
Lesser recognized SQL transforms and why they may be helpful

In prior posts, I analyzed knowledge from the SQL Generator 5000 and outlined the 5 hottest SQL transforms. This time, I’m doing the other and searching on the 5 least fashionable.
After I initially reviewed the transforms that have been the least fashionable, I used to be stunned as a result of nearly all of them are very helpful. So, I reached out to some customers that I do know personally to speak to them about it.
Primarily based on these conversations, I realized that the principle purpose that these transforms are not often used, is twofold:
- Some are very situational — whereas
combinationandbe a part ofare utilized in virtually each SQL question,Shifting Commonis just used when working with time-series knowledge - A few of these transforms are are distinctive to SQL Generator — and lack of utilization is just resulting from a lack of knowledge that they exist
Due to this fact, I’ll stroll by way of the High 5 least fashionable transforms, and together with the SQL code, I’ll clarify a state of affairs the place every might be helpful.
What’s it?
Scalers are strategies that change the vary of values. The 2 most typical are: min_max_scaler and standard_scaler. Usually, scaling is finished in a method in order that the brand new vary falls between 0 and 1. Standardizing, alternatively, is finished in a method in order that the typical worth is 0, and the usual deviation is 1. Typically the time period normalize comes up in dialog about these methods. Normalize can have a really particular which means, however normally it’s a generic time period that would imply scaling or standardizing (or one thing else!). To keep away from confusion, don’t use the time period normalize.
How is it used?
There are a number of frequent situations for scaling the info:
- Comparatively evaluating issues which might be measured with completely different items
- Fundamental segmentation
- Pre-processing for machine studying
- Plotting metrics collectively on the identical chart
Think about that you simply had some knowledge about sufferers, the place every of the variables was on a unique scale:
Since Age is measured in years, and Glucose is measured in mg/DL, it’s arduous for us to match sufferers. The formulation for scaling this knowledge requires us to know the MIN() and MAX() of the values. Equally, standard_scaler requires us to know the AVG() and STDEV().
Be aware how the SQL is written in a method that dynamically calculates every little thing on-the-fly.
What’s it?
Newest is a SQL rework that returns the final worth in an ordered set of values. Whereas most SQL capabilities solely “have a look at” one row at a time, this one makes use of what is known as window capabilities to have a look at different rows. Because of this, it’s only used when your knowledge has an inherent order to it.
How is it used?
There are various methods Newest can be utilized, however the commonest are:
- analyzing system logs, or techniques that file values solely once they change
- analyzing sensor knowledge when sensors generally aren’t reporting (that is frequent with sensor knowledge)
- analyzing “snapshot” knowledge — discovering end-of-period values
(end-of-month Gross sales, end-of-day Calls, and many others) - pre-processing for time-series or forecasting fashions
Think about that you simply had sensor knowledge, the place the temperature readings have been generally lacking:
Right here is the customizable SQL that replaces any clean values with the most recent prior worth.
The perform that works finest for this transformation is known as LAST_VALUE(). It really works by declaring a search window, which has completely different default behaviors relying on RDBMS. Due to this fact I all the time advocate that you simply explicitly declare the ROWS BETWEEN definition to make your code extra comprehensible.
NOTE: I wrote an extended tutorial on utilizing this method to fill in gaps in time-series knowledge.
What’s it?
The shifting common rework is one other window perform that requires the info to have an inherent order to it. As an alternative of at present’s gross sales quantity, the shifting common can be utilized to inform us what the typical gross sales quantity was over the previous 7 days.
How is it used?
Shifting common is principally used to determine a pattern. They will additionally “easy out” fluctuations in case your values soar round lots. It is without doubt one of the oldest and mostly used technical indicators. It’s even obtainable in Excel! Should you plot a time collection in Excel, you’ll be able to add a shifting common by right-clicking and “Add Development Line.”
It’s mostly utilized in:
- monetary and buying and selling evaluation
- pattern evaluation
- dashboard and chart overlays
Think about that you simply had knowledge that had a dramatic seasonal sample to it:
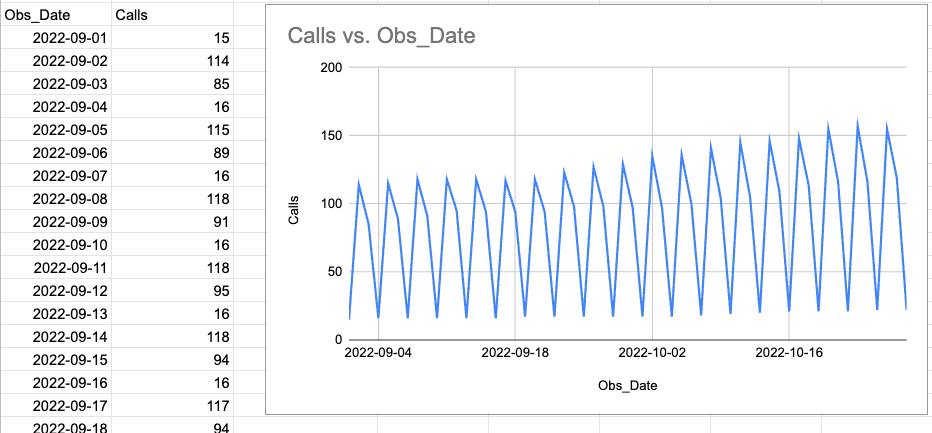
I made the chart as a way to see how there’s a slight rising pattern. Nevertheless quantifying that pattern may be tough for the reason that numbers are in every single place.
Utilizing the Shifting Common rework, we are able to create SQL that provides the shifting common for us.
After we plot the outcome, we are able to see a pleasant, regular, rising pattern.

What’s it?
Entropy is a strategy to combination categorical knowledge, and signify how dispersed it’s. It comes from the realm of data principle, and is commonly used behind-the-scenes in machine studying algorithms.
How is it used?
Our present evaluation of the SQL Generator is a superb instance of the place entropy is beneficial. Think about that Consumer A and Consumer B used the SQL Generator 100 occasions every, and that they solely used the two hottest transforms combination and pivot .
Consumer A: combination 50 occasions, pivot 50 occasions
Consumer B: combination 99 occasions, pivot 1 time
If we solely aggregated with COUNT() and COUNT(DISTINCT), we’d be unable to inform the conduct of those 2 customers aside, however their conduct is kind of completely different.
That is the place measuring entropy helps. Customers A and B are clearly completely different due to their distributions of utilization. Entropy will present us that Consumer A has entropy of 1 as a result of the distribution between combination and pivot is dispersed as a lot as it could presumably be. On the other-hand, Consumer B may have a really low entropy as a result of they primarily use solely a single rework.
There is no such thing as a direct SQL perform to calculate entropy , however the SQL Generator writes the logic to carry out this aggregation for you. Strive it your self!
What’s it?
A histogram is a kind of chart, so it’s no shock that customers of a SQL device don’t discover this rework very talked-about. Just like entropy, a histogram additionally measures dispersion, by breaking a numeric column into bins after which plotting the frequency of how typically they happen. Nevertheless, a histogram is a visible chart — and SQL can’t make charts, so what is that this SQL Rework even for?
How is it used?
Histograms themselves are very helpful. They permit a person to shortly reply questions, like:
- How typically does the cargo time exceed 48 hours?
- What’s the distribution of complete order quantity?
Analysts normally use a BI Device or a python bundle to routinely combination the info, and create the chart. This SQL rework is supposed to combination the info solely. It is because the underlying knowledge may be very giant when in comparison with the mixture that truly will get plotted.
For instance, in the event you had 500 Million orders and also you needed to plot a histogram of the total_order_amount, it might be computationally wasteful to maneuver all 500 Million rows into your laptop computer, solely to combination it into 100 rows for a histogram chart. This SQL will produce the aggregated rows instantly from the warehouse, so plotting the histogram turns into quick & straightforward.
Right here’s an instance:
By configuring the SQL Generator with histogram, we are able to select what number of bins to make use of (100, on this instance).
The SQL will get generated as:
To recap, final week we regarded on the High 5 Most Widespread transforms, and we simply adopted that up with the High 5 Least Widespread.
Most Widespread — Correlation, Clear, Be a part of, Pivot, Combination
Least Widespread — MinMax Scaler, Newest, Shifting Avg, Entropy, Histogram
As you’ll be able to see, the favored transforms appear to be the straightforward, tedious ones, whereas the least fashionable appear to be essentially the most specialised, sophisticated ones.
Primarily based on my conversations with customers, additionally it is obvious that many aren’t conscious of what a few of these specialised transforms are supposed to do. So, hopefully, I’ve shared useful context in regards to the rarely-used ones, in order that if you end up in considered one of these uncommon conditions, you’ll have already got the code written for you.

{kind=link}