
SPONSORED BY MONGODB
For purposes aiming for prime availability with out the effort of managing infrastructure points, serverless computing has emerged as the subsequent stage of {hardware} abstraction.
Cloud computing and containers virtualized the bodily servers that net and cell apps ran on, however you continue to wanted to provision these assets and handle how they scaled. Whereas serverless doesn’t remove the server (clearly) it does imply that you simply don’t have to consider how your infrastructure must scale to help your software’s fluctuating site visitors, permitting for sooner improvement cycles by lessening the administration burden.
Serverless know-how is mostly carried out through serverless features, or features as a service (FaaS), that are used to run enterprise logic in stateless containers. However for those who’re constructing an software that should persist information, you’ll want to attach your serverless features to a database.
The advantages that come from serverless computing may be misplaced if it’s a must to spend your time provisioning {hardware} or worrying about capability planning and administration as your software scales. In reality, conventional databases, (even fully-managed DBaaS), are usually not well-suited for managing the frequent but disposable requests that come from serverless features.
Happily, there are some databases that may deal with the type of workload {that a} serverless software produces, as they themselves are constructed to function in a serverless method.. On this article, we’ll dive into the perils of working with a database that isn’t serverless and simply how a lot distinction the suitable database makes for working serverless purposes.
What’s serverless?
With all the thrill about serverless, it’s a good suggestion to step again and guarantee that we’re speaking about the identical factor. Serverless is an umbrella time period. At its core, it’s a computing mannequin the place you don’t want to consider the underlying infrastructure: you don’t provision assets, you don’t handle scaling, and also you don’t fear about excessive availability. All that occurs mechanically.
With serverless, you solely pay for assets that you simply use whereas your requests are being dealt with. When demand will increase in periods of excessive site visitors, the assets obtainable scale accordingly. When site visitors drops, you now not pay for these assets. Alternatively, a pre-provisioned cloud-based service can run up your invoice sitting idle and listening for requests. You’ll be able to nonetheless encounter excessive payments with serverless computing, however solely since you’ve had unexpectedly excessive utilization. Serverless has numerous advantages for purposes with variable or sparse workloads. Take into consideration a betting firm that permits reside wagers throughout the World Cup, for instance. Throughout a match, bets could are available in at any time, however you may assume that the variety of new bets will spike when one staff scores. Sadly you may’t predict when a purpose goes to be scored. With serverless, the infrastructure behind the betting software would immediately auto-scale to help the site visitors. Within the absence of auto-scaling, you would wish to manually monitor your useful resource consumption to find out when it was essential to scale up — assuming you could have the obtainable assets to take action.
Serverless databases basically work the identical manner. Once you ship them information, the databases mechanically scale to deal with elevated connections and storage necessities. You pay for the learn/write site visitors and the storage that the info occupies. That’s it.
The challenges with conventional RDBMS and serverless computing
Once you combine a serverless compute platform with a conventional relational database (RDBMS), you’re prone to run into some points. The obvious (though not restricted to relational databases alone) are round provisioning infrastructure assets. Whilst you’re saving time through the use of serverless computing, you continue to want to fret about infrastructure in your database. Even when the database is hosted on a managed platform, you continue to have to provision these assets — the “managed” half refers back to the infrastructure that it’s hosted on, not essentially the assets obtainable. Databases will develop over time as new information is saved, so your storage assets, along with compute, additionally want to have the ability to develop with it.
One other widespread problem is the danger of overwhelming the database with too many connections. In a normal database interplay, a service or software opens a connection to a database, maintains it to learn and write information, then destroys the connection when completed. Serverless features could spin up a brand new connection for each request, creating dry connections: open connections that aren’t sending or receiving information, however add to the variety of whole open connections and might doubtlessly block new connections. Selecting a serverless database eliminates this problem totally and can merely scale (up or down) in accordance together with your software wants with none work required in your half.
You’ll be able to pool connections to enhance efficiency and keep away from working dry connections, however you continue to danger learn/write conflicts if a number of connections are accessing the identical information. A database constructed for serverless usually has pooling or some type of load balancer in-built to assist mitigate this drawback.
Doc-model databases work higher with serverless
The largest disadvantage to deciding on a relational database in your serverless structure is the structural rigidity of the database schema. In an RDBMS, every document saved should conform to the construction that the desk implements with out exception. All information should be written to a desk, and each desk has a set variety of columns. In case you have information that has values that don’t match into any of these columns, you’ll want so as to add a brand new column. Each bit of knowledge already entered into the desk would require an replace to incorporate a worth for that column and indexes will have to be refactored.
The price of schema adjustments makes it more durable to iterate on and evolve your database construction alongside your software logic. You lose out on one of many core values of serverless —– pace to market.
As an alternative, choosing a doc mannequin database deployed on the cloud, like MongoDB Atlas allows you to retailer information because it involves you.. Whereas relational databases impose strict information buildings, doc mannequin databases outline the construction of every doc individually, providing you with a substantial amount of flexibility when you develop.
For fast-paced merchandise, change occurs usually. In case you’re locked into a selected information schema, that limits the sorts of adjustments you can make. Doc databases permit any new doc construction you wish to apply to exist alongside all earlier buildings. If you want to regulate current data, you may backfill information or modify the construction as a separate course of. This makes it simple to iterate on and evolve your information mannequin as you develop.
Attaining serverless-style scalability from a database
Past simply the advantages of the info mannequin, MongoDB Atlas additionally removes a lot of the ache related to provisioning and scaling infrastructure. Our absolutely managed information platform makes it simple so that you can get the database assets you want once you want them, with automated, elastic scaling to take the burden off of improvement groups. That is particularly necessary when working with serverless compute providers (or any serverless structure for that matter) once you want your database to be reactive to surprising spikes in site visitors.
One of these scaling may be achieved with an Atlas devoted cluster with compute and storage auto-scaling enabled, which offers you extra management over setting minimal and most scaling thresholds, or you may decide to deploy a serverless database. A serverless database in Atlas, known as a serverless occasion, is an on-demand endpoint that scales mechanically to fulfill your software wants with none upfront provisioning or capability administration required. They’re primarily based on an operations-based pricing mannequin that fees just for the assets and storage used and can scale right down to zero if there isn’t any site visitors – providing you with the complete advantages of constructing on prime of serverless infrastructure.
Nonetheless, as with serverless computing, a sudden spike in site visitors can typically result in a surprisingly giant invoice. To attenuate this sticker shock, we’ve carried out a tiered pricing system for learn operations wherein every tier is progressively cheaper. You continue to pay for what you utilize, however you’ll pay much less for that site visitors the extra site visitors you get.
Getting began with a serverless database in MongoDB Atlas
As a result of all infrastructure is provisioned and all scaling is dealt with, getting began with a serverless database is a matter of naming the database occasion and pointing it to your cloud supplier of selection (obtainable in areas on AWS, Google Cloud and Azure). Severely:
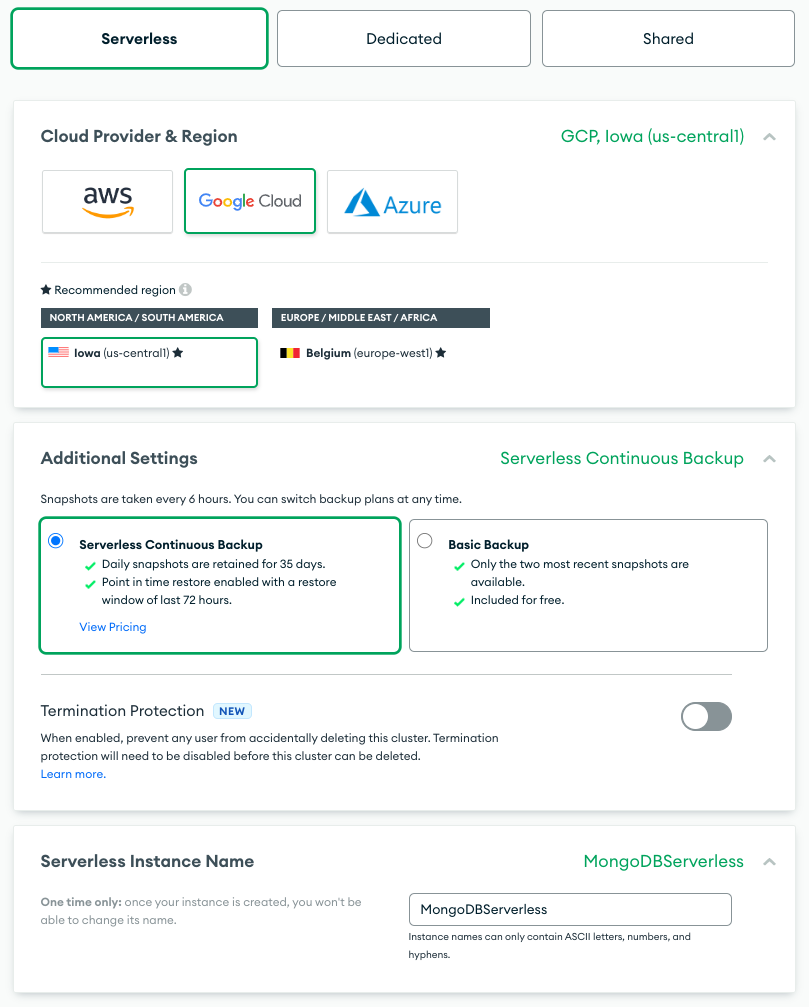
All you want to do is choose your supplier, area, and desired backup choice, then give your occasion a reputation you’ll use to consult with it in your software. That occasion identify might be a very powerful a part of this setup; you’ll want to incorporate it within the database connection string that opens a connection to a database, so make it memorable and manageable.
In distinction, making a database on a devoted server requires you to pick out the infrastructure necessities and a bunch of different configuration choices which have been abstracted in serverless, serving to to save lots of you time.
“Due to Atlas serverless situations we’re spending much less time wrestling with infrastructure and configuration and extra time growing options for our clients.” – CEO, Small Enterprise Pc Companies Firm.
Construct full-stack serverless purposes with MongoDB Atlas + Google Cloud Run
In case you’re seeking to get began with a serverless compute and database stack, we’ve discovered good outcomes working MongoDB Atlas with Google Cloud Run. It’s a fully-managed serverless resolution that performs seamlessly with our database situations.
Cloud Run’s automated scalability, mixed with MongoDB Atlas’s absolutely managed and extremely obtainable database, permits for a seamless and cost-effective technique to deal with incoming site visitors. As Cloud Run mechanically spins up extra containers to deal with the load, your serverless database may even present extra assets to deal with the database load. This ensures that your software is at all times capable of deal with incoming site visitors, even in periods of excessive and surprising utilization, with out you having to fret about managing the underlying infrastructure. So you may concentrate on growing and deploying your software, as a substitute of worrying about sustaining servers or databases.Each Cloud Run and MongoDB Atlas are pay-per-use providers, which implies that you solely pay for the assets you really use. Relying in your use case, this will make it easier to save on price as you aren’t paying for assets that you simply don’t want.
Lastly, Cloud Run’s stateless and event-driven nature and MongoDB Atlas’s mechanically scaling and extremely obtainable database make them an ideal match for all kinds of use circumstances, from easy net purposes to complicated microservices architectures. Builders can take full benefit of serverless know-how throughout your entire stack, making their improvement course of extra streamlined and cost-effective.
Transfer quick and don’t fear about infrastructure
For people or organizations seeking to get a cloud-based software up and working shortly with out having to fret about provisioning and scaling infrastructure, serverless has emerged as a strong choice. However you possibly can miss out on the complete advantages of serverless if a part of your stack — your databases — aren’t optimized for flexibility and scale.
In case you’re seeking to enhance your effectivity and benefit from the added advantages of a serverless database, sign-up for MongoDB Atlas on Google Cloud Market to attempt Atlas serverless situations at this time. After signing up and finishing the setup wizard, you’ll be prepared to start out storing information inside minutes. In case you’re not fairly prepared for that, you too can go to our web site to be taught extra about methods to construct serverless purposes with MongoDB Atlas to be sure you’re ready when your subsequent mission arises.
Tags: cloud computing, database, mongodb, noSQL, associate content material, partnercontent, serverless

{kind=link}