
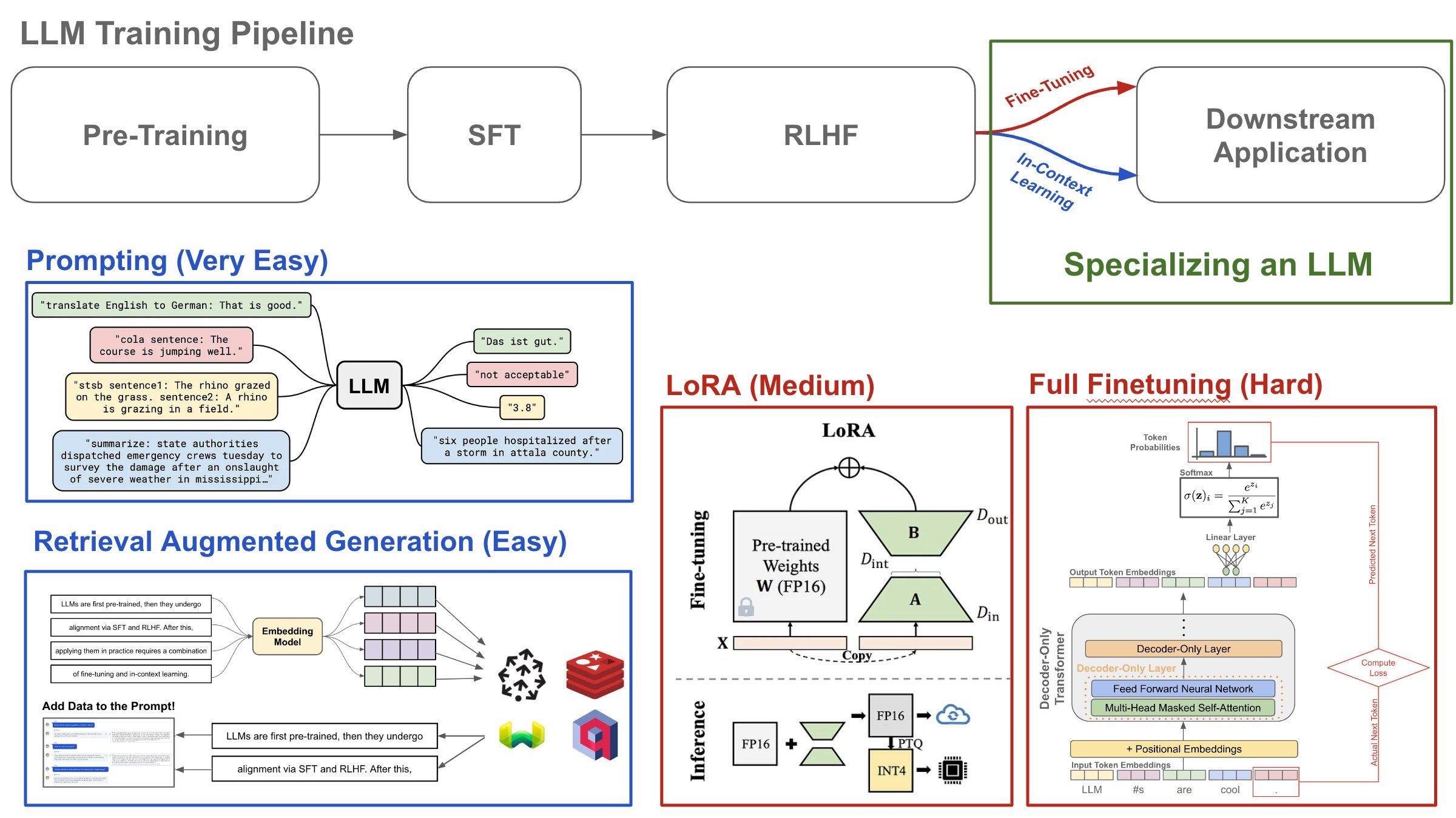
Trying to create a language model that understands your own custom data? Here are four techniques you can use to create a specialized LLM, ordered in terms of the amount of complexity/compute involved.
TL;DR: When trying to solve problems with language models, we should start simple and only introduce complexity as needed. Along these lines, we can just try to prompt the model first, then try a RAG approach. If this doesn’t work, we will then finetune the mannequin, beginning with LoRA (i.e., a less expensive finetuning method) as an alternative of end-to-end finetuning.
(1) Prompting: Step one in trying to unravel an issue with an LLM is simply writing a immediate! Begin with a easy immediate, strive including few-shot exemplars, take a look at completely different directions, and doubtlessly even use a extra complicated prompting method (e.g., chain of thought prompting). If your required software could be solved by way of prompting, that is the simplest method when it comes to time/effort.
(2) Retrieval Augmented Era (RAG) continues to be only a type of prompting. Nevertheless, we retrieve additional context to incorporate within the language mannequin’s immediate. First, we take the entire domain-specific information we’ve got, break up it into chunks and index/retailer these chunks for search (i.e., a reverse index and/or a vector database). Then, we will retrieve related information to incorporate within the mannequin’s immediate when producing output to scale back hallucinations.
(3) LoRA is a parameter-efficient finetuning method that decomposes the burden replace derived from finetuning right into a low rank decomposition. By doing this, we reduce the variety of trainable parameters throughout finetuning, thus drastically lowering reminiscence overhead. Nevertheless, we will obtain comparable efficiency to full finetuning and add no additional inference latency as a result of this low rank weight replace could be “baked in” to the prevailing weight matrix.
(4) Full Finetuning: If not one of the above strategies work, one of many final methods that we will strive is finetuning the language mannequin end-to-end. To make this profitable, we wish to curate a big corpus of knowledge that accommodates helpful data related to issues that we are attempting to unravel. Then, we will additional prepare the total mannequin utilizing a subsequent token prediction technique that’s just like pretraining, thus specializing the mannequin over the particular area of information contained within the finetuning corpus.

{kind=link}