
This submit discusses highlights of the Thirty-Third AAAI Convention on Synthetic Intelligence (AAAI-19).
I attended AAAI 2019 in Honolulu, Hawaii final week. Total, I used to be notably shocked by the curiosity in pure language processing on the convention. There have been 15 classes on NLP (most standing-room solely) with ≈10 papers every (oral and highlight shows), so round 150 NLP papers (out of 1,150 accepted papers total). I additionally actually loved the range of invited audio system who mentioned subjects from AI for social good, to adversarial studying and imperfect-information video games (movies of all invited talks can be found right here). One other cool factor was the Oxford type debate, which required debaters to take controversial positions. This was a pleasant change of tempo from panel discussions, which are likely to converge to a uniform opinion.
Desk of contents:
In his discuss on the Reasoning and Studying for Human-Machine Dialogues workshop, Phil Cohen argued that chatbots are an try to keep away from fixing the onerous issues of dialogue. They supply the phantasm of getting a dialogue however actually don’t have a clue what we’re saying or which means. What we must always somewhat do is acknowledge intents by way of semantic parsing. We should always then purpose concerning the speech acts, infer a consumer’s plan, and assist them to succeed. You could find extra details about his views in this place paper.
Throughout the panel dialogue, Imed Zitouni highlighted that the restrictions of present dialogue fashions have an effect on consumer behaviour. 75-80% of the time customers solely make use of 4 abilities: “play music”, “set a timer”, “set a reminder”, and “what’s the climate”. Phil argued that we must always not need to discover ways to discuss, how one can make a suggestion, and so on. once more for every area. We will usually construct easy dialogue brokers for brand spanking new domains “in a single day”.
On the Workshop on Reproducible AI, Joel Grus argued that Jupyter notebooks are unhealthy for reproducibility. Instead, he really useful to undertake higher-level abstractions and declarative configurations. One other good useful resource for reproducibility is the ML reproducibility guidelines by Joelle Pineau, which supplies a listing of things for algorithms, concept, and empirical outcomes to implement reproducibility.
A group from Fb reported on their experiments reproducing AlphaZero of their ELF framework, coaching a mannequin utilizing 2,000 GPUs in 2 weeks. Reproducing an on-policy, distributed RL system similar to AlphaZero is especially difficult because it doesn’t have a hard and fast dataset and optimization relies on the distributed atmosphere. Coaching smaller variations and scaling up is essential. For reproducibility, the random seed, the git commit quantity, and the logs must be saved.
Throughout the panel dialogue, Odd Eric Gunderson argued that reproducibility must be outlined because the potential of an unbiased analysis group to supply the identical outcomes utilizing the identical AI technique based mostly on the documentation by the unique authors. Levels of reproducibility might be measured based mostly on the provision of several types of documentation, similar to the tactic description, information, and code.
Pascal van Hentenryck argued that reproducibility could possibly be made a part of the peer evaluate course of, similar to within the Mathematical Programming Computation journal the place every submission requires an executable file (which doesn’t have to be public). He additionally identified that—empirically—papers with supplementary supplies usually tend to be accepted.
On the Reasoning and Advanced QA Workshop, Ken Forbus mentioned an analogical coaching technique for QA that adapts a general-purpose semantic parser to a brand new area with few examples. On the finish of his discuss, Ken argued that the practice/take a look at technique in ML is holding us again. Our studying techniques ought to use wealthy relational representations, collect their very own information, and consider progress.
Ashish Sabharwal mentioned the OpenBookQA dataset offered at EMNLP 2018 throughout his discuss. The open e-book setting is located between studying comprehension and open-ended QA on the textual QA spectrum (see beneath).
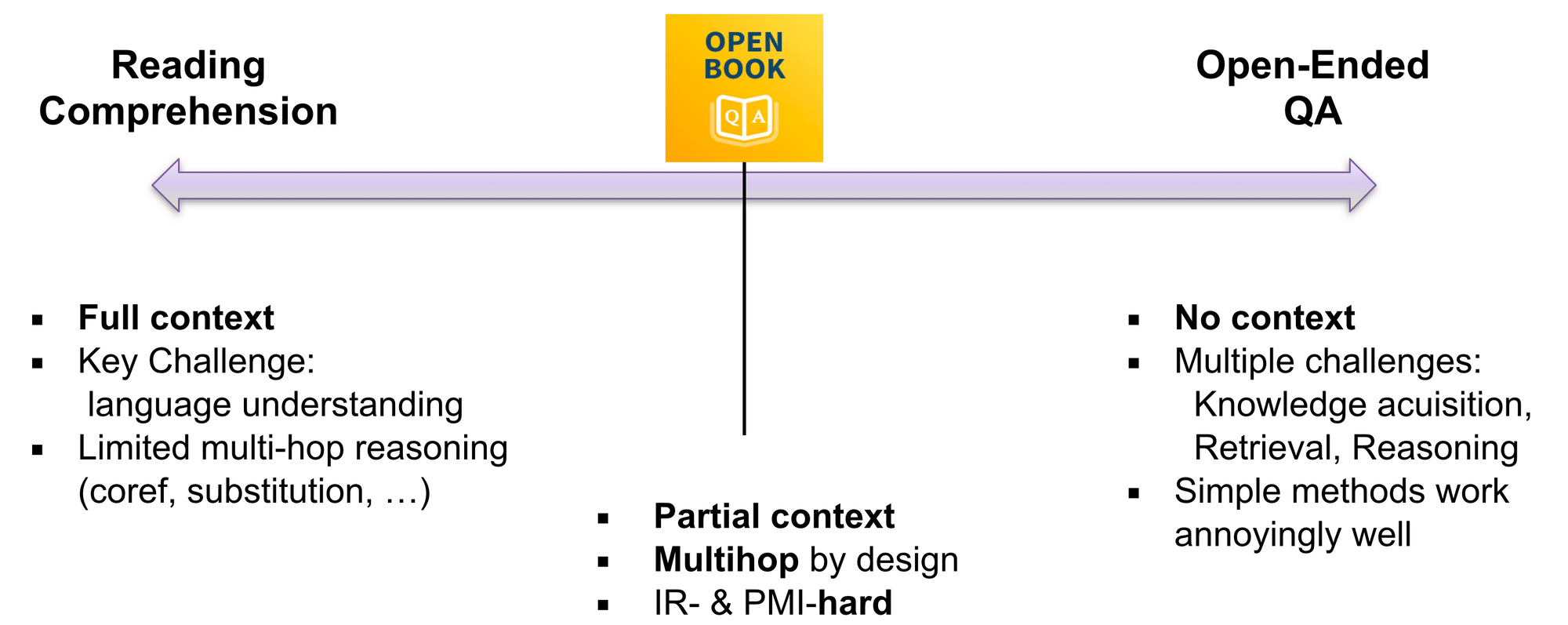
It’s designed to probe a deeper understanding somewhat than memorization abilities and requires making use of core ideas to new conditions. He additionally argued that whereas entailment is acknowledged as a core NLP job with many functions, it’s nonetheless missing a convincing software to an end-task. That is primarily as a consequence of multi-sentence entailment being quite a bit tougher, as irrelevant sentences usually have vital textual overlap.
Moreover, he mentioned the design of leaderboards, which need to make tradeoffs alongside a number of competing axes with respect to the host, the submitters, and the neighborhood. A selected deficit of present leaderboards is that they make it troublesome to share and construct upon profitable methods. For an intensive dialogue of the professionals and cons of leaderboards, take a look at this latest NLP Highlights podcast.
The primary a part of the ultimate panel dialogue targeted on essential excellent technical challenges for query answering. Michael Witbrock emphasised methods to create datasets that can’t simply be exploited by neural networks, such because the adversarial filtering in SWAG. Ken argued that fashions ought to provide you with solutions and explanations somewhat than performing a number of alternative query answering, whereas Ashish famous that such explanations have to be routinely validated.
Eduard Hovy recommended that a method in direction of a system that may carry out extra complicated QA might include the next steps:
- Construct a symbolic numerical reasoner that leverages relations from an present KB, similar to Geobase, which incorporates geography information.
- Take a look at the subset of questions in present pure language datasets, which require reasoning that’s potential with the reasoner.
- Annotate these questions with semantic parses and practice a semantic parsing mannequin to transform the inquiries to logical varieties. These can then be offered to the reasoner to supply a solution.
- Increase the reasoner with one other reasoning part and repeat steps 2-3.
The panel members famous that such reasoners exist, however lack a typical API.
Lastly, listed below are just a few papers on query answering that I loved:
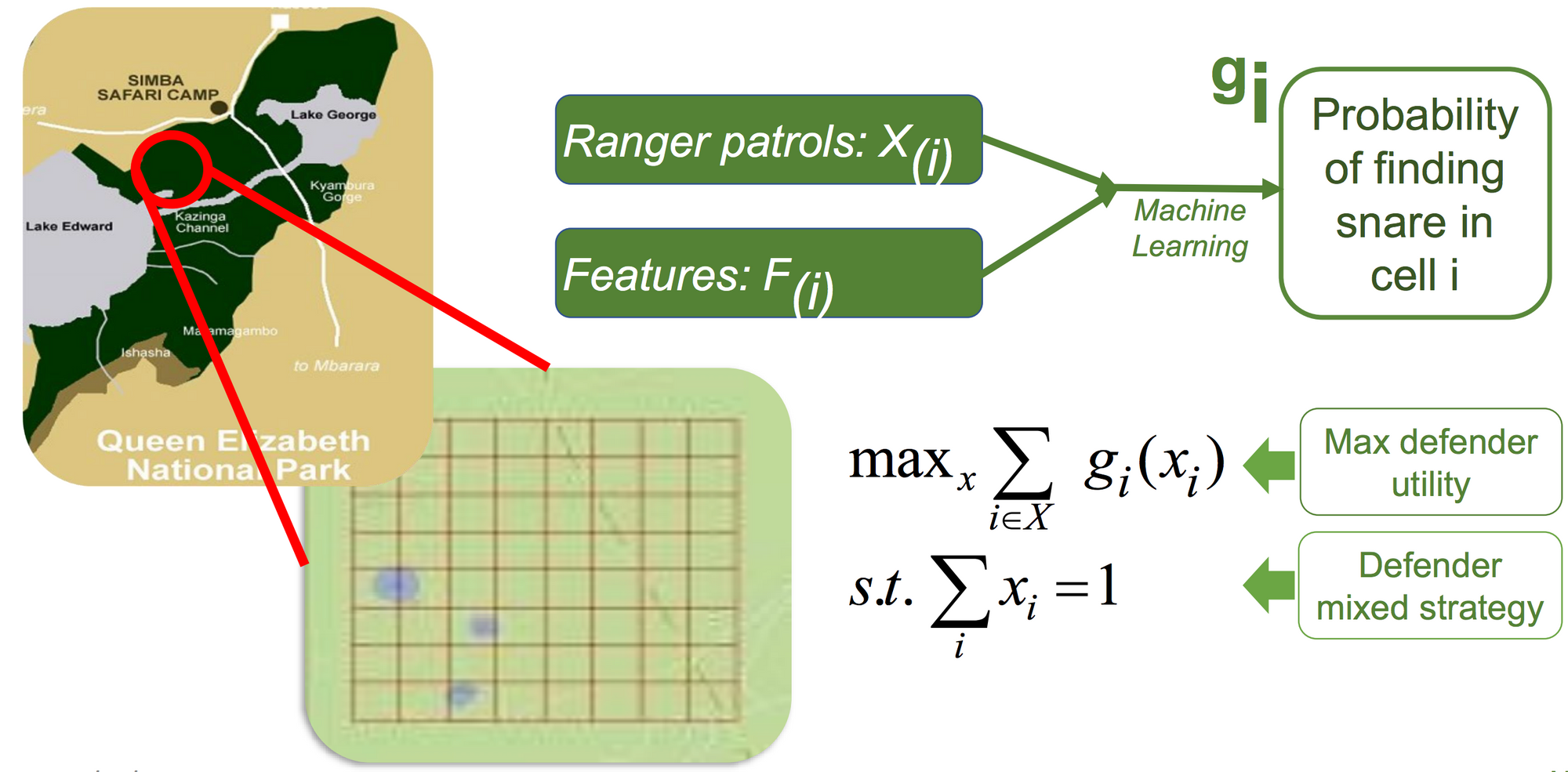
Throughout his invited discuss, Milind Tambe seemed again on 10 years of analysis in AI and multiagent techniques for social good (video obtainable right here; slides obtainable right here). Milind mentioned his analysis on utilizing sport concept to optimize safety assets similar to patrols at airports, air marshal assignments on flights, coast guard patrols, and ranger patrols in African nationwide parks to guard towards poachers. Total, his discuss was a hanging reminder of the constructive results AI can have whether it is employed for social good.
The Oxford type debate targeted on the proposition “The AI neighborhood in the present day ought to proceed to focus totally on ML strategies” (video obtainable right here). It pitted Jennifer Neville and Peter Stone on the ‘professional’ aspect towards Michael Littman and Oren Etzioni on the ‘towards’ aspect, with Kevin Leyton-Brown as moderator. Total, the controversy was entertaining and interesting to observe.

Listed below are some consultant remarks from every of the debaters that caught with me:
“The distinctive power of the AI neighborhood is that we deal with the issues that have to be solved.” – Jennifer Neville
“We’re in the midst of one of the vital superb paradigm shifts in all of science, definitely pc science.” – Oren Etzioni
“If you wish to have an effect, don’t comply with the bandwagon. Maintain alive different areas.” – Peter Stone
“Scientists within the pure sciences are literally very enthusiastic about ML as a lot of their analysis depends on costly computations, which might be approximated with neural networks.” – Michael Littman
There have been some essential observations and in the end a common consensus that ML alone shouldn’t be sufficient and we have to combine different strategies with ML. Yonatan Belinkov additionally dwell tweeted, whereas I tweeted some remarks that elicited laughs.
Throughout his invited discuss (video obtainable right here), Ian Goodfellow mentioned a multiplicity of areas to which adversarial studying has been utilized. Amongst many advances, Ian talked about that he was impressed by the efficiency and suppleness of consideration masks for GANs, notably that they don’t seem to be restricted to round masks.
He mentioned adversarial examples, that are a consequence of shifting away from i.i.d. information: attackers are capable of confuse the mannequin by displaying uncommon information from a unique distribution similar to graffiti on cease indicators. He additionally argued—opposite to the prevalent opinion—that deep fashions which can be extra strong are extra interpretable than linear fashions. The primary purpose is that the latent area of a linear mannequin is completely unintuitive, whereas a extra strong mannequin is extra inspectable (as might be seen beneath).

Semi-supervised studying with GANs can permit fashions to be extra sample-efficient. What’s attention-grabbing about such functions is that they deal with the discriminator (which is often discarded) somewhat than the generator the place the discriminator is prolonged to classify n+1 courses. Relating to leveraging GANs for NLP, Ian conceded that we presently haven’t discovered a great way to cope with the massive motion area required to generate sentences with RL.
In his invited discuss (video obtainable right here), Tuomas Sandholm—whose AI Libratus was the primary AI to beat prime Heads-Up No-Restrict Texas Maintain’em professionals in January 2017—mentioned new outcomes for fixing imperfect-information video games. He pressured that solely game-theoretically sound methods yield methods which can be strong towards all opponents in imperfect-information video games. Different benefits of a game-theoretic method are a) that even when people have entry to your complete historical past of performs of the AI, they nonetheless cannot discover holes in its technique; and b) it requires no information, simply the principles of the sport.
For fixing such video games, the standard of the answer is determined by the standard of the abstraction. Growing higher abstractions is thus essential, which additionally applies to modelling such video games. In imperfect-information video games, planning is essential. In real-time planning, we should contemplate how the opponent can adapt to adjustments within the coverage. In distinction to perfect-information video games, states don’t have well-defined values.
There have been a number of papers that included totally different inductive biases into present fashions:
Papers on switch studying ranged from multi-task studying and semi-supervised studying to sequential and zero-shot switch:
Naturally there have been additionally quite a few papers that offered new strategies for studying phrase embeddings:
Lastly, listed below are some papers that I loved that don’t match into any of the above classes:
Cowl picture: AAAI-19 Opening Reception

{kind=link}