
The big picture: Large language models are based upon a deep neural network architecture called a decoder-only transformer. Inside every layer of this mannequin, now we have two key parts:
1. Masked self-attention learns relationships between tokens/phrases.
2. Feed-forward transformation individually transforms the illustration of every phrase.
These parts are complementary—consideration seems to be throughout the sequence, whereas feed-forward transformations think about every token individually. When mixed collectively, they permit us to study advanced patterns from textual content that energy the AI purposes which might be so well-liked at the moment.
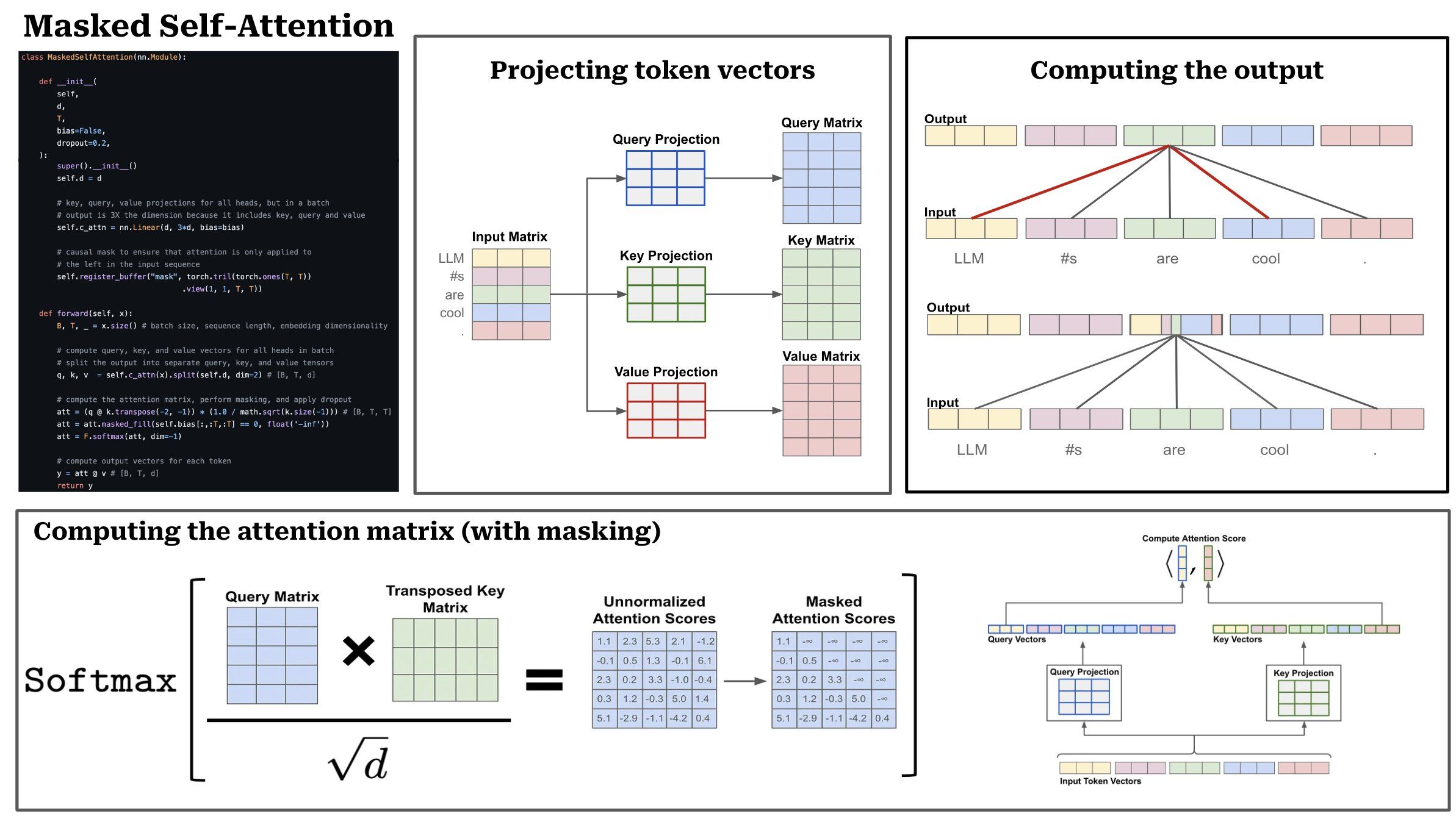
TL;DR: The enter to an consideration mannequin is an inventory of token/phrase vectors, which may be stacked collectively to type a matrix. Causal self-attention operates by computing an consideration/significance rating between every pair of tokens/phrases in a sequence. Then, the output of self-attention is a weighted mixture of all phrases within the sequence, the place the load is given by the eye rating. We are able to break the method of masked self-attention right into a sequence of 5 steps.
(1) Linear projections: Step one is to carry out three separate linear projections, referred to as the question, key, and worth projections. Virtually, these projections take our sequence of token vectors as enter and produce three remodeled sequences of token vectors as output.
(2) Consideration scores: To compute consideration scores, we use the question and key vectors produced by the linear projections described above. The eye rating between the i-th token and the j-th token within the sequence is given by the dot product of the i-th question vector and the j-th key vector. To compute all of those pairwise scores effectively, we will stack the question/key vectors into matrices and take the matrix product of the question matrix with the transposed key matrix. The output is a TxT consideration matrix, the place T is the size of the enter sequence (in tokens). To enhance coaching stability, we additionally divide the values of the eye matrix by the sq. root of the scale of the token vectors (i.e., scaled dot product consideration).
(3) Forming a likelihood distribution: From right here, we will flip the eye scores for every token right into a likelihood distribution by performing a softmax operation throughout every token’s consideration scores for the sequence. In observe, that is finished through a softmax operation throughout every row of the eye matrix. After this, every row of the eye matrix turns into a likelihood distribution that represents the (normalized) consideration scores for a single token throughout the sequence (i.e., the i-th row comprises the i-th token’s consideration scores).
(4) Masking operation: In vanilla self-attention, every token is allowed to compute consideration scores for all tokens within the sequence. In masked self-attention, nevertheless, we masks consideration scores for any token that follows a given token within the sequence. We are able to implement this by merely masking the eye matrix previous to performing the softmax (i.e., fill entries for any invalid consideration scores with a worth of unfavorable infinity), such that the likelihood of any future token within the sequence turns into zero. For instance, the i-th token within the sequence would have an consideration scores of 0 for tokens i + 1, i + 2, and so forth. Virtually, masked self-attention prevents us from trying ahead within the sequence when computing a token’s illustration.
(5) Computing the output: From right here, we will compute the output of masked self-attention by taking the matrix product of the eye matrix and a matrix of worth vectors. This operation computes the output for the i-th token by taking a weighted mixture of all worth vectors, the place the weights are given by token i’s consideration scores.

{kind=link}