SPONSORED BY MONGODB
With the appearance of large-language fashions, everyone seems to be trying to allow conversational interfaces inside their applications, whether or not they’re search, code era, or information evaluation. One of many foundational applied sciences for that is the vector embedding, which takes a token of pure language—doc, sentence, phrase, and even photographs, video, or audio—and represents it as a vector, letting any app traverse its language mannequin like a map.
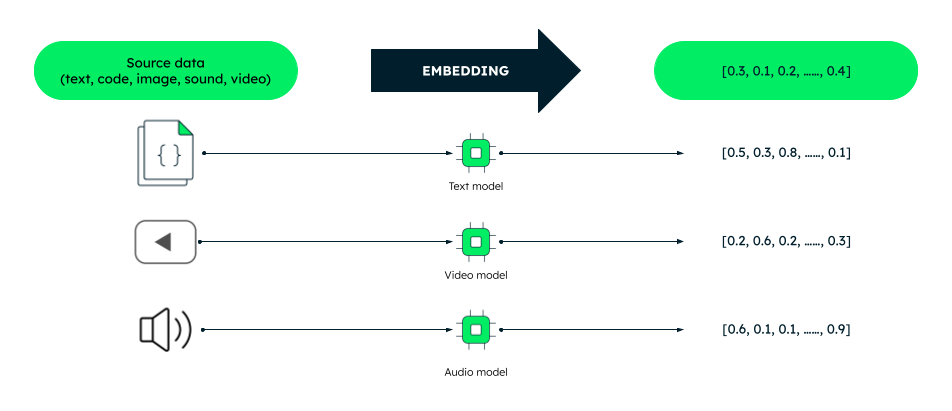
A vector embedding is actually a fixed-sized array of floating level numbers. This implies it may be saved in just a few kilobytes of area in any database. Whereas this will likely not seem to be a lot, if it’s good to retailer and evaluate hundreds of embeddings, the numbers will shortly add up. Sooner relatively than later, you’d understand that the database you selected hasn’t been constructed with vectors in thoughts.
Moreover, it is extremely unlikely that you just’d use embeddings in isolation. To repeatedly generate embeddings in your information, it’s good to combine your database with an embedding mannequin, akin to Google Cloud’s textembedding-gecko mannequin. textembedding-gecko is a transformer-based mannequin skilled on a large dataset of textual content and code. It could possibly generate high-dimensional vectors that seize each the semantic that means and the context of the phrases. For instance, this integration can be utilized to repeatedly create vector embeddings for buyer evaluations and product scores. The embeddings can then be used to enhance the efficiency of your buyer churn prediction mannequin, which might show you how to to determine prospects who’re vulnerable to leaving your corporation.
Indisputably, vector embeddings are a robust instrument for representing information and an integral a part of many AI-powered apps. However storing and querying them effectively could be a problem.
One answer is to make use of a specialised vector database. However this introduces an entire new set of challenges: from synchronizing your operational and vector databases, by means of studying a brand new know-how, all the best way to sustaining and paying for an additional product.
What for those who might retailer vectors in your current operational database and nonetheless get the efficiency advantages of a specialised vector retailer? What for those who select a knowledge platform that helps storing and querying vectors and seamlessly integrates with among the finest AI cloud platforms—Google Cloud? You should use MongoDB Atlas Vector Search and preserve the efficiency advantages of an optimized vector retailer with out the effort of managing a separate database!
MongoDB Atlas is a fully-managed developer information platform providing integrations with a wide range of Google Cloud AI companies. It comes with a variety of options together with international deployments, automated information tiering, and elastic serverless cases. Vector Search is a brand new function of that permits you to retailer, index, and search by means of vector embeddings effectively. It’s constructed on high of MongoDB Atlas’s highly effective question engine, so you should utilize the identical acquainted syntax to question your vector information.
Efficient vector storage in your operational database
MongoDB Atlas has supported full-text search since 2020, however solely utilizing a wealthy key phrase matching algorithm. Extra not too long ago, we began seeing individuals bolting on vector databases to their MongoDB Atlas information, changing the info there into textual content embeddings. Their operational information lived in a single place, and the vectors lived in one other, which meant that there was plenty of syncing occurring between the 2 options. That created a possibility to scale back the overhead of these two instruments and the inefficiency of the sync.
Clients have been already utilizing MongoDB Atlas to retailer chat logs from LLM-based chatbots. These bots create plenty of unstructured information, which has been our bread and butter. We’d already added chat log assist, as our versatile schema can absorb all the extra prompts and responses generated by means of normal utilization. Our prospects needed to take all that chat information and feed it again into the mannequin. They needed to provide their chatbots a reminiscence. For that, we wanted the vectors.
With vector search, builders utilizing MongoDB Atlas can embrace their vector embeddings straight contained in the paperwork of their database. As soon as prospects have embedded their information all they should do is outline a vector index on high of the related area inside their paperwork. Then they will use an approximate nearest neighbor algorithm by way of a hierarchical navigable small world (HNSW) graph with the identical drivers and API that they use to hook up with their database.
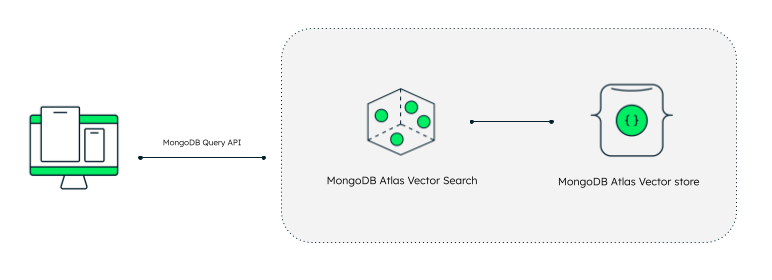
Now, along with the usual unstructured information, you’ll be able to create an index definition on high of your assortment that claims the place the vector fields are. These vectors dwell proper alongside the operational information—no syncing wanted. This makes all of your new chat log information accessible for approximate nearest neighbor algorithms. You’ll have to determine an clever chunking technique and convey your personal embedding mannequin, however that’s fairly customary for those who’re wanting so as to add information to a chatbot.
Each LLM is bounded by the coaching information it makes use of, and that coaching information has a cutoff date. With customized embeddings, prospects can now present updated context for the mannequin to make use of throughout inference. With the integrations constructed into frameworks like LangChain and LlamaIndex, builders can join their personal information to LLMs. Our neighborhood was so excited in regards to the new capabilities in Atlas Vector Search that they offered the primary commits to allow these frameworks.
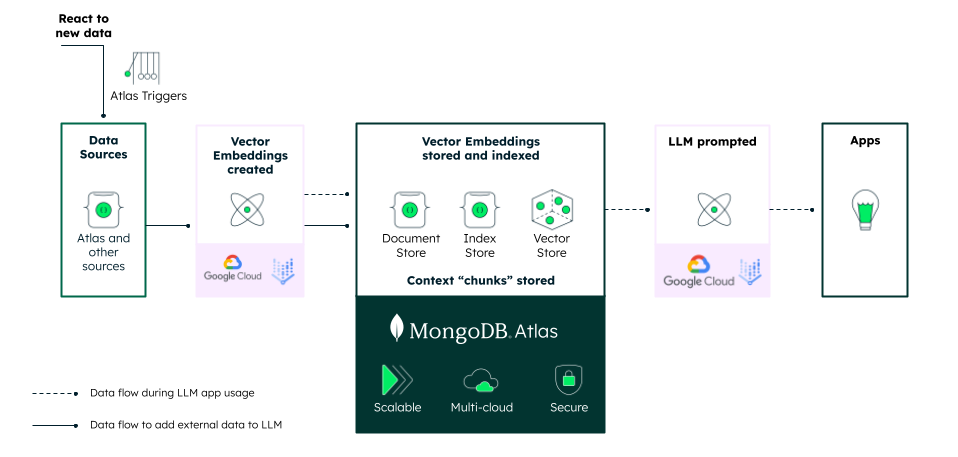
Continuous generation of embeddings with MongoDB Atlas Triggers and Vertex AI
Storing your vectors in MongoDB Atlas comes with some added advantages. MongoDB Atlas is much more than deploying MongoDB to the cloud—it additionally features a vary of companies for environment friendly information administration. Considered one of them is triggers—serverless features that execute at predefined schedules or when a particular occasion happens in your database. This makes it potential to automate the creation of embeddings for brand new information.
For instance, for instance you might have a group of merchandise in your database. You wish to create embeddings for every product with the intention to carry out semantic seek for merchandise and never simply key phrase search. You possibly can arrange a set off operate that executes at any time when a brand new product is inserted into the gathering. The operate then calls Google Cloud’s Vertex AI API to generate an embedding of the product and retailer it again into the doc.
It’s also possible to use triggers to batch the creation of embeddings. This will enhance efficiency and decrease prices, particularly when you have numerous paperwork to course of. Vertex AI’s API permits for producing 5 textual content embeddings with a single API name. This implies which you could create embeddings for 500 merchandise with simply 100 API calls.
Alternatively, you’ll be able to arrange a scheduled set off that generates embeddings as soon as a day. This can be a good choice for those who needn’t create embeddings in actual time.
By utilizing triggers and the versatile Vertex AI APIs, you’ll be able to automate the creation of embeddings for brand new information and even for information that has been up to date.
Having a vector retailer inside MongoDB Atlas permits some fairly nice superpowers. However chances are you’ll surprise why, if vector databases have been round for a short time already, you wouldn’t simply use a purpose-built database for all of your textual content embedding wants.
All-in-one vs. specialized tools
The truth is that you just don’t even want a vector database to retailer vectors—you’ll be able to retailer them in any database. They’re arrays of floating level numbers, and any database can try this. However when you might have hundreds of thousands or extra, two challenges emerge: effectively storing and querying them.
Storage
Firstly, having two databases as an alternative of 1 means you need to preserve each of them alive. You must pay for his or her uptime and information switch. It is advisable to monitor each of them and scale their infrastructure. One information retailer operating on one infrastructure with one monitoring setup is easier. Extra dependencies, extra issues, proper? I’m certain your DevOps and SRE groups would respect having fewer objects to keep watch over.
These two databases retailer two encodings of the identical information, which implies there shall be syncing anytime one thing adjustments within the operational retailer. Relying on what your software is, chances are you’ll be sending common embedding updates or re-embedding the whole lot. It’s an extra level of contact, which makes it an extra place to interrupt down. Any friction or inconsistencies within the information may cause your customers to have a foul time.
Queries
When operating queries on vector databases, many individuals discuss Ok-nearest neighbor searches. They’re both speaking about an actual search, which must be calculated at runtime, or an approximate search, which is quicker however much less correct and loses a number of the outcomes on the margins. Both means, that requires two separate API calls: one for the search and one to retrieve the outcomes.
When operational and vector information dwell proper subsequent to one another, it turns into an entire lot simpler. You possibly can filter, then search. The textual content embedding that allows semantic search and LLM-based purposes is vital, however so is the textual content that these vectors are primarily based on. Combining the 2 helps create the purposes that you just wish to use.
There’s an vital a part of this course of that mixes each storage and question points, and that’s the way you chunk the info to create the vectors. Chunking is the way you break up bigger items of textual content into smaller fragments so your search outcomes could be granular. This course of must occur as a part of your information processing pipeline.
Think about that you just’re processing a e book. When a consumer is trying to find one thing, they in all probability don’t wish to get your entire e book again, and useful that means could get misplaced for those who attempt to embed your entire piece of textual content in a single vector. Probably you will have to have the ability to level a consumer to a particular sentence or web page throughout the e book. So that you’re not going to create a single embedding for the entire e book—you’re going to chunk it out into chapters, paragraphs, and sentences. There’s a posh relationship between these chunks. Every sentence hyperlinks again to the supply information for that sentence, nevertheless it additionally hyperlinks again to the paragraph, which hyperlinks again to the chapter, which hyperlinks again to the e book. In the identical means, it’s good to mannequin your operational information successfully to get a set of vectors that hyperlink again to their sources. This information modeling could be most effectively accomplished throughout the information layer, not on the software layer by way of a framework like LangChain and LlamaIndex, which additionally requires storing these mum or dad relationships in reminiscence. As we’ve seen with a number of the LLM hallucinations, verifying responses with sources could be key to creating good purposes.
Finally, that’s what we’re making an attempt to do by combining vector information with operational information: create good purposes.
Vector search use cases
We will discuss ourselves blue about the advantages of storing vectors together with your operational information, however we expect just a few use circumstances would possibly assist illustrate the results. Listed here are two: restaurant filtering and a chat bot for inside documentation.
Restaurant filtering
Most restaurant itemizing platforms in the present day have two separate sections: particulars in regards to the restaurant like location, hours, and evaluations. Each of them present good, searchable information for anybody on the lookout for a meal, however not all searches shall be as efficient for those who simply use key phrase or vector searches.
Think about you need consolation meals in New York Metropolis. Perhaps you wish to seek for “consolation meals in New York Metropolis like mama made.” That question in a vector search might get you the consolation meals you’re on the lookout for, nevertheless it might additionally carry up outcomes that aren’t in New York Metropolis.
For those who have been to take a naive strategy to this drawback, you would possibly use what known as a “put up filter.” On this naive situation, you’ll return the 100 nearest neighbors from a vector search answer after which filter out any outcomes that don’t occur to be in New York. If it simply so occurs that out of the 100 outcomes you retrieve from the primary stage of the earlier instance are all in Birmingham, Alabama, then the ensuing question would supply zero outcomes despite the fact that there are consolation meals choices in New York Metropolis!
With an answer like Atlas Vector Search that helps “pre-filtering,” you’ll be able to filter the record of vectors primarily based on location as you traverse the vector index, thereby guaranteeing you at all times get 100 outcomes so long as there are 100 consolation meals eating places in New York Metropolis.
Search your knowledge base
One of many downsides of most LLM-enabled chat purposes is which you could’t test their sources. They spit out a solution, certain, however that reply could also be a hallucination, it could be dated, or it could miss the context of personal info it must be correct or useful.
That’s the place retrieval-augmented era (RAG) is available in. This NLP structure may give each a summarized reply primarily based in your information and hyperlinks to sources. Consider a scenario the place you might have a bunch of inside documentation: for instance, say you wish to search to find out whether or not you’re eligible for dental insurance coverage in a selected location. As a result of that is personal info that solely the dental insurance coverage supplier is aware of about, you’re going to should handle the text-embedding course of (together with storage and retrieval of the vectors) your self. Whereas the semantic search would possibly get you the reply, you’ll desire a reference to the supply of the reply to substantiate the accuracy of any LLM response.
On this situation, your software will take the consumer’s question and ship it to the vector search answer to seek out the related info. As soon as it has that related info it can assemble a “immediate” that incorporates the query the consumer requested, the data acquired from the vector search, and another parameters you wish to use to make the LLM reply the way you’d like (e.g. “reply politely”). As soon as that is accomplished, all of that info is distributed to the LLM and the result’s returned again to the appliance which could be offered to the consumer.
Vector search has modified what’s potential when it comes to pure language interfaces. Due to the sheer variety of vectors {that a} typical corpus would produce, many organizations are on the lookout for specialised vector databases to retailer them. However storing your vectors aside out of your operational database makes for inefficient purposes. In a aggressive market, these efficiencies can price you actual cash.
Able to get began with MongoDB Atlas on Google Cloud? Try our Google Cloud Market itemizing to get began in the present day or login to MongoDB Atlas. It’s also possible to be taught extra about our partnership on our Google integrations web page.

{kind=link}