Two years in the past, I attempted to construct a SaaS product for monitoring machine studying fashions. Fortunately for you, that product went nowhere, so I figured I should share some code quite than let it proceed to fester in a personal GitHub repo.
The monitoring service was designed to ingest knowledge associated to mannequin predictions and mannequin outcomes (aka “gold labels” aka “floor fact” aka “what really occurred”). The service would then be part of and clear this knowledge and ultimately spit again out a bunch of metrics related to the mannequin’s predictive efficiency. Beneath the hood, the service was simply an unmagical ETL system. Glorified knowledge laundering, if you’ll.
Central to my operation was an occasion collector. Naively, I believed that many machine studying groups had been working on the planet of real-time predictions, so I constructed an API for them to POST their predictions to on the fly when the mannequin ran. In actuality, most groups had been working on the planet of batch predictions and nonetheless are (professional tip: speak to folks earlier than you construct issues).
Whereas possibly not but helpful for ML monitoring, I’m going to spend this put up describing how the occasion collector works. I really feel prefer it’s straightforward to learn weblog posts on firms’ tech blogs with fancy diagrams of their large system, however, whenever you go to construct a system your self, there’s an enormous chasm between obscure diagrams and precise code. So, I’ve constructed, deployed, and open sourced an occasion collector only for this weblog put up.
The occasion collector is powering the “dashboard” beneath exhibiting how many individuals have visited this web page and what number of have clicked on the Click on Me button. The complete code is offered in my serverless-event-collector repo do you have to need to replicate this your self.
Web page Views: …
Button Clicks:
Why Serverless?
As a result of I’m low-cost and don’t worth my time.
In hindsight, going serverless was a horrible concept. Throughout growth, I didn’t need any mounted prices (I had no funding or earnings), and horizontal scalability was enticing. I figured I may all the time port my serverless code over to devoted servers if the economies of scale made sense. The piece that I didn’t issue into my calculation was the truth that it might take me a lot longer to put in writing serverless code. The largest slowdown is the iteration loop. Numerous magical issues occur beneath the serverless hood, so it may be onerous to debug your code regionally. However, it will possibly take some time in your code to deploy, therefore the gradual iteration loop.
Seeing as I finally shut down my mission and received an actual job, I may have saved considerably more cash if I had constructed quicker, stop sooner, and began cashing paychecks a pair months earlier.
Regardless of my negativity, it’s nonetheless actually fucking cool that you are able to do issues with code the place scale is an afterthought and price can robotically spin all the way down to zero. The latter is what permits me to not suppose twice about deploying my toy occasion collector for the sake of this foolish weblog put up.
Necessities Earlier than Implementation
Earlier than I reveal the soiled secrets and techniques of my knowledge operation, let’s first speak by the necessities for stated system:
- I would like a means for the occasion collector to obtain occasions (aka knowledge) from the consumer.
- I must authenticate the consumer. Randos shouldn’t have the ability to ship knowledge to a different consumer’s account.
- I may have quick entry to details about the occasions, comparable to the overall variety of occasions.
- I must retailer the occasions someplace such that they are often queried later.
Given the above necessities, let’s speak implementation.
Present Me the Diagram
Among the best classes I used to be taught about writing mission and design docs at work was to attract a rattling diagram. So please, benefit from the occasion collector diagram beneath.
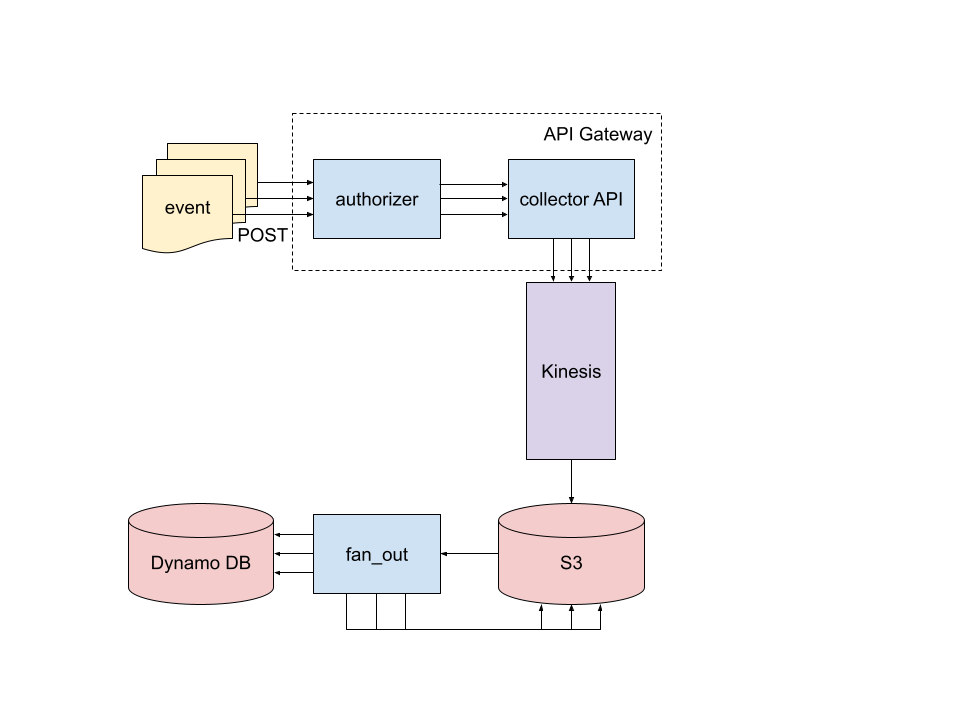
What’s occurring right here? We’ll begin on the higher left and carry out a whirlwind tour. Alongside the way in which, I’ll mark off every of the resolved aforementioned necessities.
Occasions are POSTed as JSON-serialized knowledge to a public going through API (this resolves requirement 1️⃣). The API lives in API Gateway and consists of two Lambda features: the authorizer checks the Fundamental Authentication data within the request and permits or denies the request (2️⃣). Allowed requests get forwarded to the collector Lambda operate which is definitely a FastAPI server deployed as a Lambda operate. collector validates the request after which drops it into Kinesis Firehose which is a Kafakaesque managed service. collector additionally updates DynamoDB tables which keep a rely of every occasion kind for every consumer. These tables are used to energy endpoints for GETting actual time occasion counts and are how the dashboard for this weblog put up will get populated (3️⃣).
Batches of occasions from Kinesis get dropped right into a bucket on S3. Objects created in that bucket set off the fan_out Lambda operate during which occasions from the principle Kinesis bucket get copied into user-specific buckets partitioned by event-type and time (4️⃣).
The whole serverless occasion collector is deployed collectively utilizing the serverless framework with full configuration outlined in serverless.yml.
Respect My Authority
When the consumer sends an occasion to the occasion collector, they have to first get previous the authorizer. The consumer offers their username and password by way of Fundamental Authentication. The requests library helps this with the auth argument:
import requests
url = ...
payload = {...}
username = ...
password = ...
response = requests.put up(
url, json=payload, auth=(username, password)
)
The authorizer is an API Gateway Lambda authorizer (previously often known as a customized authorizer), and it checks if the username and password are legitimate. In manufacturing, I might suggest storing the consumer’s password in one thing like AWS Secrets and techniques Supervisor. The authorizer can then lookup the consumer’s password and ensure that the offered password is appropriate. AWS Secrets and techniques Supervisor has a set value per 30 days for every saved secret. Whereas the fee is small, I wished to attenuate the price of this weblog put up, so I simply hardcoded a username and password into my authorizer.
The authorizer returns a particularly formatted response which tells API Gateway whether or not or not the consumer has entry to the requested API endpoint. Under reveals an instance response permitting the consumer entry to all POST requests to the collector API.
{
"Model": "2012-10-17",
"Assertion": [
{
"Action": "execute-api:Invoke",
"Effect": "Allow",
// account_id:api_id/stage
"Resource": "arn:aws:execute-api:us-east-1:0000000000:XXXYYY/prod/POST/*"
}
]
}
There are a pair different helpful methods you’ll be able to make use of with a Lambda authorizer. You’ll be able to cache the authorizer response for a given enter. This manner, you do not need to waste time or cash calling the authorizer operate (and doubtlessly AWS Secrets and techniques Supervisor) for each API name. To cache the response, set the authorizerResultTtlInSeconds parameter for the authorizer to the variety of seconds to cache the response for. Then, return a usageIdentifierKey area within the authorizer response. The worth ought to correspond to the enter that you just need to cache. For instance, you could possibly return the username and password because the usageIdentifierKey in order that any future requests utilizing the identical username and password will hit the cache as a substitute of calling the authorizer.
The opposite trick you’ll be able to make use of is which you could return a context area within the response which will probably be forwarded on to the precise API that the consumer is looking (the collector, in our case). In my authorizer, I add the username to the context in order that the collector API has entry to the username with out the consumer having to explicitly present it of their occasion knowledge.
Shifting to Collections
Licensed occasions make it to the collector API which validates the occasion knowledge, drops the occasion right into a Kinesis queue, and updates related DynamoDB tables for real-time statistics. Through the use of the FastAPI framework for the collector API, we get knowledge validation and API docs without cost. Let’s check out how this all works with some simplified code exhibiting the endpoint for monitoring button clicks.
import time
from fastapi import APIRouter, Request
from pydantic import BaseModel
from collector.context_utils import get_username
from collector.dynamo import ButtonClickCounter, update_count
from collector.kinesis import put_record
router = APIRouter(prefix="/button")
class ButtonClick(BaseModel):
session_id: str
button_id: str
@router.put up("/click on", tags=["button"])
def button_click(button_click: ButtonClick, request: Request):
report = button_click.dict()
report["username"] = get_username(request)
report["event_type"] = "button_click"
report["received_at"] = int(time.time() * 1_000) # Milliseconds since Unix epoch
put_record(report)
update_count(ButtonClickCounter, report["username"], report["button_id"])
return {"message": "Obtained"}
After some library imports, a router is instantiated. This can be a FastAPI object that is sort of a Flask blueprint, for those who’re aware of these. The principle concept is that each endpoint outlined with the router object will reside beneath the /button prefix. The endpoint proven will probably be at /button/click on. Routers assist you to logically group your endpoints and code.
After the router, the ButtonClick pydantic mannequin is outlined. FastAPI is well-integrated with pydantic, which is a superb library for kind hint-based knowledge validation. By setting the kind trace for the button_click argument within the button_click() operate to the ButtonClick pydantic mannequin, we be sure that JSON POSTed to the button/click on endpoint will probably be transformed right into a ButtonClick object, and the conversion will probably be validated towards the anticipated keys and kinds. Jesus, who named every little thing “button click on”?
The button_click() operate homes the code that runs when the /button/click on endpoint is POSTed to. Some further data like a timestamp will get added to the occasion report, the report is put right into a Kinesis queue, the DynamoDB ButtonClickCounter desk is up to date, and eventually a response is returned to the consumer.
Fan Out
Why do occasions get dropped right into a Kinesis queue? I don’t know. I initially did it as a result of it appeared like the longer term wanting, scalable factor to do. Really, it ended up simply being a handy technique to transition from working on particular person occasions to batches of occasions. Kinesis will batch up information based mostly on time or storage dimension (whichever restrict will get hit first) after which drop a batch of occasions into S3.
The creation of this file containing the batch of occasions triggers the fan_out Lambda operate. This operate just isn’t significantly fascinating. It “followers the information out” from the principle Kinesis S3 bucket into particular person buckets for every consumer. The information then get partitioned by event_type and time and land at a path like
button_click/12 months=2021/month=6/day=1/hour=13/some_record_XYZ
I partitioned by time in that method as a result of then you’ll be able to run a Glue crawler over the bucket, and your generated desk will robotically have time partitions as column names. As soon as the desk has been generated, you’ll be able to then question the information in Athena.
SOServerless
So I’ve talked about a pair Lambda features making up this serverless occasion collector: authorizer, collector, and fan_out. The occasion collector could be thought-about serverless as a result of it principally simply depends on these Lambda features. I’d contemplate the occasion collector to be much more serverless-y as a result of I provision the Kinesis queue and DynamoDB tables in order that I solely pay after I learn or write to them. The one actual mounted value is the S3 storage value, and that is fairly minimal until this weblog put up actually blows up.
In the event you’re going to make a system out of Lambda features, you then actually shouldn’t manually zip up and deploy your Lambda features. Life’s too quick for this, and whereas it might not be too unhealthy the primary time, it’s going to be a ache whenever you inevitably must replace issues or roll again your modifications. When you have quite a lot of AWS issues to create, then it’s best to in all probability use Terraform or CloudFormation. In the event you solely have a pair issues, then ask your native DevOps knowledgeable if the annoyingly named serverless framework is best for you.
So far as I can inform, serverless is a command line node library that converts declarative YAML into declarative CloudFormation (we could name this a transpiler?). It’s comparatively easy for easy issues, and complicated for me for sophisticated issues. I believe it’d be much less complicated I may debug by studying the generated CloudFormation, however then I’d in all probability simply use CloudFormation, so yeah.
I used to be planning to elucidate a bunch of stuff about my serverless YAML file, however I’m sort of sick of gazing it, so I’ll simply say “Go take a look at the serverless.yml file within the repo for those who’re ”.
I ought to point out that serverless isn’t just for Lambda features. My complete occasion collector will get deployed with serverless. That features hooking all the collector endpoints as much as API Gateway and putting the authorizer in entrance, creating the Kinesis queue, creating the bucket for Kinesis occasions, and attaching the fan_out operate to the Kinesis bucket. It took some time to get this all working, nevertheless it’s good that I can now create all the system with a easy serverless deploy command.
One tough bit was deploying a FastAPI server as a Lambda operate on API Gateway. serverless really has fairly good assist for hooking up Lambda features to API Gateway. If you wish to deploy a Flask app to API Gateway, then there’s a serverless-wsgi plugin for that. The wrinkle for FastAPI is that it’s an ASGI server.
Fortunately, the Mangum library makes this comparatively painless. All it’s a must to do is wrap your FastAPI app with a Mangum class like so:
from mangum import Mangum
from my_fastapi_service import app
handler = Mangum(app)
and you then reference the handler object as your handler for the Lambda operate that you just’re deploying with serverless.
Oh hey keep in mind how I stated doing issues serverless was a ache? I in some way forgot to complain sufficiently about this.
There have been a zillion points with doing issues serverless.
I’m not even certain if all the problems had been because of the serverlessness of my system as a result of typically it’s onerous to know! I had all types of CORS points, points with the FastAPI root_path, python packaging points for Lambda features, points between CORS and the Lambda authorizer, IAM points, and did I point out CORS? Perhaps the issue isn’t a lot the serverlessness as it’s utilizing many various AWS merchandise collectively versus a superb ol’ EC2 occasion.
Someday, we’ll program on the cloud like we program on working techniques. Till then, have enjoyable gazing ARNs.

{kind=link}