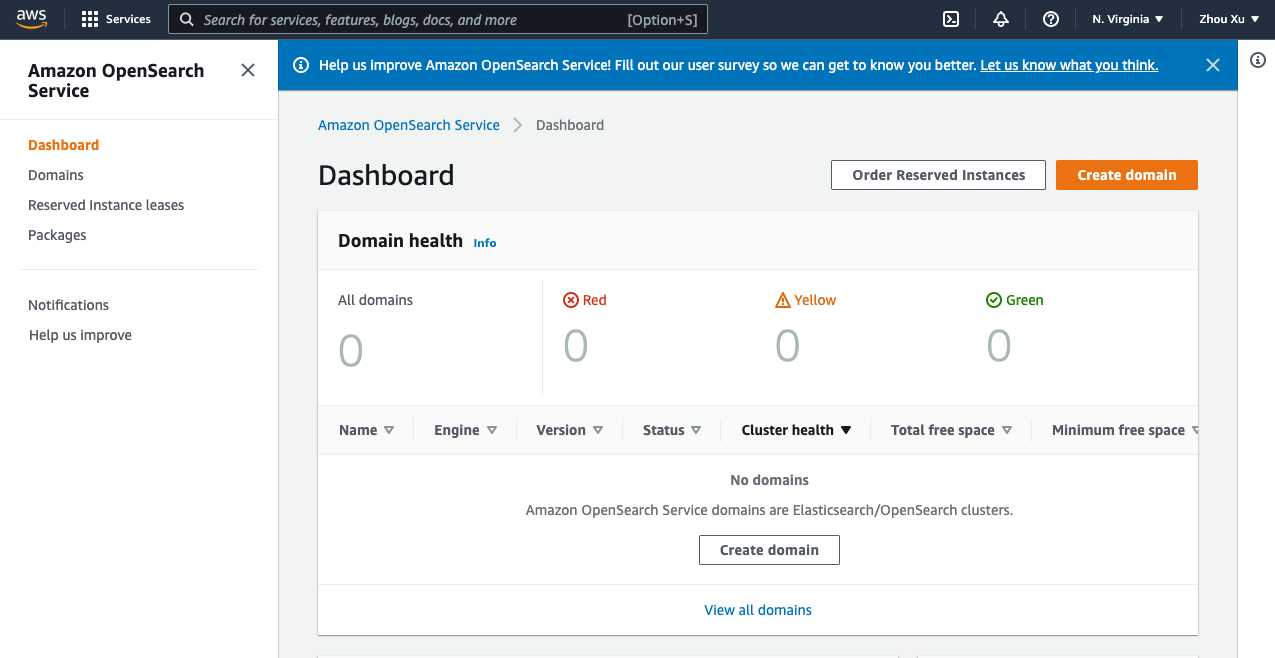
Within the dashboard, observe the steps beneath:
- Select Create area.
- Give a Area title.
- In Growth kind, choose Growth and testing.
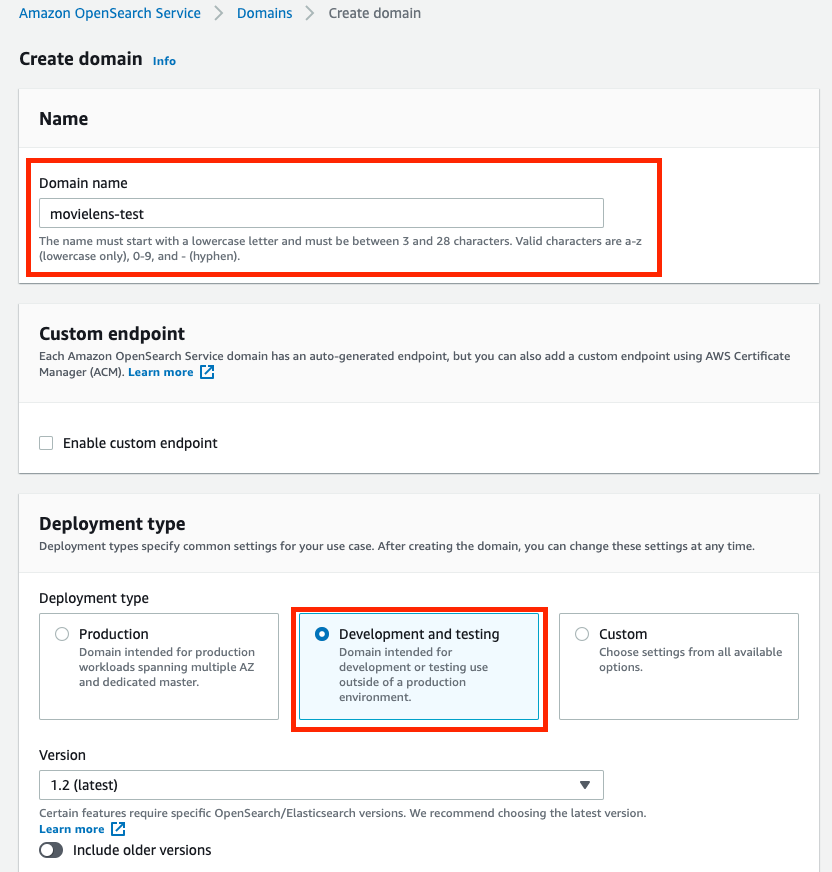
4. Change Occasion kind to t3.small.search, and hold all others as default.
5. For simplicity of this challenge, in Community, select Public entry
6. In Fantastic-grained entry management, Create the grasp person by setting the username and password.
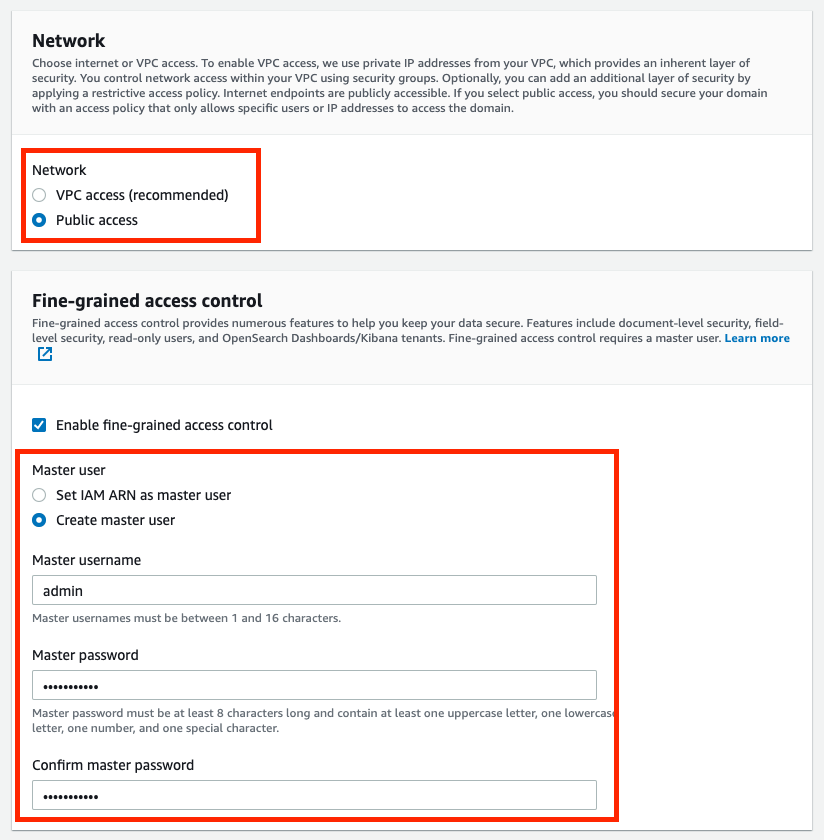
7. Within the Entry coverage, Select Solely use fine-grained entry management
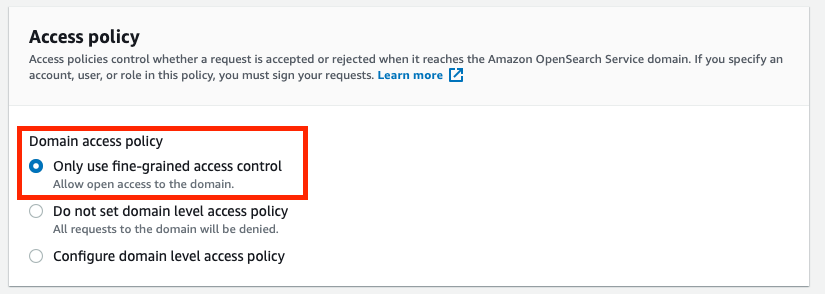
8. Ignore all the opposite settings by leaving them as default. Click on on Create. This will take as much as 15–half-hour to spin up, however normally quicker from my expertise.
AWS OpenSearch or Elasticsearch is clever sufficient to mechanically index any knowledge we add, after which we will write queries with any logical guidelines to question the outcomes. Nevertheless, some preprocessing work may be wanted to simplify our question efforts.
As we recall, our knowledge consists of three columns:
Each titles and genres are vital to us as we could wish to enter any key phrases in both/each of them to seek for the film we would like. Multi-field search is supported in OpenSearch, however for simplicity of question, we will additionally preprocess it by placing all of our key phrases into one devoted column, in order that it will increase the effectivity and lowers the question complexity.
Utilizing the preprocessing code above, we insert a brand new column known as search_index to the dataframe that incorporates the title and all of the genres:

The subsequent step is to transform knowledge into JSON format as a way to bulk add it to our area. The format specified for bulk knowledge add may be discovered within the developer information Possibility 2. One thing like this:
{"index": {"_index": "motion pictures", "_id": "2"}}
Kids
the place the first line specifies the index (doc) title to be saved within the area in addition to the document id (Right here I used the movieId column because the distinctive identifier). The second line consists of all the opposite fields within the dataset.
The next code is used for the conversion:
After being transformed, the info is saved within the knowledge folder as motion pictures.json . Now we have to add it into the area as beneath:
Notice that the endpoint may be discovered in your OpenSearch area web page. The username and password are the grasp username & password we set when creating this area.
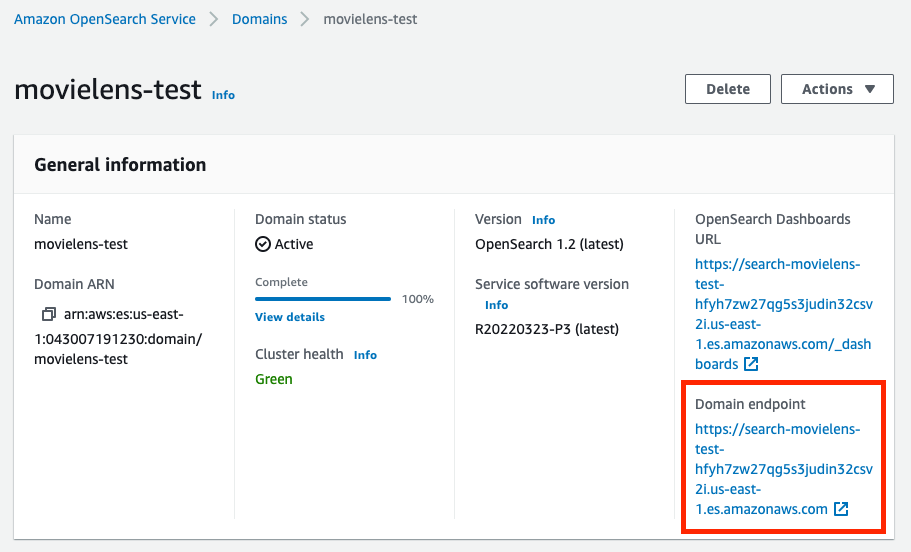
If it returns a <Response [200]>, then we’re good to go. The dataset is efficiently uploaded into the AWS OpenSearch area.
Now, with the info uploaded, now we have finished all of the work on the server-side. OpenSearch mechanically indexes the info to be prepared for queries. We will now begin engaged on the client-side to querying the info from the area.
To learn extra concerning the querying languages, listed here are 2 choices:
- Get began with the AWS OpenSearch Service Developer Information
- There are some very detailed documentations for querying knowledge from Elasticsearch and OpenSearch on this Official Elasticsearch Information Question DSL.
Nevertheless, we don’t want very superior functionalities on this instance. We are going to largely use round the usual match question with some small variations.
Here’s a fundamental instance:
Right here, we write the question to search for any matched information with the title = “jumanji”, serialize the JSON question as a string, and ship it to the area with the endpoint and credentials. Let’s see the returned outcome:
{'took': 4,
'timed_out': False,
'_shards': {'complete': 5, 'profitable': 5, 'skipped': 0, 'failed': 0},
'hits': {'complete': {'worth': 1, 'relation': 'eq'},
'max_score': 10.658253,
'hits': [{'_index': 'movies',
'_type': '_doc',
'_id': '2',
'_score': 10.658253,
'_source': Children}]}}
As we will see, it returns the document with the title equals to jumanji . There is just one matched outcome from our dataset, with the precise title as Jumanji (1995) , along with the opposite information akin to id, genres, and the search_index.
OpenSearch mechanically handles the higher/decrease case letters, any symbols, and white areas, so it may well discover our document nicely. As well as, the rating means how a lot confidence the returned outcomes match our question, the upper the higher. On this case, it’s 10.658253 . If we embrace the 12 months within the search question, like “jumanji 1995”, the rating will then enhance to 16.227726 . It is a vital metric to rank the outcomes when there are a number of ones returned by the question.
As an information scientist, Jupyter Pocket book is an efficient buddy, and with the favored ipywidgets, we will make the notebooks very interactive. Right here is a few code to construct a fundamental GUI that features a textual content field (for coming into key phrases) and a textual content output (for question outcomes show).
There are 5 sections within the code:
- search operate: A wrapper of the essential question launched within the part above. By giving an enter, it searches and returns the outcomes that comprise the enter key phrases.
- daring: A operate that makes use of Markdown to daring the key phrases within the outcomes for higher visualization of the outcomes.
- printmd: A wrapper operate to show Markdown in IPython
- text_change: A operate that handles widget occasions. On this case, at any time when the worth modifications within the textual content field, it would execute the search operate and return the highest 10 outcomes ranked by the scores. There’s additionally a timing module carried out to indicate how lengthy it takes to look.
- The final part of the code defines the widget parts to be displayed: a textual content field and an output. The widget occasion is triggered when the worth within the field is modified, and the outcomes will show within the output.
Here’s what it seems like once we execute the code:

Whereas we enter the key phrase “jumanji”, it retains looking for the up to date key phrase. Throughout the course of, there are 3 units of outcomes returned by the key phrases “j”, “ju”, and “jumanji” respectively. Nevertheless, it’s empty for “jum”, “juma”, “juman”, or “jumanj” as a result of the match question we used right here treats the key phrases entered as actual phrases and there’s no film in our dataset that incorporates these phrases.
This doesn’t appear to be our anticipated typeahead performance. To enhance the efficiency, we’ll look into some superior question choices beneath, together with prefix, boolean, and multi-field searches.
7.1 Match Phrase Prefix
One easy repair to the issue we encountered within the part above is to make use of match phrase prefix question as an alternative of the match question. Match phrase prefix question can return the paperwork that comprise the phrases of a supplied textual content within the similar order as supplied. The final time period of the supplied textual content is handled as a prefix, matching any phrases that start with that time period. [5]
It appears to be what we would like: As we enter the question, we don’t have to complete the time period earlier than it may well inform the outcomes.
So let’s modify our question this fashion!
Right here I can’t present the Python code once more, as a result of every thing stays the identical, aside from some slight modification of the question within the search operate. Now match turns into match_phrase_prefix :
question = {
'question': {
'match_phrase_prefix': {
'title': prefix
}
}
}
With the change, here’s what it seems like now:
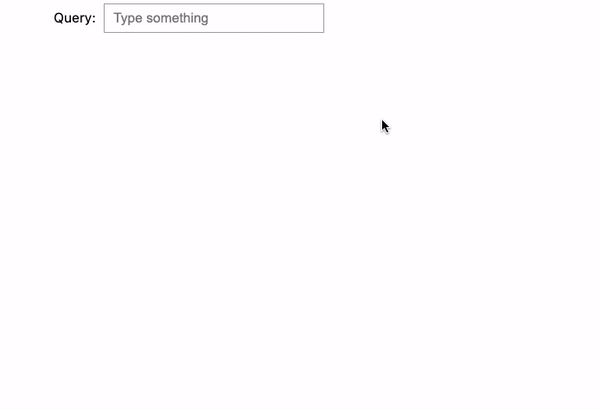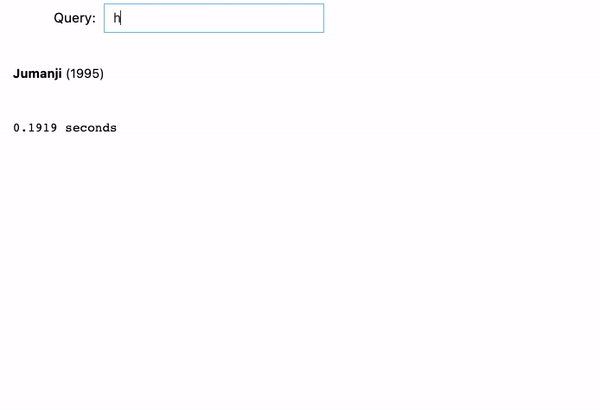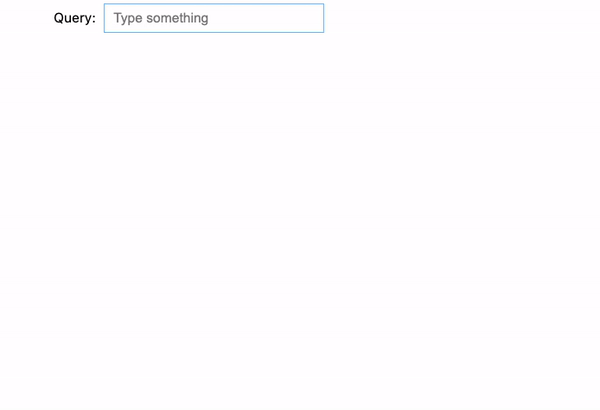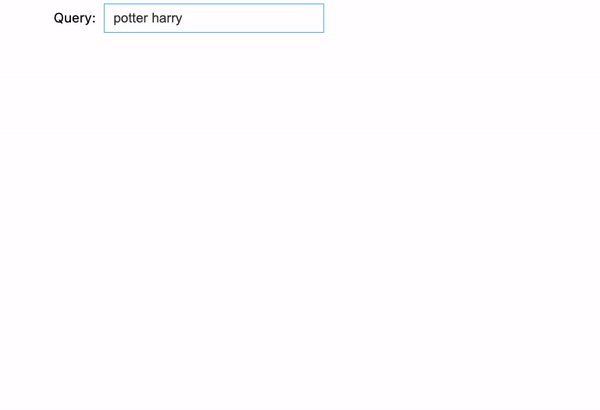
We tried 3 examples right here:
- jumanji: Now it’s fastened! As we kind, the search engine makes use of the entered textual content as a prefix and renders all desired output flawlessly.
- harry potter: It does the identical factor because the earlier instance. Once we attain the second time period “potter”, it begins to indicate all of the Harry Potter motion pictures.
- potter harry: Nevertheless, if we reverse “harry potter” into “potter harry”, it gained’t present any outcomes as a result of order issues within the match phrase prefix question.
Think about once we use the search engine, we aren’t at all times 100% positive that we keep in mind all of the key phrases within the right order, so we could wish to enhance the search engine in order that it turns into extra clever to assist us resolve the problem.
7.2 Match + Prefix with Boolean
To interrupt down the necessities for such a question:
- The final time period must be handled as a prefix
- The different phrases have to be actual matches
- We do not want the precise order to get desired outcomes
Sadly, there is no such thing as a such question kind in Elasticsearch/OpenSearch we will immediately use, however the instruments are versatile sufficient that we will implement the logic utilizing boolean queries.
The code proven above is the up to date search operate. As we will see right here, the question turns into for much longer now after incorporating the bool operation should:
- If we enter a search textual content that incorporates a couple of phrase, then we’ll deal with the final time period as a prefix, AND the earlier phrases are actual matches.
- If the search textual content is just one phrase (or much less), then we’ll simply deal with it as a prefix to look.
After implementing the modifications, let’s see the outcomes:
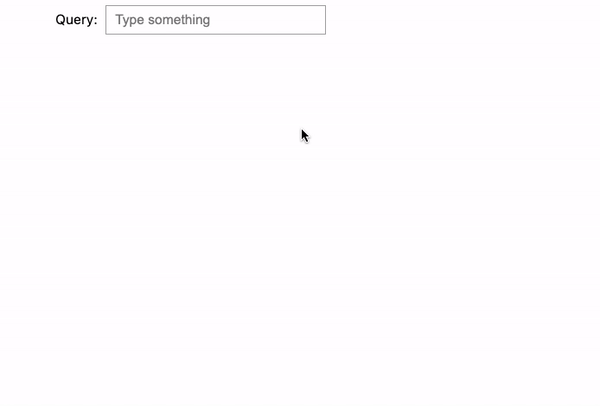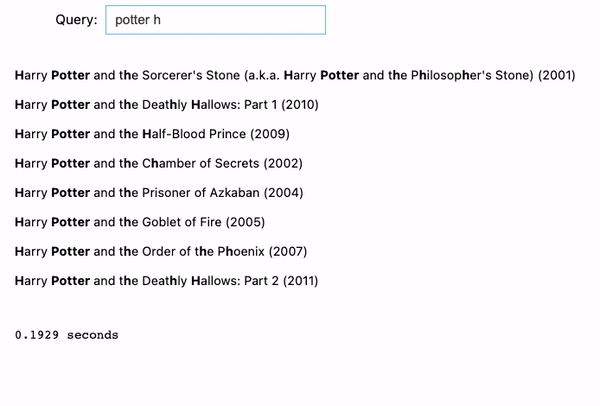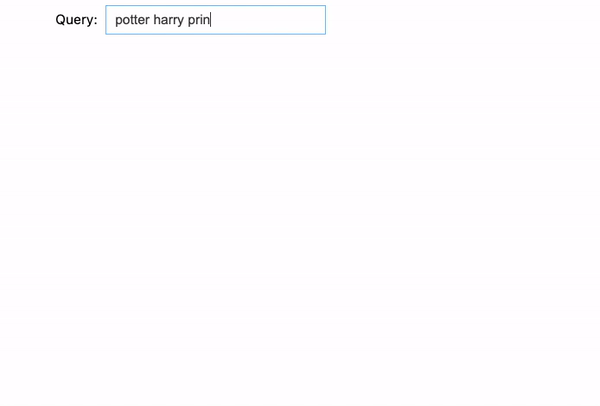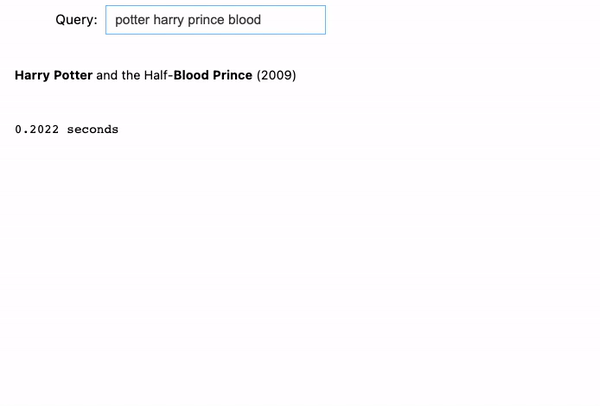
Now, when coming into in a very combined order: “potter harry prince blood”, the search engine is aware of what we’re on the lookout for, and it is ready to return the proper outcome: Harry Potter and the Half-Blood Prince (2009).
7.3 Multi-field Search
Till now, we solely searched within the film title discipline, however we will additional enhance the search engine to make it even smarter by leveraging some hidden fields, akin to genres in our case.
To look amongst a number of fields, there may be multi-match question within the Elasticsearch person information. Nevertheless, it doesn’t present sufficient energy to look prefixes whereas ignoring orders similtaneously we simply did. We nonetheless want booleans to make a compound question.
There’s a shortcut: Do not forget that we beforehand processed the dataset and ready a mixed search_index column to incorporate each title and style data. With this new discipline, we will simply modify our earlier question to incorporate the hidden style data with out explicitly utilizing multi-match queries.
Right here is the modified search_prefix operate, however in the event you look intently, there is no such thing as a change from the final one, besides we changed title by search_index to look amongst each titles and genres.
Right here is the outcome after the change:
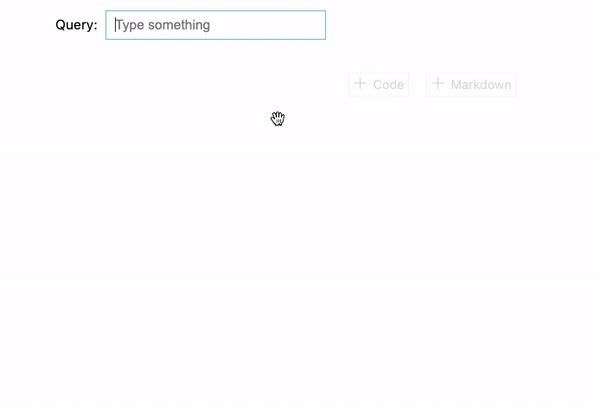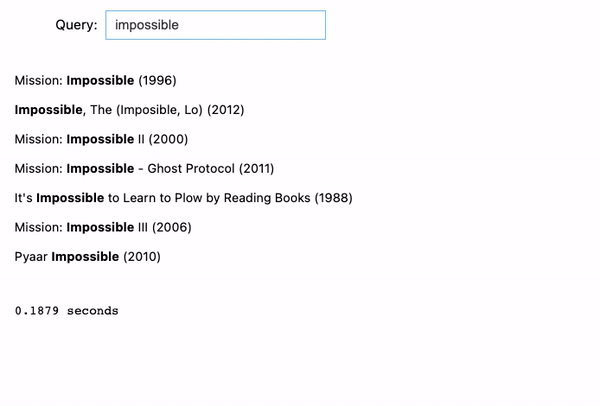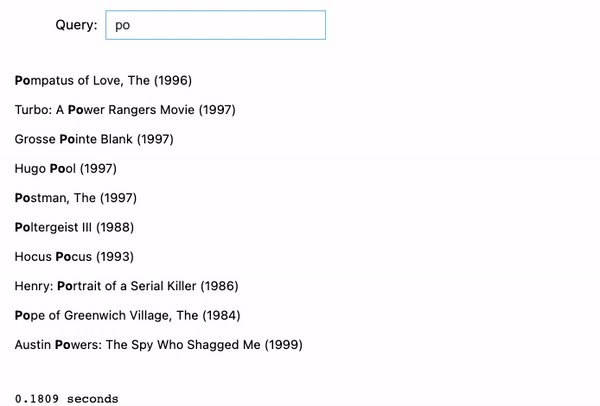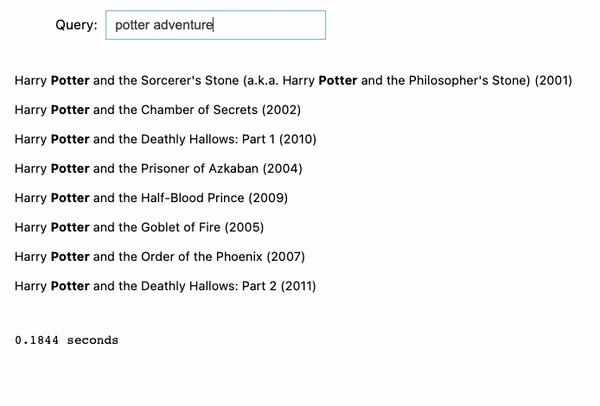
We tried 2 examples:
- Let’s say we keep in mind that there’s an journey film with the key phrase “unattainable”. We then enter “unattainable journey”, and it’ll return all of the Mission Unattainable motion pictures as a result of they’re categorized as “journey” motion pictures.
- Similar factor for Harry Potter. If coming into “potter journey”, it would return all of the Harry Potter motion pictures as a result of they’re all “journey” motion pictures as nicely.
On this publish, we simply walked by way of an end-to-end instance to construct an clever type-ahead search engine with the next steps:
- Put together a film dataset
- Arrange an AWS OpenSearch area
- Bulk add the dataset to the OpenSearch service for indexing
- Construct a easy type-ahead search engine GUI
- A number of methods of querying knowledge from the area, from fundamental to superior subjects
The outcome may be very spectacular: we’re capable of mimic the type-ahead searches as what Google does. Whereas typing the key phrase, the search engine analyzes and searches the database in close to real-time (0.2 seconds) to render the closest matches and information us within the course of additional narrowing down the record of search outcomes.
However, now we have modified the queries utilizing boolean operations that allow us to combine the key phrase orders. We will additionally enter values that belong to the hidden fields, such because the style names to assist us slim down and find the specified outcome. Each of the options make the search engine much more clever.
There are nonetheless many locations on this instance that we will probably enhance sooner or later:
- Jupyter Pocket book and its
ipywidgetsare very highly effective in constructing GUIs. Right here we solely used textual content field and output, however there are a lot of extra widgets that may very well be used for this instance, akin to buttons to set off search, checkboxes or dropdowns so as to add filters on the outcomes, or choose containers to click on on the advised outcomes as Google presents. - Nevertheless,
ipywidgetsnonetheless has restricted capabilities in comparison with the toolkits that front-end builders use, akin to JavaScript. The workflow proven on this instance is simply meant for fast testing and growth utilization for knowledge scientists, who’re very aware of Jupyter Notebooks however with restricted expertise in front-end growth. If we wish to construct a strong search engine app, this isn’t the very best apply to take. - Elasticsearch/OpenSearch Area Particular Language (DSL) is a really versatile software for us to put in writing queries that may go well with nearly any want. On this instance, we simply lined a really superficial layer of it. In case you are thinking about studying extra, right here is the entire documentation supplied by Elasticsearch.
- AWS OpenSearch is scalable. On this instance, we picked
t3.small.searchfor this 27,000-movie dataset, however we will normally anticipate higher outcomes if we scale up the sources. In the actual world, the quantity of the info may very well be of a very totally different magnitude as nicely, so correct sources have to be chosen for the precise knowledge measurement. - Safety is a critical matter for any cloud service. On this instance, we nearly utterly ignored all the safety settings, however whether it is in a manufacturing atmosphere, we have to take way more effort to boost the safety ranges.
On the very finish of the publish, one final reminder: Please keep in mind to delete the AWS OpenSearch area in the event you not want it, or it would incur pointless prices!
Thanks for studying! When you like this text, please observe my channel (actually recognize it  ). I’ll hold writing to share my concepts and tasks about knowledge science. Be at liberty to contact me in case you have any questions.
). I’ll hold writing to share my concepts and tasks about knowledge science. Be at liberty to contact me in case you have any questions.
I’m an information scientist at Sanofi. I embrace know-how and study new expertise daily. You’re welcome to succeed in me from Medium Weblog, LinkedIn, or GitHub. My opinions are my very own and never the views of my employer.
Please see my different articles:
[1] Dynamic Internet — Typeahead Search: https://doc.dynamicweb.com/documentation-9/how-tos/normal/implementing-typeahead-search
[2] Elastic — What’s Elasticsearch: https://www.elastic.co/what-is/elasticsearch
[3] MovieLens 20M Dataset: https://grouplens.org/datasets/movielens/20m/
F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: Historical past and Context. ACM Transactions on Interactive Clever Techniques (TiiS) 5, 4, Article 19 (December 2015), 19 pages. DOI=http://dx.doi.org/10.1145/2827872
[4] Amazon OpenSearch Service Developer Information: https://docs.aws.amazon.com/opensearch-service/newest/developerguide/gsg.html
[5] Elasticsearch Information — Question DSL: https://www.elastic.co/information/en/elasticsearch/reference/present/query-dsl.html

{kind=link}