Exploring a vital mechanism for enhancing the pattern effectivity of deep reinforcement studying brokers
Coaching deep reinforcement studying brokers requires important trial-and-error for the agent to study strong insurance policies to perform a number of duties in its surroundings. For these functions, the agent is often solely advised whether or not its habits ends in a big or small reward; subsequently, the agent should not directly study each the habits and worth of sure actions and states. As one can think about, this sometimes requires the agent to experiment with its habits and estimates for fairly some time.
Producing these experiences might be troublesome, time-consuming, and costly, notably for real-life functions akin to humanoid robotics. Subsequently, a query many roboticists and machine studying researchers have been contemplating is: “How can we decrease the variety of experiences we have to generate so as to efficiently prepare strong and high-performing brokers?”
Simply getting began with deep reinforcement studying? Take a look at this improbable intro from OpenAI.
As you most likely suspected, that is the place expertise replay is available in! The thought behind this significant method is easy — reasonably than regenerating new experiences every time we need to prepare the agent, why don’t we proceed studying from experiences we have already got obtainable?
Expertise replay is a vital element of off-policy deep reinforcement studying algorithms, enhancing the pattern effectivity and stability of coaching by storing the earlier surroundings interactions skilled by an agent [1].
What Do Expertise Replay Buffers Retailer?
To reply this query, we first want to go to the widespread implementations of “experiences” in deep reinforcement studying:
Representing Coaching Expertise as Transitions and Rollouts
In reinforcement studying, experiences are represented as transitions and rollouts, the latter of which is a set of temporally contiguous transitions. These transitions, of their most common type, are composed of a quintuple of 5 options/indicators given to the agent as a coaching pattern:
- State (s): This represents the knowledge obtainable to the agent that can be utilized for motion choice. You possibly can consider s because the illustration of the world that the agent is ready to observe. Usually, the agent can’t observe the true state of the world, only a subset of it.
- Actions (a): These symbolize the alternatives, both discrete or steady, the agent could make because it interacts with its surroundings. The agent’s alternative of motion will sometimes impression each its subsequent state s’ and reward r.
- Reward (r): These symbolize the rewards given to the agent for taking a given motion a given state s, or, in some instances, merely for observing/being within the state similar to a.
- Subsequent State (s’): This represents the state similar to the state the agent transitions to after being in state s and taking motion a.
- Performed Alerts (d): These are binary indicators representing whether or not the present transition represents the ultimate transition in a given rollout/episode. These usually are not essentially used for all environments — when they don’t seem to be wanted (e.g. environments with no termination circumstances), they will merely all the time be set to 1 or 0.
Written symbolically, these transition quintuples T are given as:
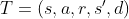
And a rollout, also called an episode or trajectory and denoted R, is given as a set of N transitions:
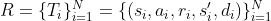
These transitions T and rollouts R are the first representations of how an agent’s experiences are saved. These transitions all lie throughout the transition area, which we denote by the operate τ. The area of τ is given by the Cartesian product of the state and motion areas of the agent S x A (respectively), and the co-domain is given by the Cartesian product of the reward and state areas (R x S). Mathematically, the transition operate is outlined (when it’s deterministic) by:
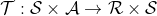
How Do We Implement Expertise Replay?
Expertise replay is often carried out as a round, first-in-first-out (FIFO) replay buffer (consider it as a database storing our agent’s experiences). We use the next definitions for categorizing our expertise replay buffers [1]:
- Replay Capability: The overall variety of transitions saved within the replay buffer.
- Age of transition: Outlined to be the variety of gradient steps taken by the learner because the transition was generated. The oldest coverage of a replay buffer is represented by the age of the oldest transition within the buffer.
- Replay Ratio: The variety of gradient updates per surroundings transition. Supplied the agent can proceed to study secure insurance policies, behaviors, and expertise by coaching on the identical units of experiences repeatedly, a better replay ratio might be useful for enhancing the pattern effectivity of off-policy reinforcement studying brokers.
We’ve talked about learn how to describe replay buffers, however how do they work? Briefly, replay buffers “replay” experiences for an agent, permitting them to revisit and prepare on their recollections. Intuitively, it permits brokers to “replicate” and “study” from their earlier errors. Because the saying goes, we study from the errors we make, and that is definitely true for expertise replay.
Expertise replay buffers are sometimes utilized to off-policy reinforcement studying algorithms by capturing all of the samples generated by an agent interacting with its surroundings after which storing them for later reuse. Crucially, because the agent is off-policy (has a special coaching vs. exploration coverage), the samples replayed from the agent needn’t observe a sequential order.
What are some libraries I can use for Replay Buffers?
Performance for implementing reinforcement studying might be discovered in lots of standard python reinforcement studying environments, akin to:
- TensorFlow Brokers (Replay buffer web page)
- Ray RLLib (Replay buffer API)
- Steady-Baselines (Utilizing a replay buffer with Gentle Actor-Critic)
- Spinning Up (Dwelling web page)
- Keras-RL (Dwelling web page)
- Tensorforce (Replay buffer web page)
Many of those libraries implement replay buffers modularly, permitting for selecting completely different replay buffers to make use of with completely different reinforcement studying algorithms.
Vital advances have been made that construct upon the foundations of expertise replay to additional enhance pattern effectivity and robustness of reinforcement studying brokers. These advances can largely be categorized into two subjects:
(i) Figuring out pattern choice
(ii) Producing new coaching samples.
Every of those, together with a pattern of corresponding examples from literature, is mentioned under.
Figuring out Pattern Choice (PER, LFIW, HER, ERO)
A method for an expertise replay buffer to explicitly handle coaching for a reinforcement studying agent is to present it management over which experiences are replayed for the agent. Some literature examples embrace:
- Prioritized Expertise Replay (PER) [4]: Assigns a numeric “prioritization” worth based on how a lot “shock” an agent would obtain from studying from this expertise. Basically, the extra “shock” (sometimes encoded as TD error) a pattern has, the larger the prioritization weight.
- Chance Free Significance Weights (LFIW) [5]: Like PER, LFIW makes use of TD error to assign a prioritization of expertise. LFIW reweights experiences based mostly on their chance from the present coverage. To stability bias and variance, LFIW additionally makes use of a likelihood-free density ratio estimator between on-policy and off-policy experiences. This ratio is in flip used because the prioritization weight.
- Hindsight Expertise Replay (HER) [6]: Addresses points related to sparse reward environments by storing transitions not solely with the unique purpose used for a given episode but additionally with a subset of different objectives for the RL agent.
- Expertise Replay Optimization (ERO) [7]: Learns a separate neural community operate for figuring out which samples from the replay buffer to pick out. Subsequently, along with the underlying agent’s neural networks (sometimes actor and critic networks), this structure additionally assigns a neural community to find out pattern choice for the opposite learners.
These approaches all management how new samples are chosen for coaching brokers, and in flip, permit for enhancing general coaching for deep reinforcement studying brokers. Somewhat than simply supplying the agent with a random set of experiences to coach on (and subsequently optimize over utilizing gradient optimization strategies), novel expertise replay learns, both heuristically or by means of extra gradient optimization strategies, which samples to offer the agent so as to maximize studying. The replay buffer not solely provides and shops the metaphorical books and classes used to show the agent, however really is in control of deciding which books and classes to present to the agent on the proper instances.
Producing New Coaching Samples (CT, S4RL, NMER)
One other class of expertise replay buffers focuses on producing novel samples for an agent to coach utilizing current samples. Some literature examples embrace:
- Steady Transition (CT) [8]: Performs information augmentation for reinforcement studying brokers in steady management environments by interpolating adjoining transitions alongside a trajectory utilizing Mixup [9], a stochastic linear recombination method.
- Surprisingly Easy RL (S4RL) [10]: Proposes, implements, and evaluates seven completely different augmentation schemes and the way they behave with current offline RL algorithms. These augmentation mechanisms assist to easy out the state area of the deep reinforcement studying agent.
- Neighborhood Mixup Expertise Replay (NMER) (Disclaimer: my analysis) [11]: Equally to CT, NMER recombines close by samples to generate new samples utilizing Mixup. Nonetheless, reasonably than combining temporally-adjacent samples, NMER combines nearest neighbor samples within the (state, motion) area based on a offered distance metric.
Initially, replay buffers had been solely tasked with storing the experiences of an agent, and had little management over what and the way the agent used the samples to enhance its coverage and worth features. Nonetheless, as new expertise replay buffers come out, the replay buffer is gaining an more and more necessary position not simply as an expertise storage mechanism for reinforcement studying brokers, however as a coach and pattern generator for the agent. From the strategies referenced above, in addition to many extra, listed here are a number of instructions I imagine expertise replay is heading in.
- Interpolated Experiences (Disclaimer: This was my principal space of analysis for my Grasp’s Thesis.) — Utilizing current experiences, replay buffers will increase a reinforcement studying agent’s set of experiences obtainable for coaching, resulting in extra strong insurance policies and decision-making.
- Low-bias, Low-variance pattern choice — Replay buffers will additional proceed to enhance how samples are chosen from a replay buffer, to make sure the distribution of expertise they’re implicitly educating to the agent helps the agent study a sensible illustration of the surroundings and its related transition operate/manifold it interacts in.
- Neural Expertise Replay — As seen with some replay buffer approaches akin to ERO, some mechanisms in expertise replay can themselves be realized, and may approximate features when carried out as neural networks! As expertise replay approaches proceed to mature and grow to be extra difficult, I imagine we are going to see continued integration and use of various neural community architectures (MLPs, CNNs, GNNs, and Transformers).
Thanks for studying! To see extra on laptop imaginative and prescient, reinforcement studying, and robotics, please observe me. Contemplating becoming a member of Medium? Please contemplate signing up by means of right here. Thanks for studying!
[1] Fedus, William, et al. “Revisiting fundamentals of expertise replay.” Worldwide Convention on Machine Studying. PMLR, 2020.
[2] Brockman, Greg, et al. “Openai fitness center.” arXiv preprint arXiv:1606.01540 (2016).
[3] Todorov, Emanuel, Tom Erez, and Yuval Tassa. “Mujoco: A physics engine for model-based management.” 2012 IEEE/RSJ Worldwide Convention on Clever Robots and Methods. IEEE, 2012.
[4] Schaul, Tom, et al. “Prioritized Expertise Replay.” ICLR (Poster). 2016.
[5] Sinha, Samarth, et al. “Expertise replay with likelihood-free significance weights.” Studying for Dynamics and Management Convention. PMLR, 2022.
[6] Andrychowicz, Marcin, et al. “Hindsight expertise replay.” Advances in neural info processing techniques 30 (2017).
[7] Zha, Daochen, et al. “Expertise Replay Optimization.” IJCAI. 2019.
[8] Lin, Junfan, et al. “Steady transition: Bettering pattern effectivity for steady management issues through mixup.” 2021 IEEE Worldwide Convention on Robotics and Automation (ICRA). IEEE, 2021.
[9] Zhang, Hongyi, et al. “mixup: Past Empirical Danger Minimization.” Worldwide Convention on Studying Representations. 2018.
[10] Sinha, Samarth, Ajay Mandlekar, and Animesh Garg. “S4RL: Surprisingly easy self-supervision for offline reinforcement studying in robotics.” Convention on Robotic Studying. PMLR, 2022.
[11] Sander, Ryan, et al. “Neighborhood Mixup Expertise Replay: Native Convex Interpolation for Improved Pattern Effectivity in Steady Management Duties.” Studying for Dynamics and Management Convention. PMLR, 2022.
