
Getting the absolute best efficiency out of an utility at all times presents challenges. This reality is particularly true when growing machine studying (ML) and synthetic intelligence (AI) functions. Over time, Intel has labored carefully with the ecosystem to optimize a broad vary of frameworks and libraries for higher efficiency.
This temporary discusses the efficiency advantages derived from incorporating Intel-optimized ML libraries into Databricks Runtime for Machine Studying on 2nd Era Intel® Xeon® Platinum processors. The paper focuses on two of the preferred frameworks utilized in ML and deep studying (DL): scikit-learn and TensorFlow.
Intel-optimized ML libraries
The Intel oneAPI AI Analytics Toolkit offers information scientists, AI builders, and researchers acquainted Python instruments and frameworks to speed up end-to-end information science and analytics pipelines on Intel structure. The parts are constructed utilizing oneAPI libraries for low-level compute optimizations. This toolkit improves efficiency from preprocessing via ML, and it offers interoperability for environment friendly mannequin growth. Two well-liked ML and DL frameworks are scikit-learn and TensorFlow.
Scikit-learn
Scikit-learn is a well-liked open supply ML library for the Python programming language. It options numerous classification, regression, and clustering algorithms, together with help for:
- Vector machines
- Random forests
- Gradient boosting
- k-means
- DBSCAN
This ML library is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
The Intel Extension for Scikit-learn, accessible via the Intel oneAPI AI Analytics Toolkit, may also help increase ML efficiency and provides information scientists extra time to concentrate on their fashions. Intel has invested in optimizing the efficiency of Python itself with the Intel Distribution for Python, and it has optimized key information science libraries used with scikit-learn, equivalent to XGBoost, NumPy, and SciPy. For extra data on utilizing these extensions, learn the next article: https://medium.com/intel-analytics-software/save-time-and-money-with-intel-extension-for-scikit-lear….
TensorFlow
TensorFlow is one other well-liked open supply framework for growing end-to-end ML and DL functions. It has a complete, versatile ecosystem of instruments and libraries that lets researchers simply construct and deploy functions.
To take full benefit of the efficiency accessible in Intel processors, TensorFlow has been optimized utilizing Intel oneAPI Deep Neural Community Library (oneDNN) primitives. For extra data on these optimizations, along with efficiency information, consult with the article, “TensorFlow Optimizations on Trendy Intel Structure,” accessible right here: https://software program.intel.com/content material/www/us/en/develop/articles/tensorflow-optimizations-on-modern-int….
Databricks runtime for machine studying
Databricks is a unified data-analytics platform for information engineering, ML, and collaborative information science. It affords complete environments for growing data-intensive functions.
Databricks Runtime for Machine Studying is an built-in end-to-end surroundings that comes with:
- Managed companies for experiment monitoring
- Mannequin coaching
- Function growth and administration
- Function and mannequin serving.
It contains the preferred ML/DL libraries, equivalent to TensorFlow, PyTorch, Keras, and XGBoost, and it additionally contains libraries required for distributed coaching, equivalent to Horovod. For extra data, go to the Databricks internet web page at https://docs.databricks.com/runtime/mlruntime.html.
Databricks has been built-in with Microsoft Azure. This integration brings nice comfort to managing manufacturing infrastructure and working manufacturing workloads. Although cloud companies aren’t free, there are alternatives to cut back the price of possession by utilizing optimized libraries. This text makes use of Databricks on Azure to exhibit the answer and the efficiency outcomes achieved in Intel testing.
Intel-optimized ML libraries on Azure Databricks
Databricks Runtime for Machine Studying contains the inventory variations of scikit-learn and TensorFlow. To spice up efficiency, nonetheless, Intel engineers changed these variations with Intel-optimized variations and examined the outcomes. Databricks offers initialization scripts to facilitate customization at https://docs.databricks.com/clusters/init-scripts.html.
These scripts run in the course of the startup of every cluster node. Intel additionally developed two initialization scripts to include the Intel-optimized variations of scikit-learn and TensorFlow. The proper script to your wants depends upon whether or not you need the statically patched model or not:
The next directions describe how you can create a cluster utilizing both script. First, copy the initialization script to Databricks File System (DBFS) by finishing the next steps:
- Obtain both init_intel_optimized_ml.sh or init_intel_optimized_ml_ex.sh to an area folder.
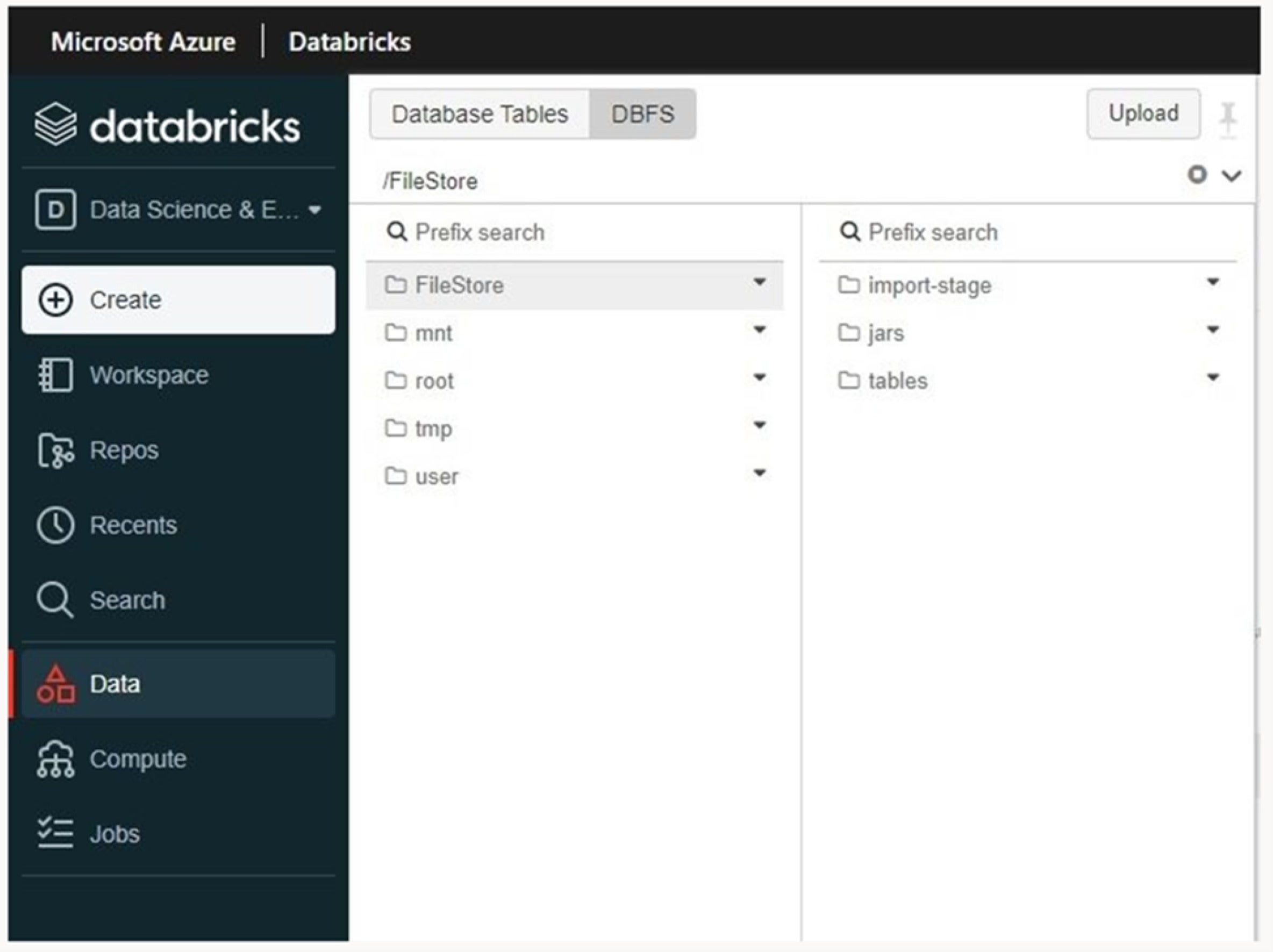
- Within the left sidebar, click on the Information icon.
- Click on the DBFS button, after which click on Add on the prime. If the DBFS button isn’t proven, observe the steering supplied in “Handle the DBFS file browser” to allow it.
- Within the Add Information to DBFS dialog, choose a goal listing (for instance, FileStore).
- Browse to the native file that you simply downloaded to the native folder, after which add it within the Recordsdata field.
 Intel
IntelSubsequent, launch the Databricks cluster utilizing the uploaded initialization script:
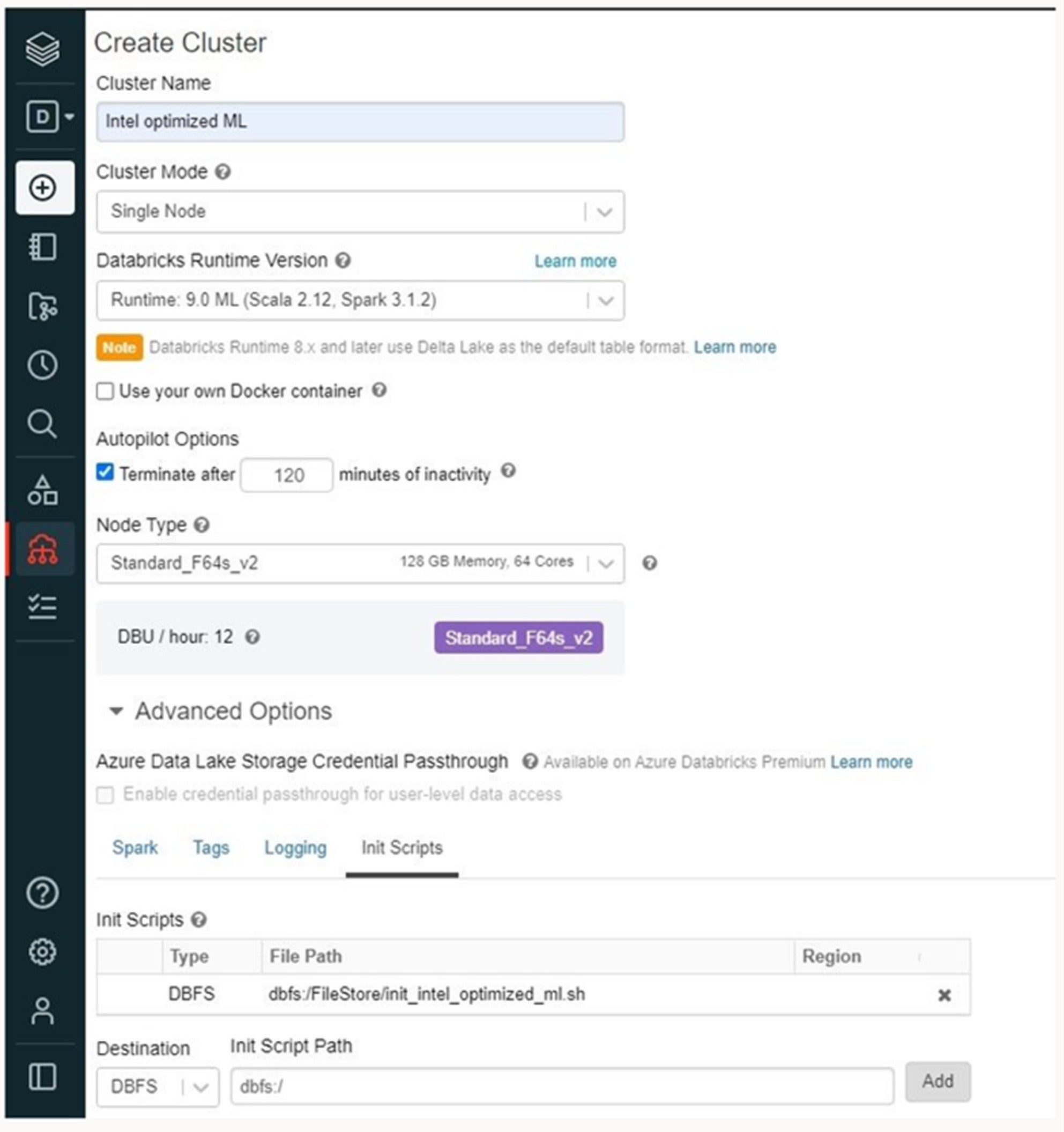
- On the Cluster Configuration web page, click on the Superior Choices toggle.
- On the bottom-right, click on the Init Scripts tab.
- Within the Vacation spot drop-down menu, choose the DBFS vacation spot sort.
- Specify the trail to the beforehand uploaded initialization script (that’s, dbfs:/FileStore/init_intel_optimized_ml.sh or dbfs:/FileStore/init_intel_optimized_ml_ex.sh).
- Click on Add.
 intel
intelConfer with the Intel optimized ML for Databricks steering at https://github.com/oap-project/oap-tools/tree/grasp/integrations/ml/databricks for extra detailed data.
Efficiency measurements
The Intel engineers in contrast scikit-learn and TensorFlow efficiency for each coaching and prediction between two Databricks clusters. The baseline cluster was created utilizing default libraries with out the initialization script. The opposite cluster was created utilizing Intel-optimized ML libraries via specifying the initialization script mentioned beforehand.
Scikit-learn coaching and prediction efficiency
Intel used Databricks Runtime 9.0 for Machine Studying with the next benchmarks for this testing. The Intel engineers used scikit-learn_bench (https://github.com/IntelPython/scikit-learn_bench) to check the efficiency of frequent scikit-learn algorithms with and with out the Intel optimizations. The benchmark_sklearn.ipynb pocket book (https://github.com/oap-project/oap-tools/blob/grasp/integrations/ml/databricks/benchmark/benchmark_…) is supplied for comfort to run scikit-learn_bench on a Databricks cluster.
Intel in contrast coaching and prediction efficiency for the libraries by creating one single-node Databricks cluster with the inventory library and one other utilizing the Intel-optimized model. Each clusters used the Standard_F16s_v2 Azure occasion sort.
The benchmark pocket book was run on each clusters. The Intel engineers set a number of configurations for every algorithm to get correct coaching and prediction efficiency information (for particulars, see https://github.com/oap-project/oap-tools/blob/grasp/integrations/ml/databricks/benchmark/skl_config…). Intel examined a number of configurations for every algorithm. Desk 1 exhibits the efficiency information of 1 configuration for every algorithm.
Desk 1. Evaluating the coaching and prediction efficiency of inventory libraries and Intel-optimized libraries (all instances in seconds)
|
Algorithm |
Enter configuration |
Coaching time (seconds) |
Prediction time (seconds) |
||
|
Inventory scikit-learn (baseline) |
Intel Extension for Scikit-learn |
Inventory scikit-learn (baseline) |
Intel Extension for Scikit-learn |
||
|
kmeans |
config1 |
17.91 |
17.87 |
3.76 |
0.39 |
|
ridge_regression |
config1 |
1.47 |
0.10 |
0.07 |
0.06 |
|
linear_regression |
config1 |
5.03 |
0.10 |
0.07 |
0.06 |
|
logistic_regression |
config3 |
74.82 |
6.63 |
0.62 |
0.08 |
|
svm |
config2 |
173.81 |
10.61 |
49.90 |
0.46 |
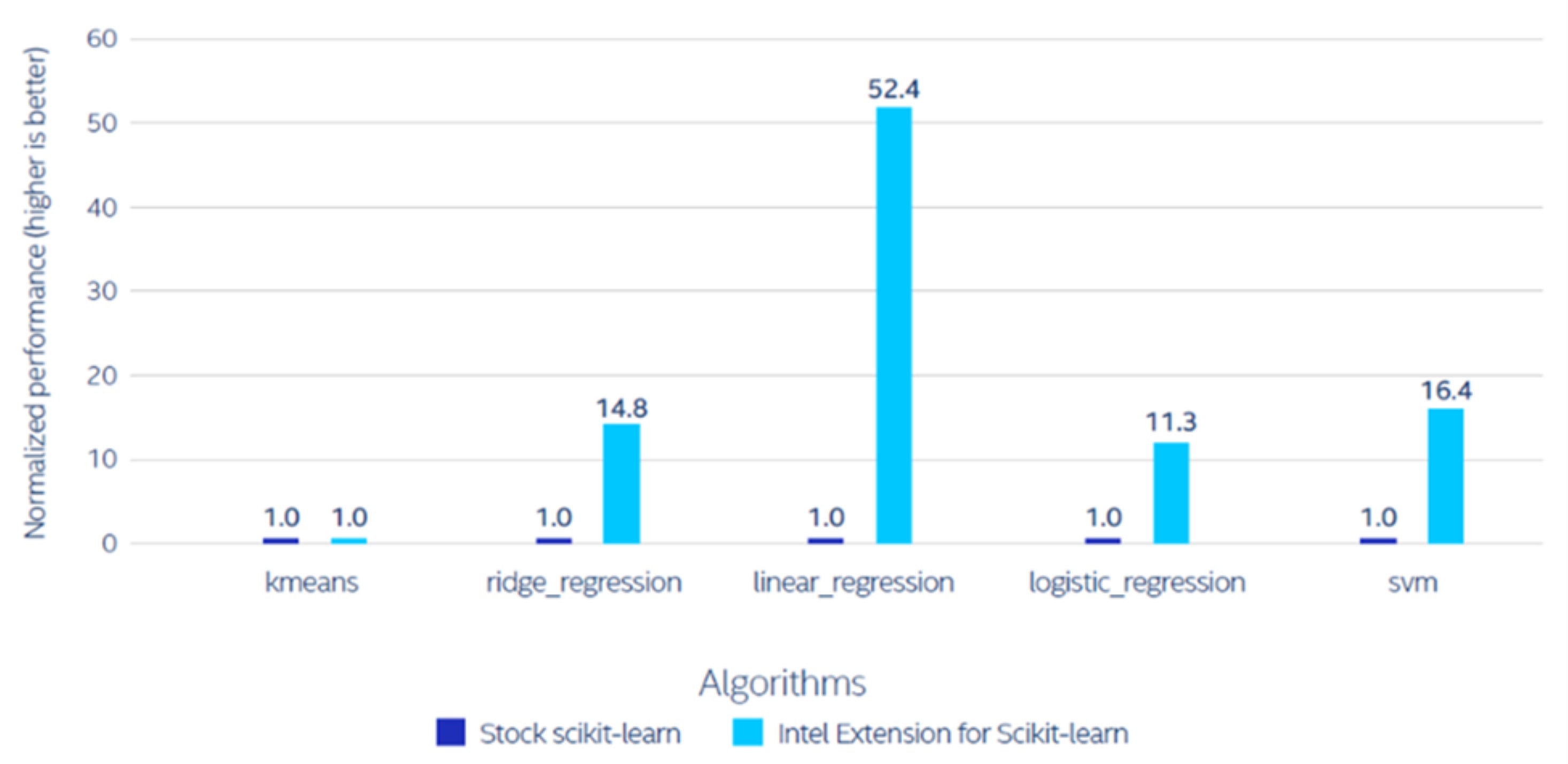
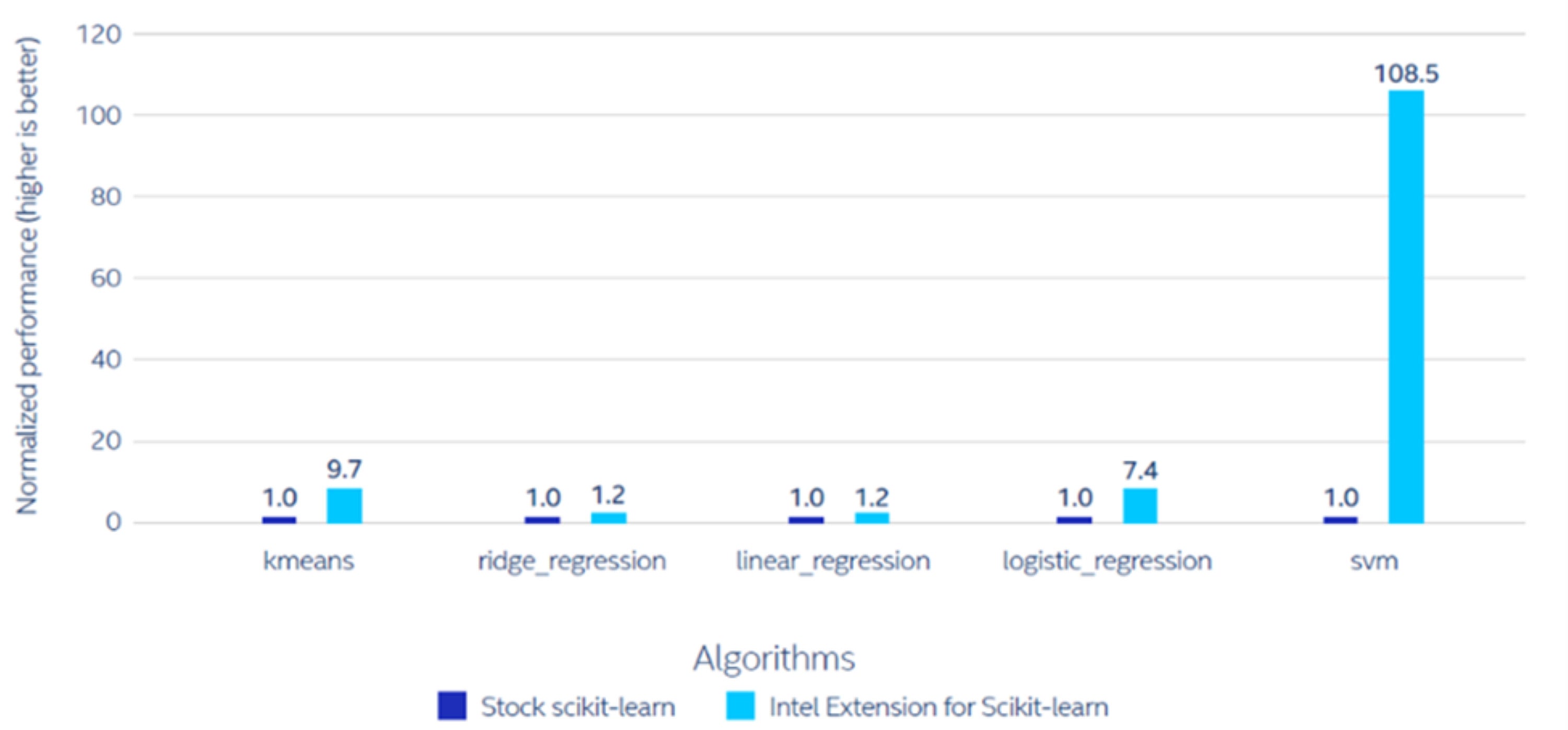
The Intel-optimized model of scikit-learn drastically improved coaching and prediction efficiency for every algorithm. For some algorithms, like svm and brute_knn, the Intel-optimized model of the scikit-learn library achieved an order of magnitude leap in efficiency. See Figures 1 and a pair of for the coaching and prediction efficiency outcomes, respectively.
 Intel
IntelDetermine 1. Coaching efficiency of the Intel-optimized scikit-learn library over the inventory model
 Intel
IntelDetermine 2. Prediction efficiency of the Intel-optimized scikit-learn library over the inventory model
TensorFlow coaching and prediction efficiency
Bidirectional Encoder Representations from Transformers, or BERT (https://github.com/google-research/bert), is a brand new technique of pre-training language representations. This technique obtains state-of-the-art outcomes on a variety of pure language processing (NLP) duties. Mannequin Zoo (https://github.com/IntelAI/fashions) accommodates hyperlinks to pretrained fashions, pattern scripts, and step-by-step tutorials for a lot of well-liked open-source ML fashions optimized to run on Intel Xeon Scalable processors.
The Intel engineers used Mannequin Zoo to run the BERT Giant (https://github.com/IntelAI/fashions/tree/v1.8.1/benchmarks/language_modeling/tensorflow/bert_large/REA…) mannequin on SQuADv1.1 datasets to check the efficiency of TensorFlow with and with out Intel’s optimizations. As soon as once more, the crew offers a pocket book (benchmark_tensorflow_bertlarge.ipynb) to run the benchmark on the Databricks cluster. For extra particulars, consult with “Run Efficiency Comparability Benchmarks” at https://github.com/oap-project/oap-tools/tree/grasp/integrations/ml/databricks/benchmark.
The Intel engineers used a single-node Databricks cluster with Standard_F32s_v2, Standard_F64s_v2, and Standard_F72s_v2 occasion varieties for the TensorFlow efficiency analysis. For every occasion sort, the Intel engineers in contrast the inference and coaching efficiency between the inventory TensorFlow and Intel-optimized TensorFlow libraries.
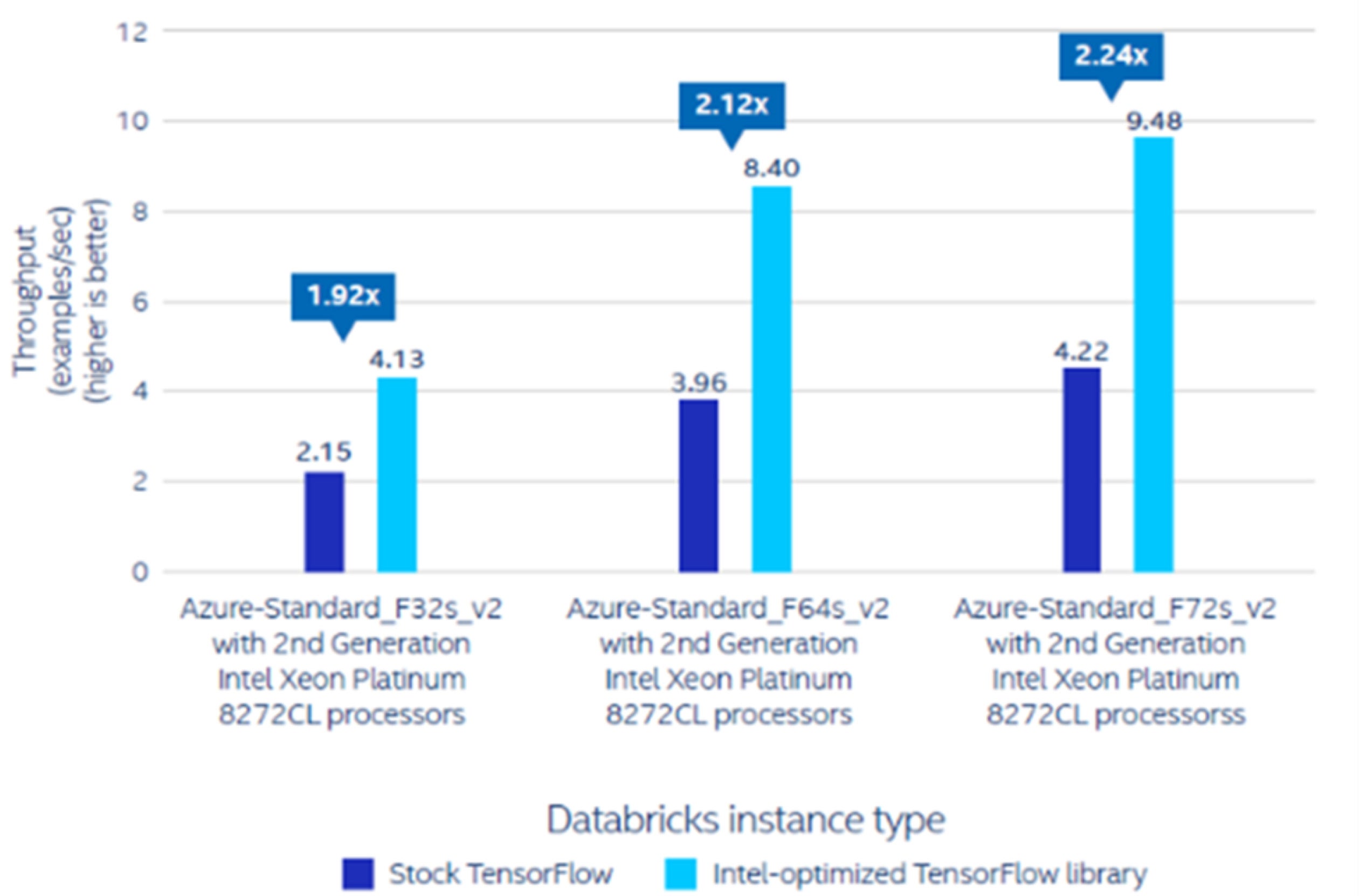
The testing discovered that the latter delivers 1.92x, 2.12x, and a pair of.24x inference efficiency on Databricks Runtime for Machine Studying with Standard_F32s_v2, Standard_F64s_v2, and Standard_F72s_v2 cases, respectively (see Determine 3). For coaching, the Intel-optimized TensorFlow library delivers 1.93x, 1.76x, and 1.84x coaching efficiency on Standard_F32s_v2, Standard_F64s_v2, and Standard_F72s_v2 cases, respectively (see Determine 4).
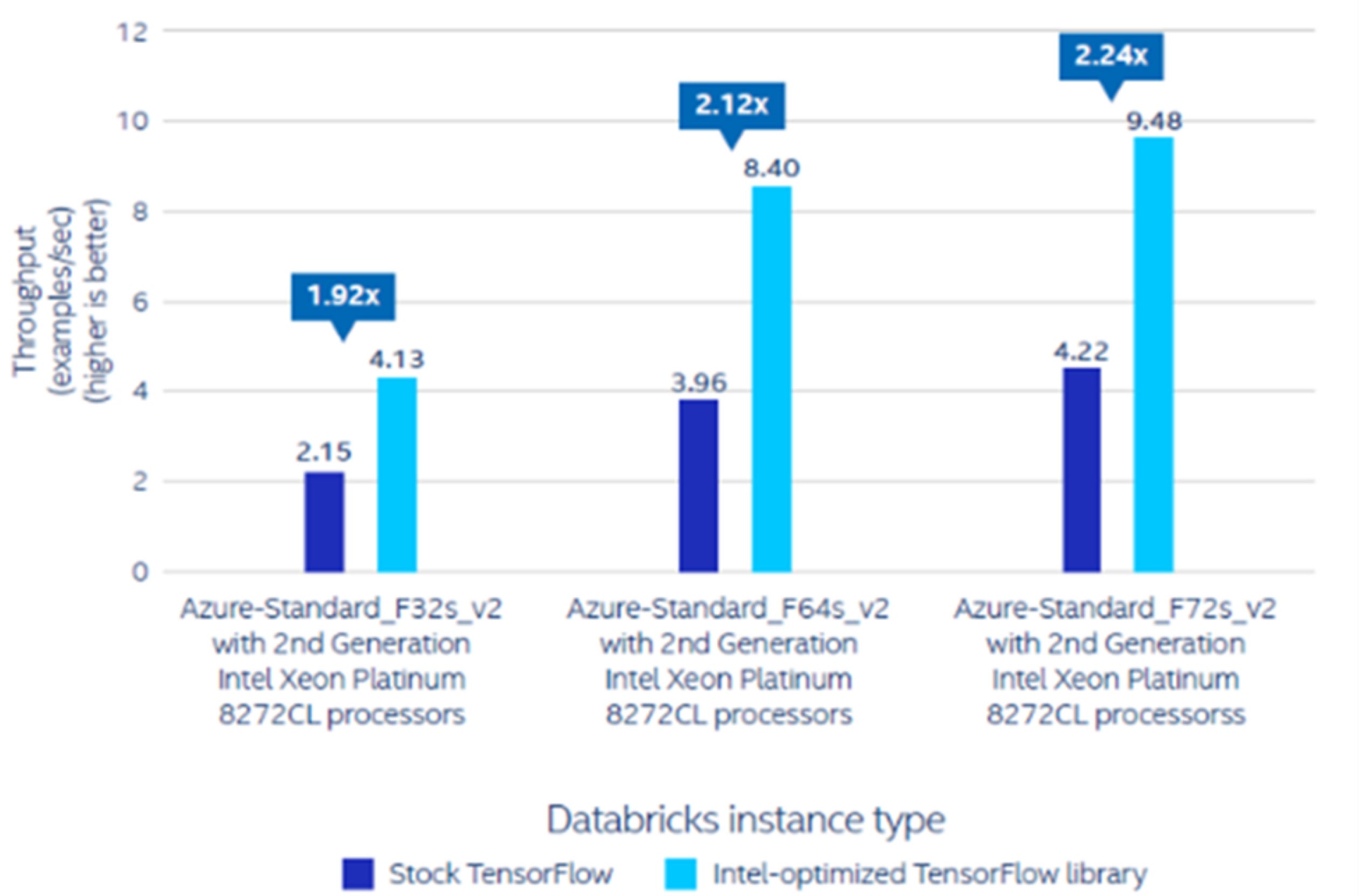 Intel
IntelDetermine 3. Inference speedup of the Intel-optimized TensorFlow library over the inventory model; efficiency varies by use, configurations, and different elements[i]
 Intel
IntelDetermine 4. Coaching speedup for the Intel-optimized TensorFlow library over the inventory model; efficiency varies by use, configurations, and different elements[i]
Concluding remarks
The Intel-optimized variations of the scikit-learn and TensorFlow libraries ship important enhancements in coaching and inference efficiency on Intel XPUs. Intel has demonstrated that organizations can enhance efficiency and scale back prices by changing the inventory scikit-learn and TensorFlow libraries included in Databricks Runtime for Machine Studying with the Intel-optimized variations.
When Databricks provides help for Databricks Container Companies (https://docs.databricks.com/clusters/custom-containers.html) to the Databricks Runtime for Machine Studying, Intel will discover incorporating these optimized libraries via Docker photos. This method may make it simpler to combine along with your steady integration/steady deployment (CI/CD) pipelines as a part of your MLOps surroundings.
For extra data, go to: https://github.com/oap-project/oap-tools/tree/grasp/integrations/ml/databricks
Please observe:
- Efficiency varies by use, configuration and different elements. Study extra at www.Intel.com/PerformanceIndex.
- Efficiency outcomes are based mostly on testing as of dates proven in configurations and should not replicate all publicly accessible updates. No product or part may be completely safe.
- Your prices and outcomes could fluctuate.
- Intel applied sciences could require enabled {hardware}, software program or service activation.
Study Intel OneAPI Analytics and AI-Toolkit, right here.

{kind=link}