
Looking back a few decades, search-based navigation of knowledge was rocky for knowledge producers. Google Knowledge Graph reminded us that many seekers were happy to find the quick answer, but the benefits still rolled back to the source platforms. These search platforms made money from high-scale audiences via advertising, affiliates, performance marketing, etc. Companies that survived and thrived adjusted to this by leveraging meta-information and links, which enabled them to generate traffic; an entire industry built around optimization and performance of search-enabled marketing emerged. The Interdependent relationship between search providers and content producers grew with the advent of sitemaps and search engine optimization roles, which created more value for them and the users trying to find the information they needed.
A few years later, cloud computing provided a more performant and cost-effective way to deliver technology’s benefits, giving rise to the concept of infrastructure-as-a-service. These applied sciences drove an much more fast transformation; companies that survived adopted cloud computing by default to decrease prices for themselves and their prospects. Cloud-based companies then gave technique to cloud-based merchandise, and the rise and proliferation of software-as-a-service enterprise fashions emerged, creating totally new classes of companies.
About ten years in the past, new interfaces and interplay strategies, resembling Siri and different digital assistants, advanced, as did early chatbots. Whereas this new, extra conversational know-how felt progressive, in contrast to earlier transformations, the enterprise fashions that served it had no underlying change. These brokers had been nonetheless interfaces for interacting with data platforms, finally sourcing hyperlinks to these respected assets, with standard search below the hood. These forces started to vary just lately when AI chatbots and brokers turned the most recent interfaces to floor data—separating content material (and audiences) from platforms into interfaces that try and summarize listed neighborhood content material. These brokers current synthesized data as if they’re the proprietor or creator of that data with out attributing the precise authors; this prevents the interchange of site visitors again to the sources, generally utterly obscuring them. With this, the web is altering as soon as once more: it’s changing into extra fragmented because the separation between sources of data and the way customers work together with that data grows.
On the identical time, new issues are rising:

- Solutions will not be data: What do you do when your LLM would not have a enough reply in your prospects’ questions? Regardless of the large positive aspects LLMs have made previously 18 months, they usually lack two key issues: solutions to extra advanced queries or context to why a solution may work in a single state of affairs or setting however not one other.
- LLM mind drain: AI brokers give solutions however don’t reinforce the creation and upkeep of recent data, nor can they take into account how the long run may look totally different from at the moment. AI’s finish customers then famously complain about “cutoff dates,” or the date in historical past when the LLM’s data is lower off. How do LLMs preserve coaching and bettering if people cease sharing unique thought?
- Builders lack belief in AI instruments: We face a state of affairs the place a person’s belief in neighborhood data is extra essential than ever. Nonetheless, the know-how merchandise that ship the data depart that belief and credibility out of the loop. An growing insecurity in LLM-generated output dangers each part of this method that’s forming.
Preserving and highlighting the suggestions loops with the people producing the data is important for continued data creation and belief in these new instruments.
The excellent news is that some LLM creators are partaking more and more with knowledge-generating communities to remain present. They know the LLM mind drain danger and perceive that there isn’t a substitute for human data, even with artificial knowledge. Put in traditional financial phrases: there’s ever-greater demand, and communities, platforms, and publishers have the provision. With this, a brand new set of Web enterprise fashions is rising: on this new Web period, companies that perceive that human data and its creation, curation, and validation are as invaluable (or extra so) than the notice or engagement of customers themselves. In consequence, Stack Overflow and the bigger Stack Trade neighborhood have to be direct about our wants and guarantee GenAI suppliers associate with us on this new forefront. We’re getting into a brand new economic system the place knowledge-as-a-service will energy the long run.
This new set of enterprise fashions is dependent upon a neighborhood of creators that progressively create new and related content material, domain-specific, high-quality, validated, and reliable knowledge. It additionally leans closely on moral, accountable use of knowledge for neighborhood good and reinvestment within the communities that develop and curate these data bases. These companies can be profitable if they’ll deploy and construction their content material for consumption at scale, establish and help end-product use circumstances for his or her content material by third events, and ship ROI for enterprises. They need to additionally set up a community of enterprise relationships and procure and deploy related datasets to construct and optimize for finish customers (in Stack’s case, builders). In the long run, they’ll maintain these companies with their means to create new knowledge sources, shield their current ones from unpermitted business use and abuse, and proceed macroeconomics conducive to promoting entry to knowledge or constructing instruments primarily based on data, content material, and knowledge.
So, what will we imply by knowledge-as-a-service? It’s easy for Stack Overflow: Builders and LLM suppliers depend on Stack’s platform to entry extremely trusted, validated, and up-to-date technical content material—the data sore. The data retailer helps person and knowledge paths to entry current data on demand whereas accelerating the creation and validation of recent data. The Data Retailer is repeatedly rising, bettering, and evolving on the pace of technical innovation, reinforcing person and knowledge loops and fixing for “LLM mind drain” and “Solutions will not be data” issues. Data-as-a-service establishes Stack Overflow’s public data retailer as essentially the most authoritative and trusted data retailer in know-how. It additionally pushes ahead a future that preserves the openness of neighborhood content material: it allows communities to proceed to share data whereas redirecting LLM suppliers and AI product builders to have pathways for truthful and accountable use of neighborhood content material.
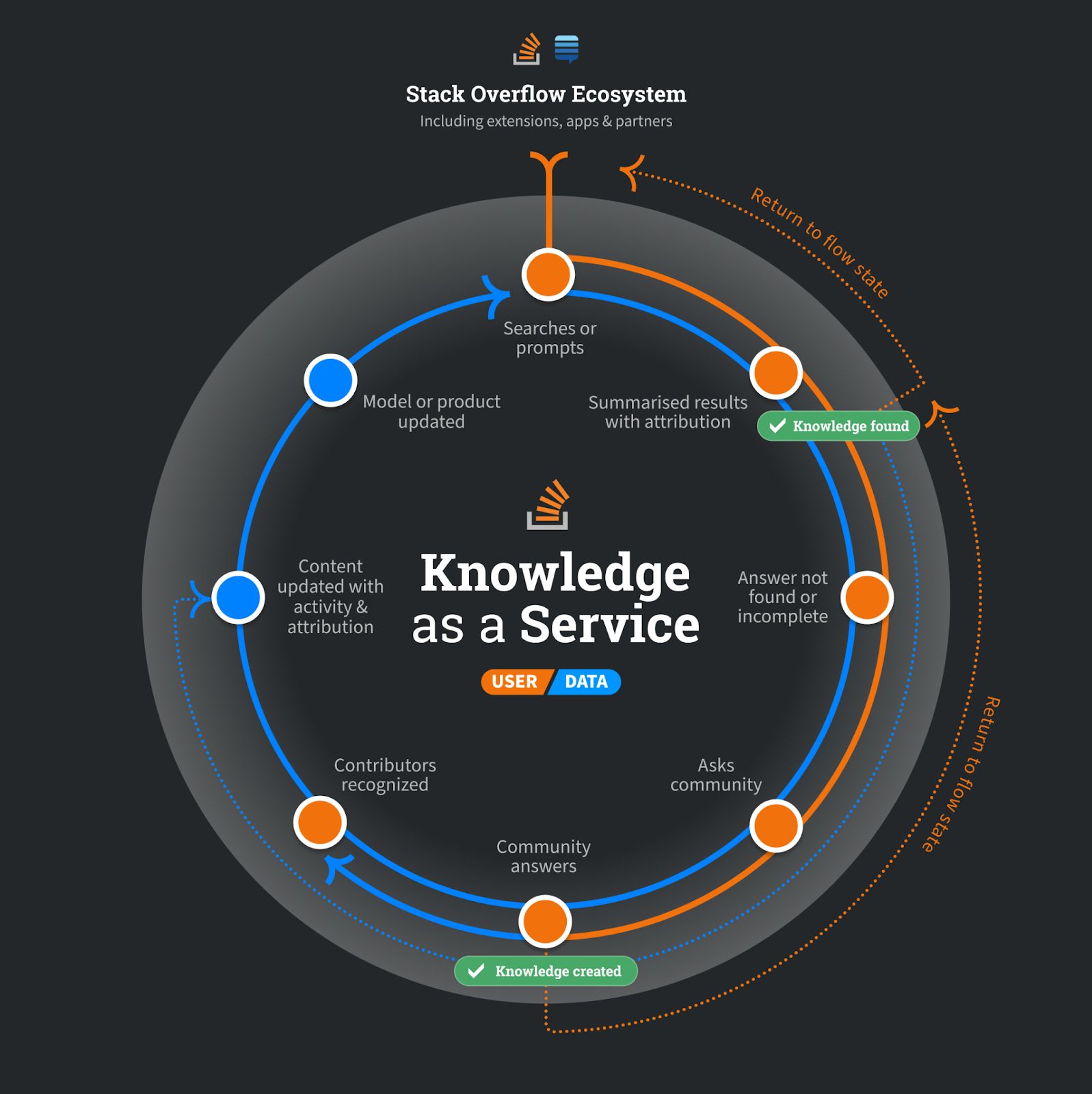
When enterprises mix this public data retailer with their data, this newly expanded corpus and its entry and upkeep change into knowledge-as-a-service, a reinforcing suggestions loop that allows builders and technologists inside these organizations to innovate and drive worth for organizations extra effectively and successfully. With these altering forces, pursuing a knowledge-as-a-service technique isn’t simply opportunistic for Stack Overflow; it’s the finest alternative for long-term success and viability. Data-as-a-service establishes sustainable monetary progress in a market the place historic monetization, like promoting and software program as a service, is more and more below strain throughout content material and neighborhood merchandise.
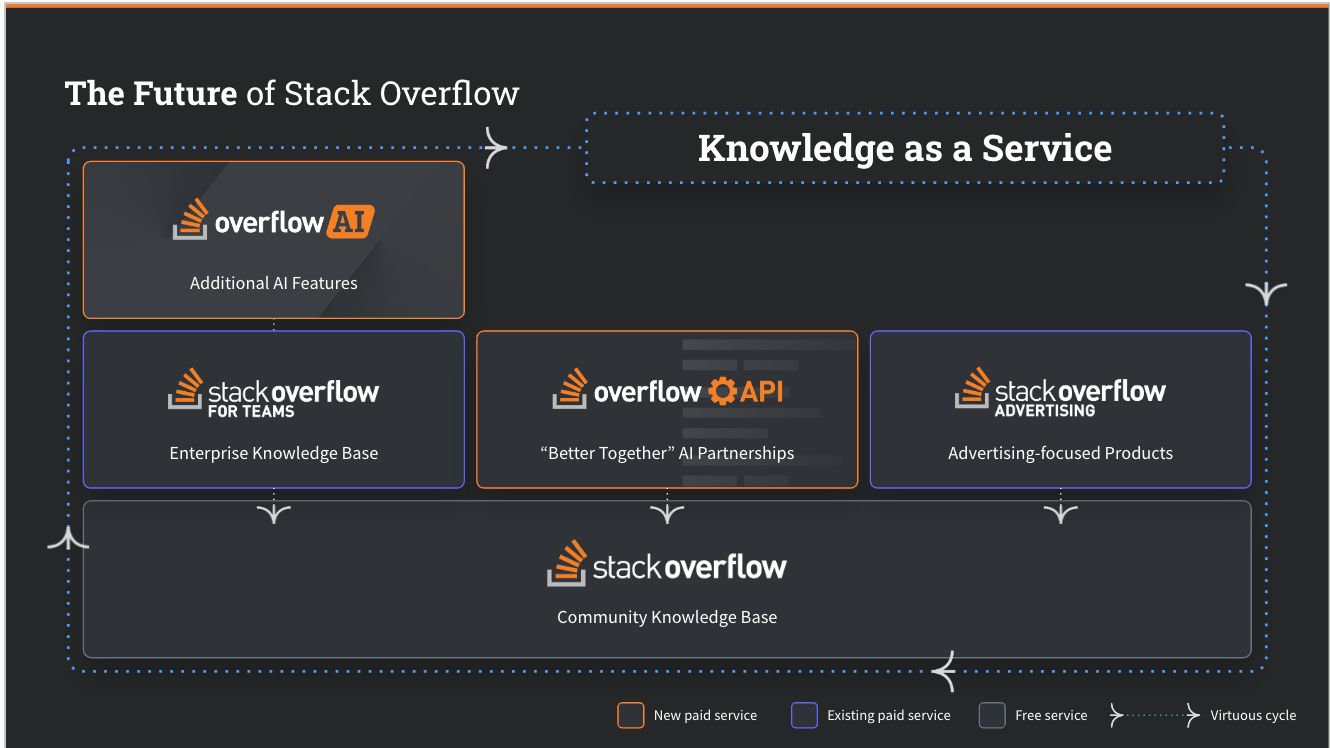
Finally, this technique is easy: the long run necessitates a world the place we rise to satisfy these adjustments by evolving in the direction of Stack Overflow as a “Data-as-a-service” platform or getting left behind. By doing nothing, we danger the existence of our communities and the platform. We select to rise to this problem and construct for a future the place communities and content material suppliers can coexist and thrive.
Underpinning these knowledge-as-a-service companies is the necessity for attribution of content material and creators. In the next post on this sequence, we’ll cowl how attribution works for our OverflowAPI companions and why it issues.

 WP Engine Sitch
WP Engine Sitch{kind=link}