
Last year we released Staging Ground to assist new question-askers get suggestions on their drafts from skilled customers in a devoted area earlier than their query is posted publicly on Stack Overflow. We’ve since seen measurable enhancements within the high quality of questions posted; nonetheless, it nonetheless takes time for a query to get human suggestions and make it by the total Staging Floor course of.
Reviewers additionally observed that they have been repeating the identical feedback again and again: this submit doesn’t belong right here, there’s context lacking, it’s a reproduction, and many others. In basic Stack Overflow trend, there are even remark templates they will apply for the correct conditions. This seemed like a possibility to make use of machine studying and AI to establish these frequent circumstances and pace up the method so human reviewers may spend their time tackling the extra nuanced circumstances. Because of our partnership with Google, we had a strong AI software (Gemini) to assist us take a look at, establish, and produce automated suggestions.
In the long run, we discovered that evaluating query high quality and figuring out the suitable suggestions required some basic ML methods along with our generative AI resolution. This text will stroll by how we thought-about, applied, and measured the outcomes of Question Assistant.
LLMs can present quite a lot of helpful insights on textual content, so we have been naturally curious if they may produce a top quality score for a query in a specific class. To start out, we used three classes and outlined them in prompts: context and background, anticipated end result, and formatting and readability. These classes have been chosen as a result of they have been the commonest areas wherein reviewers have been writing the identical feedback repeatedly to assist new askers enhance their questions in Staging Floor.
Our checks with LLMs confirmed they may not reliably predict high quality rankings and supply suggestions that correlated with one another. The suggestions itself was repetitive and didn’t correspond with the class—for instance, all three classes would repeatedly embody suggestions in regards to the model of the library or programming language, which was not precisely helpful. Worse nonetheless, the standard score and suggestions wouldn’t change after the query draft was up to date.
For an LLM to reliably charge the standard of a query when the idea itself is subjective in nature, we wanted to outline, by information, what a top quality query is. Whereas Stack Overflow has tips for how to ask a good question, high quality shouldn’t be one thing that may be simply translated right into a numerical rating. That meant we wanted to create a labeled dataset that we may use to coach and consider our ML fashions.
We began by attempting to create a floor reality information set, one which contained information on find out how to charge questions. In a survey despatched to 1,000 question-reviewers, we requested them to charge the standard of questions on a scale of 1 to five within the three classes. 152 members absolutely accomplished the survey. After working the outcomes by Krippendorff’s alpha, we received a reasonably low rating, which meant this labeled information wouldn’t make dependable coaching and analysis information.
As we continued exploring the information, we got here to the conclusion {that a} numerical score doesn’t present actionable suggestions. If somebody will get a 3 in a class, does that imply they should enhance it with a view to submit their query? The numerical score doesn’t give context for what, how, or the place the query must be improved.
Whereas we wouldn’t be capable to use an LLM to find out high quality, our survey did affirm the significance of the suggestions classes for that goal. That led us to our various method: constructing out suggestions indicators for every of the beforehand talked about classes. Slightly than predicting the rating immediately, we constructed out particular person fashions that may point out whether or not a query ought to obtain suggestions for that particular indicator.
As a substitute of utilizing solely an LLM with the potential for a variety of responses and generic outputs, we created particular person logistic regression fashions. These produce a binary response based mostly on the query title and physique. Basically: Does this query want a selected remark template utilized to it or not?
For our first experiment, we selected a single class to construct fashions for: context and background. We broke the class into 4 particular person and actionable suggestions indicators:
- Downside definition: The issue or aim is missing info to know what the consumer is attempting to perform.
- Try particulars: The query wants extra info on what you’ve got tried and the pertinent code (as related).
- Error particulars: The query wants extra info on error messages and debugging logs (as related).
- Lacking MRE: Lacking a minimal reproducible instance utilizing a portion of your code that reproduces the issue.
We derived these suggestions indicators from clustering reviewer feedback on Staging Floor posts to search out the frequent themes between them. Conveniently, these themes additionally matched our present remark templates and query shut causes, so we may use previous information in coaching a mannequin to detect them. These reviewer feedback and shut feedback have been all vectorized utilizing term frequency inverse document frequency (TF IDF) earlier than passing in these options to logistic regression fashions.
Though we have been constructing extra conventional ML fashions to flag questions based mostly on high quality indicators, we nonetheless wanted to pair it with an LLM within the workflow to offer actionable suggestions. As soon as an indicator flags a query, it sends a preloaded response textual content with the query to Gemini, together with some system prompts. Gemini then synthesizes these to provide suggestions that addresses the indicator, however is particular to the query.
This mermaid diagram reveals the circulate:
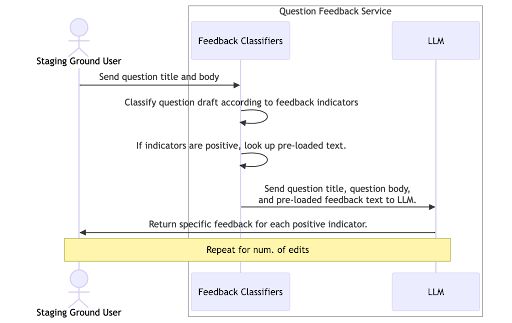
We skilled and saved these fashions inside our Azure Databricks ecosystem. In manufacturing, a devoted service on Azure Kubernetes downloads from Databricks Unity Catalog and hosts the fashions to generate predictions upon suggestions request.
Then our fashions have been prepared to begin producing suggestions.
We ran this experiment in two phases: first on Staging Floor solely, then on stackoverflow.com for all query askers with Ask Wizard. To measure success, we collected occasions by Azure Occasion Hub and logged predictions and outcomes to Datadog to know whether or not or not the generated suggestions was useful for the consumer, and to enhance future iterations of the indicator fashions.
Our first experiment was in Staging Floor, the place we may give attention to new askers who possible wanted probably the most assist drafting their first query. We ran it as an A/B take a look at, the place all eligible Staging Floor askers have been allotted for the experiment, cut up 50/50 between the management and variant teams. The management group didn’t obtain help from Gemini, whereas the variant group did obtain help from Gemini. Our aim was to see if the Query Assistant may improve the variety of questions authorized to the principle website and cut back the time questions spent in assessment.
The outcomes of the experiment have been inconclusive based mostly on our authentic aim metrics; neither approval charges nor common assessment instances improved considerably for the variant group in comparison with the management. However it seems that this resolution really solves a unique drawback. We noticed a significant improve in success charges for questions; that’s, questions that keep open on the location and obtain a solution or a submit rating of at the least plus two. So whereas we didn’t discover what we have been initially in search of, the experiment nonetheless validated that Query Assistant had worth to askers and a constructive influence on query high quality.
For the second experiment, we ran the A/B take a look at on all eligible askers on the Ask Question web page with the Ask Wizard. This time, we needed to verify the outcomes of the primary experiment and see if Query Assistant may additionally assist extra skilled question-askers.
We noticed a gentle success charge of +12% throughout each experiments. With the significant success charges and consistency of our findings, we made Query Assistant out there to all askers on Stack Overflow on March 6, 2025.
Altering course shouldn’t be unusual in analysis and early growth. However realizing while you’re on a path that received’t present influence and pivoting to new logic is vital to creating positive all of the puzzle items nonetheless match collectively, simply differently. With conventional ML and Gemini working collectively, we have been capable of fuse the steered indicator suggestions and the query textual content with a view to present extra particular, contextual suggestions that’s actionable for the asker in bettering their query, making it simpler for customers to search out the information they want. That is one step ahead in our work to enhance the core Q&A flows to make asking, answering, and contributing to information simpler for everybody. And we’re not performed with Query Assistant simply but. Our Neighborhood Product groups are looking forward to methods we are able to iterate on the indicator fashions and additional optimize the question-asking expertise with this function.

{kind=link}