
Deep Q-Community defined

Deep Reinforcement Studying (DRL) has been underneath the spotlights for the previous few years within the Synthetic Intelligence area. Within the gaming world, a number of robots (a.okay.a brokers or fashions in the remainder of the publish) like AlphaGo for the sport of Go or AlphaStar for StarCraft and Open AI 5 for Dota video video games, simply to call just a few well-known ones, have proven that with a intelligent mixture of deep neural networks representational energy and the reinforcement studying framework, it was doable to dominate skilled avid gamers’ leagues.
DRL shouldn’t be restricted to video games, it additionally has proven nice potential on extra sensible points like logistics, biology, digital design and even in guiding plasma manipulation in fusion reactor, displaying that beforehand intractable issues might be deal with by “super-human” agent.
Figuring out that, I used to be very curious to grasp how such outcomes might be reached. As all the time, ranging from the underside of the self-discipline has helped me loads to understand basic ideas and construct an understanding of DRL earlier than digging in its extra complicated structure. Thus, this publish goal is to give attention to the idea and clarify some main ideas of the Deep Q-Community (DQN), considered one of DRL basis algorithms, to grasp how Deep Studying & Reinforcement Studying (RL) articulate collectively to construct such super-human agent.
Earlier than transferring additional on this publish, I assume the readers to be already acquainted with RL basic ideas and vocabulary. If not, one can first examine this nice UCL course on RL or this introduction from yours really:
👾 🎮 Area-Invaders (S-I) is a online game from the well-known Atari 2600 console (Determine 1). This online game is extensively used for benchmarking DRL fashions.
In S-I you pilot a bit spaceship and should destroy, by capturing at them, as a lot alien’s spaceships as you’ll be able to earlier than they destroy you. We are going to use S-I recreation as a toy atmosphere for instance the RL ideas we cowl on this publish.

As we already talked about, the taking part in agent will probably be fabricated from DRL bricks. It’ll study to play S-I immediately by watching uncooked photos of the sport and reacting consequently by selecting an motion over all of the doable actions (like a human would do).
To grasp these DRL bricks behind the agent, we dissect 3 main papers from DeepMind (listed under of their chronological order of publication), on the very coronary heart of many fashionable DRL approaches:
Let’s begin our journey by wanting immediately within the lion’s den (Algorithm 1 under👇).

Gosh 😱! It appears to be like fairly scary at first sigh… However no worries, we’ll undergo it line by line and unpack every idea.
First issues first, in Deep Q-Community now we have a Q. And, to start with Sutton & Barto created the Q-function. The Q- operate (a.okay.a. the state-action worth operate), maps a few <state, motion> to a worth (or anticipated reward).
In plain English, the Q-function tells you the way good is an motion you need to take given the precise state you’re in. Determine 2 under illustrates this definition with a concrete instance within the S-I atmosphere.

As soon as the Q-function related to an atmosphere is thought, the agent can all the time select the motion that results in the utmost anticipated reward, therefore following what known as the optimum coverage on this atmosphere. It’s the data of the optimum coverage that makes an agent attain super-human efficiency.
S-I recreation is just like a Markov Choice Course of (MDP) atmosphere. RL researchers have theorized a number of methods of discovering the optimum coverage in such atmosphere. Within the DQN agent, the Q-learning method is used to search out the optimum Q-function. So let’s dive a bit within the maths behind this method to decompose the totally different steps that lead us to the core a part of the Algorithm 1.
By definition, the Q-function equation has been posed as a recursive (dynamic programming) drawback by Bellman:

Bellman equation states that the Q-function for an motion a in a state s will be break down into 2 components:
- an quick reward
- a reduced future anticipated reward
This primary equation will be derived in Equation (2) under by creating the expectation operate because the weighted common of the state transition’s chances over all doable subsequent states and because the weighted common of the chances of selecting any doable actions in a particular state following our present coverage.

Truly, our S-I atmosphere will be seen as a deterministic atmosphere. Certainly, transferring to the left when pushing the left button is definite. Due to this fact, it allows us to eliminate the state transition’s chances.

Now that now we have derived the Q operate equation, let’s bear in mind we’re on the lookout for the optimum Q operate (with the very best worth). It means we don’t need to have a look at all of the doable actions anymore however solely the one maximizing the anticipated reward. One pure proxy is to have a look at the utmost anticipated reward, therefore (4) under:

Mathematically talking, the optimum Q operate ought to respect the equality seen in (4).
From the theoretical optimum Q-function definition (4), Q-learning derives an iterative algorithm that converges to an estimate of the optimum Q-function utilizing the next replace step:
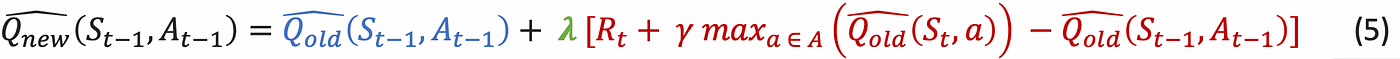
- In purple, the TD-error : it’s the hole between two temporally totally different estimations. The nearer to 0 the nearer to optimality therefore the smaller replace; the larger the additional to optimality therefore the larger replace.
- In inexperienced, the studying price λ, tells by how a lot we need to replace the outdated estimated Q-value.
- In blue, the outdated estimated Q worth which is up to date.
To summarise in plain english the final equation (5): Q-learning iteratively updates the estimated Q-values in direction of the route of optimality. By the tip of this iterative course of, it converges to the optimum Q-function.
You noticed it coming right here (or possibly Deep Q-Community shouldn’t be specific sufficient 🙃). It’s certainly, the makes use of of Deep Neural Networks (DNN), well-known for being Common Perform Approximators. On high of that, DNN are notably environment friendly when coping with unstructured knowledge comparable to photos (in comparison with extra conventional ML approaches). Notice that in the remainder of the publish we’re utilizing interchangeably DQN and DNN phrases to check with the agent’s mannequin (on condition that DQN is a DNN).
Let’s bear in mind we’re utilizing immediately the photographs stream of the S-I online game for the agent to study the optimum Q-function. And so the query is the next:
Why not use a DNN because the Q-function approximator?
Let’s see how you can leverage DNN’s representational energy in a Q-function approximation job. And since an image is price a thousand phrases, right here is (on Determine 3 under 👇) the recipe of how S-I recreation photos are processed by the DNN to output values (Q-values to be exact) related to the doable recreation actions.
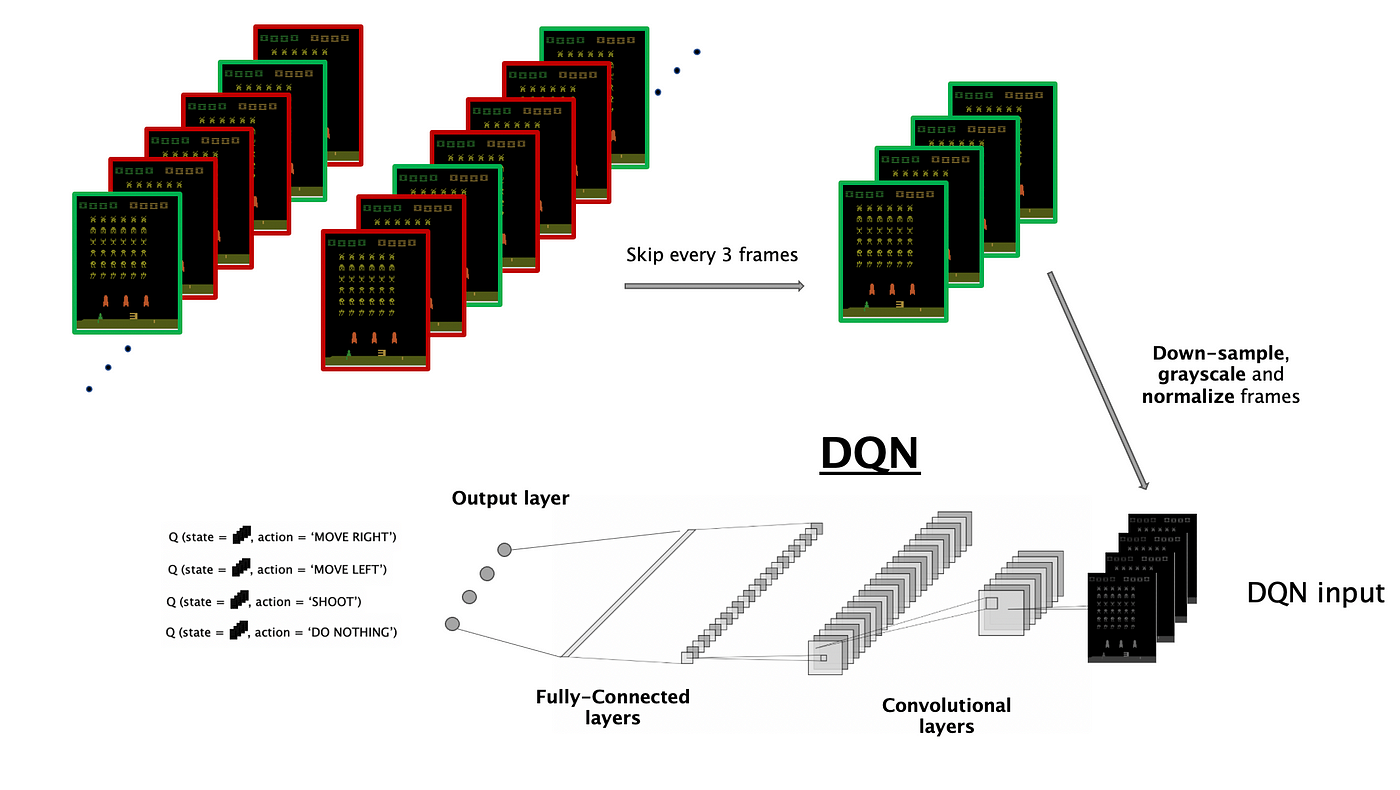
- skipping frames: very shut state (or transition) doesn’t carry a lot data, we favor to discover extra totally different patterns quite than amassing extremely correlated transitions, which might output very shut Q-values. Moreover, it’s cheaper to run the sport engine for fewer frames quite than computing the Q-value for all these extremely correlated transitions. Therefore, extra totally different episodes are run utilizing this system.
- down sampling, grayscaling & normalizing: in ML it’s a widespread observe to comply with these pre-processing steps with a purpose to cut back the compute wanted to study from photos and to maintain pixels illustration at comparable scale.
- DQN enter: the 4 frames coming from S-I are used because the DNN enter, they’re known as a state or transition.
- convolutional layers: studying informative options from uncooked photos is strictly within the scope of neural networks, extra particularly convolutional neural networks (CNN) that are dominating the sector in pc imaginative and prescient.
- output layer: the ultimate layer of the DNN provides 4 scores related to every 4 potential actions (the upper rating the higher motion).
That’s was a pleasant visualization of how the photographs are processed, however to make a DNN study the ultimate ingredient is a loss operate. Nothing too fancy right here, the loss used is an tailored Imply Sq. Error (the TD-MSE, see equation (6) on Determine 4 under) that makes use of the estimated optimum Q-function. Lastly, a traditional stochastic gradient descent is used to replace the DNN networks weights in direction of the loss’ minimal on equation (7).

To this point so good. Now let’s see why the purple parameters (on Determine 4 ⬆️ ) are saved frozen when differentiating the loss through the gradient descent replace step.
If we appropriately understood the equation (6), the targets/labels we use within the loss come from the identical mannequin we replace. In different phrases, the mannequin is studying from its personal predictions… Isn’t that unusual like a snake biting its tail? ♾️
It does sound bizarre at first sight. But when we consider it, it’s like utilizing our greatest guess (up to now) of the estimated optimum Q-function. And on condition that Q-learning iteratively converges to the optimum Q-function, we are able to anticipate our noisy estimations initially to change into increasingly more coherent, iteration after iteration.
Theoretically this is able to work if and provided that the mannequin provides more and more related targets whereas coaching.
Sadly, in observe it doesn’t work so nicely. Certainly, at every studying step, the mannequin’s weights are up to date and may trigger an enormous change within the targets predictions for 2 related states, stopping the DNN to effectively study.
E.g, for 2 successive studying steps, given a really related enter state, the DNN may decide totally different optimum actions… that means our targets are inconsistent. 😢
This inconsistency, generally known as the transferring goal subject, results in studying instability. That’s the place comes the thought of utilizing 2 networks:
- on-line community: the training community which is up to date each step
- goal community: a replica of the web community, which is saved frozen for a number of steps with a purpose to make sure that targets stay steady
This on-line/goal networks workflow is defined on Determine 5 under ⬇️
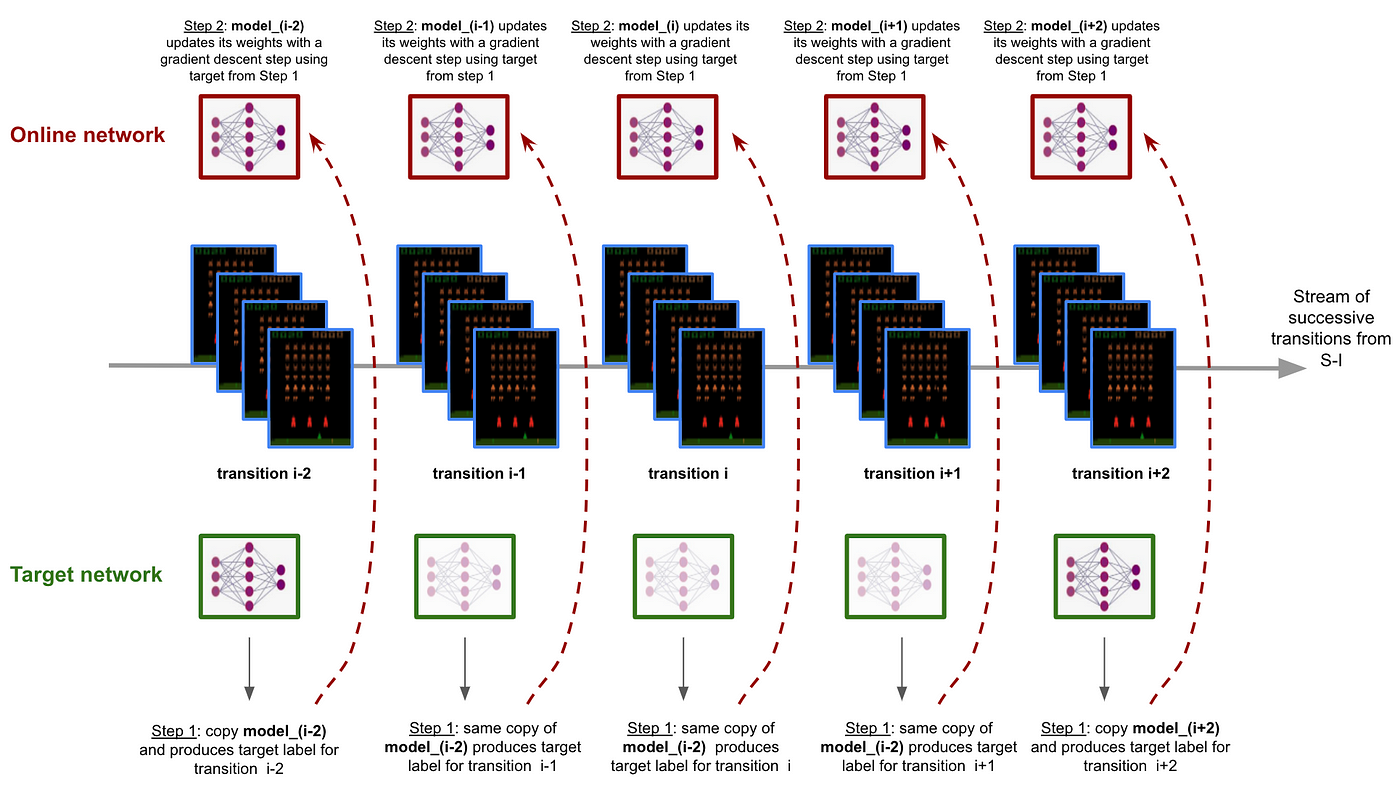
- Step 1: the goal community produces the goal of a given transition
- Step 2: the web mannequin learns from the goal produced by the goal community
Following the web/goal networks method ensures steady targets for the DNN to study.
We’re beginning to see it, to mix Deep Studying and Reinforcement Studying, we should make sure the DNN an environment friendly studying regime. So let’s see the opposite engineering methods essential to unleash full DNN energy ! 💥
Once more, one other impediment falls on the best way to DQN studying and convergence.

Trying again on the Q-learning optimality (equation (4) above), we are able to see the Q-value of a <state, motion> couple is dependent upon the most Q-value over all of the doable actions of the subsequent state (purple phrases on equation (4)). Which means that, in Q-learning, the max worth over all doable actions is a related proxy to estimate the worth of a state.
Being so assured that the max worth is an accurate estimation for a state’s worth is named being biased in direction of the max. And that’s what’s illustrated within the toy instance on Determine 6 under 👇
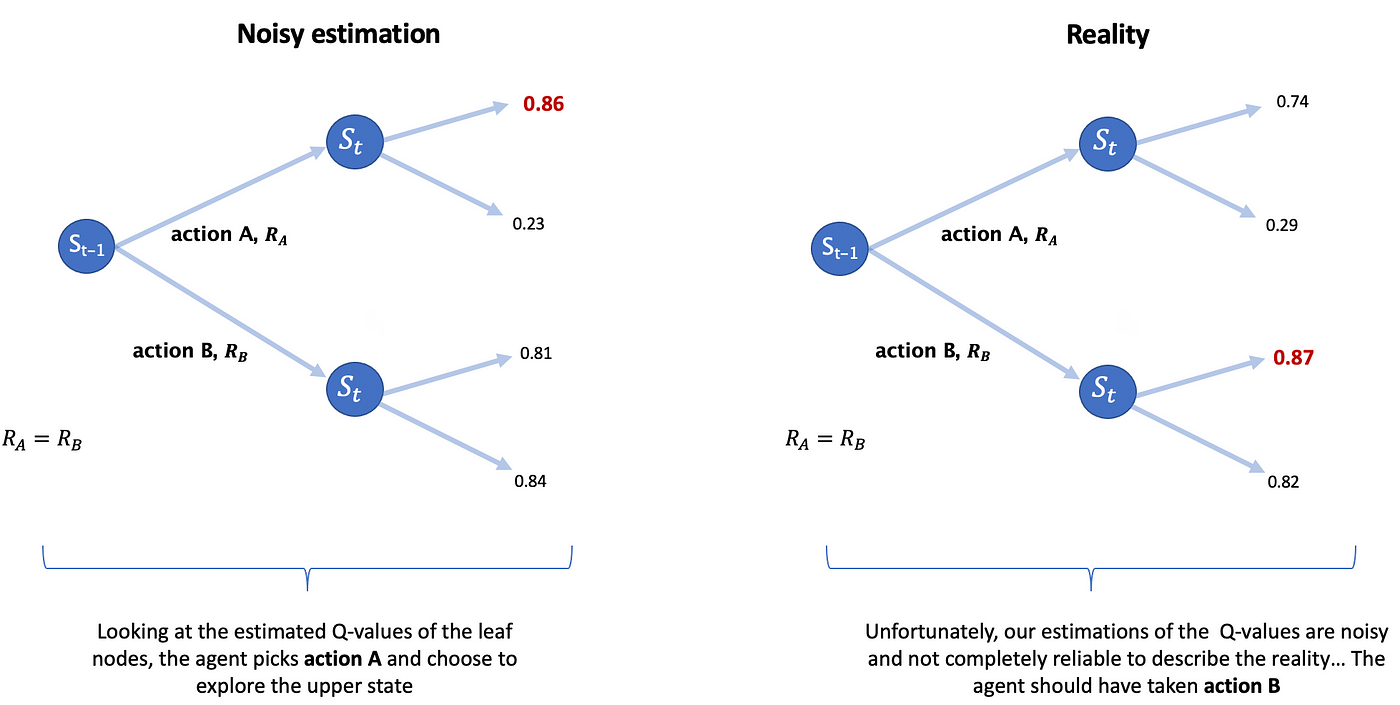
In brief, being biased in direction of the max makes the agent decide uninteresting actions and discover improper route, which can result in a slower mannequin’s convergence and a deterioration of its studying regime.
NB: These noisy estimations are not random since they’re coming from a single mannequin, which all the time overestimates the identical actions given related states. In any other case it wouldn’t have generated this bias.
The concept of Hado van Hasselt to right this bias was to make use of 2 operate approximators in parallel (therefore the title Double Q-learning):
- one for the max motion choice at a given state
- one other for the Q-value compute related to this chosen max motion
Certainly, utilizing two brokers brings the so longed-for randomness in our noisy estimations. Let me clarify 🤓
The 2 fashions don’t overestimate the identical actions in the same given state since they’ve been skilled in another way, so utilizing one to pick out an motion and one other to calculate the related <state, chosen motion> worth combined up the 2 fashions’ noise in a random method, and consequently debias the worth estimation.
To keep away from having too many networks and obfuscate the general coaching structure (we have already got the On-line and Goal networks 😅 !), it has been proven that utilizing the On-line community because the Q-value pc and the Goal community because the max motion selector is working high-quality for the agent studying potential.
To this point, it was taken as a right that DQN was studying from the stream of successive transitions… Let’s assume once more.
If we took a bunch of successive transitions, more often than not, they’d look fairly the identical. In ML, we’d say that successive transitions are extremely correlated… And feeding correlated enter to a DNN decelerate its studying by making the DNN successively overfit on few correlated examples. Certainly, everyone knows {that a} shuffle the dataset is significantly better for the mannequin to converge 🙏
So right here involves the rescue the Expertise Replay process (defined on Determine 7 under) to interrupt the correlation of the enter transitions fed to the DNN.
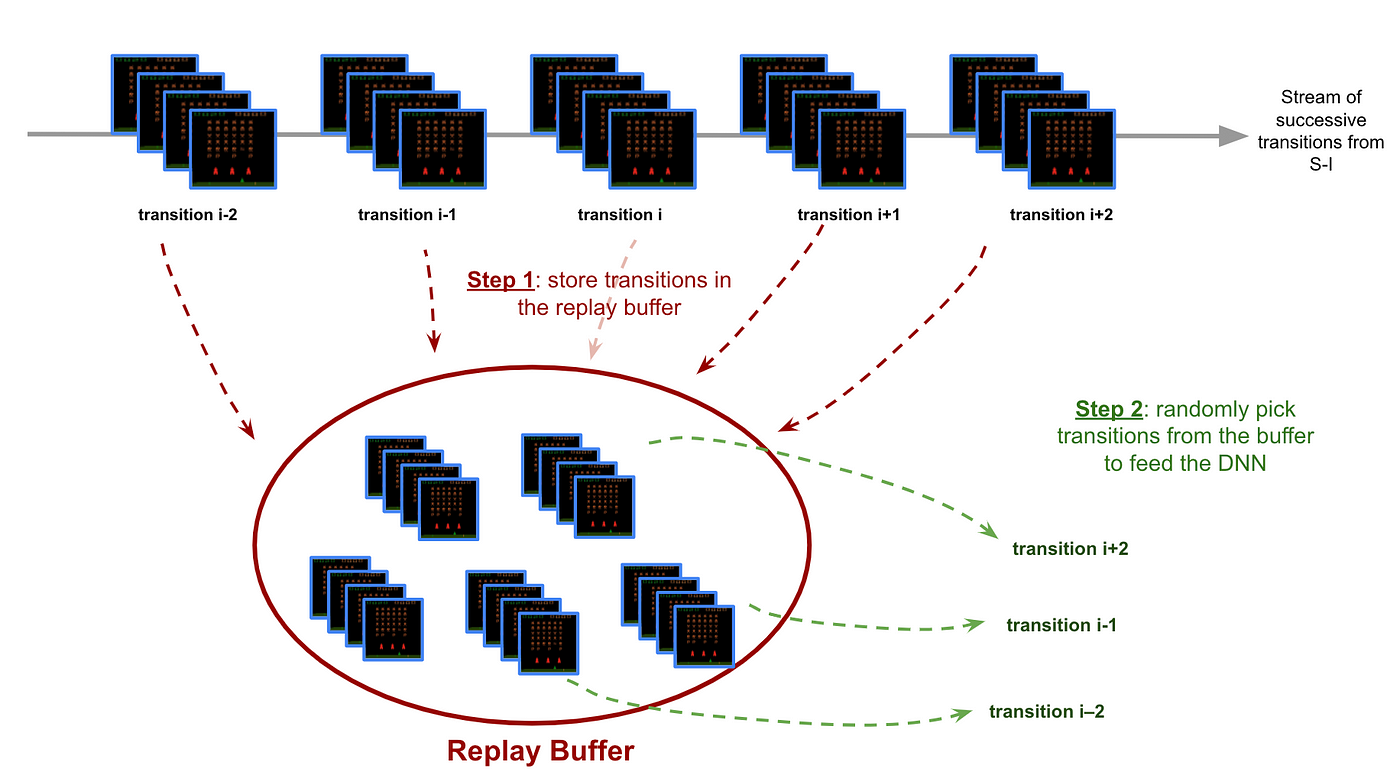
NB: Replaying reminiscences is an actual neuroscience phenomenon that takes place within the hippocampus (at the very least for rodents 🐭).
For this one, the whole lot is within the title. Certainly, as a substitute of sampling uniformly from the replay buffer, the transitions are sampled with a precedence concerning how attention-grabbing are transitions for the agent. In brief, extra attention-grabbing transitions have the next likelihood of being sampled.
First, what does attention-grabbing imply for the agent? It occurs that for some transitions the agent is performing a lot worse than for others. Which means the agent’s TD-error is increased for these transitions. Thus, the thought behind PER is to give attention to these poorly predicted transitions (a.okay.a attention-grabbing transitions) with a purpose to enhance the agent’s studying.
All the time practice in your weaknesses 🦾 #protips
Determine 8 under exhibits how the precedence rating of a transition is computed. As soon as a transition is sampled, its TD-error (and its precedence rating consequently) is straight away up to date by the training agent.

Nevertheless, such prioritization within the sampling technique additionally results in a disturbance of the agent studying regime. Certainly, rehashing time and again transitions with excessive TD-error makes the agent overfit on these poorly predicted examples resulting from lack of variety. On high of that, prioritization deviates the enter transitions distribution from the true transitions distribution and subsequently introduces a bias that disturbs the DNN convergence.
However no worries, as normal some intelligent spells had been discovered to take care of these curses 🧙♂️
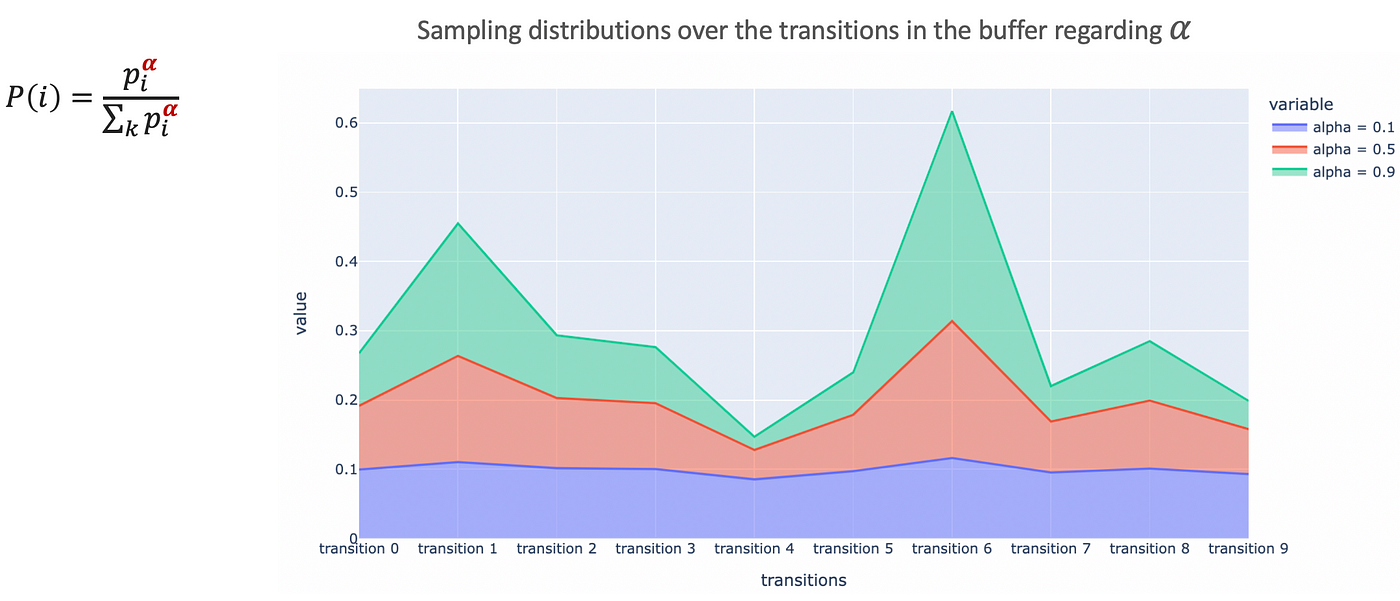
- Stochastic Prioritization avoids the shortage of variety subject by smoothing the uncooked precedence scores distribution to permit some low TD-error’s transitions to be sampled (examine on Determine 9 under)
- Significance-Sampling enters the ring to re-weigh how a lot the agent’s parameters are up to date in Deep Q-learning with a purpose to compensate the distribution shift brought on by prioritized sampling. The nearer β is to 1 the extra it compensates.

With the ability to tune the 2 parameters α and β through the coaching enhances the agent’s studying potential and its sooner convergence to the optimum coverage
NB: Repeated prioritized sampling and updating these priorities have a linear complexity O(n). But, in DRL, an enormous quantity of transitions should be explored for the agent’s studying, thus this linear sampling complexity creates a bottleneck within the total coaching process. So to beat this engineering subject, a particular knowledge construction was used for the prioritized buffer: the SumTree which improves the sampling complexity from O(n) to O(log(n)).

{kind=link}