
However first, I needed to clear up one thing about my speak. I used to be mistaken once I stated that ELMo embeddings, utilized in Anago’s ELModel and obtainable in NERDS as ElmoNER, was subword-based, it’s truly character-based. My apologies to the viewers at PyData LA for deceptive and lots of due to Lan Guo for catching it and setting me straight.
The Transformer structure grew to become in style someday starting of 2019, with Google’s launch of the BERT (Bidirectional Encoder Representations from Transformers) mannequin. BERT was a language mannequin that was pre-trained on massive portions of textual content to foretell masked tokens in a textual content sequence, and to foretell the subsequent sentence given the earlier sentence. Over the course of the 12 months, many extra BERT-like fashions have been educated and launched into the general public area, every with some crucial innovation, and every performing a little bit higher than the earlier ones. These fashions may then be additional enhanced by the person group with smaller volumes of area particular texts to create domain-aware language fashions, or fine-tuned with fully totally different datasets for a wide range of downstream NLP duties, together with NER.
The Transformers library from Hugging Face offers fashions for numerous fine-tuning duties that may be referred to as out of your Pytorch or Tensorflow 2.x consumer code. Every of those fashions are backed by a particular Transformer language mannequin. For instance, the BERT-based fine-tuning mannequin for NER is the BertForTokenClassification class, the construction of which is proven under. Due to the Transformers library, you possibly can deal with this as a tensorflow.keras.Mannequin or a torch.nn.Module in your Tensorflow 2.x and Pytorch code respectively.
BertForTokenClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(28996, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(consideration): BertAttention(
(self): BertSelfAttention(
(question): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(worth): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
... 11 extra BertLayers (1) by (11) ...
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=8, bias=True)
)
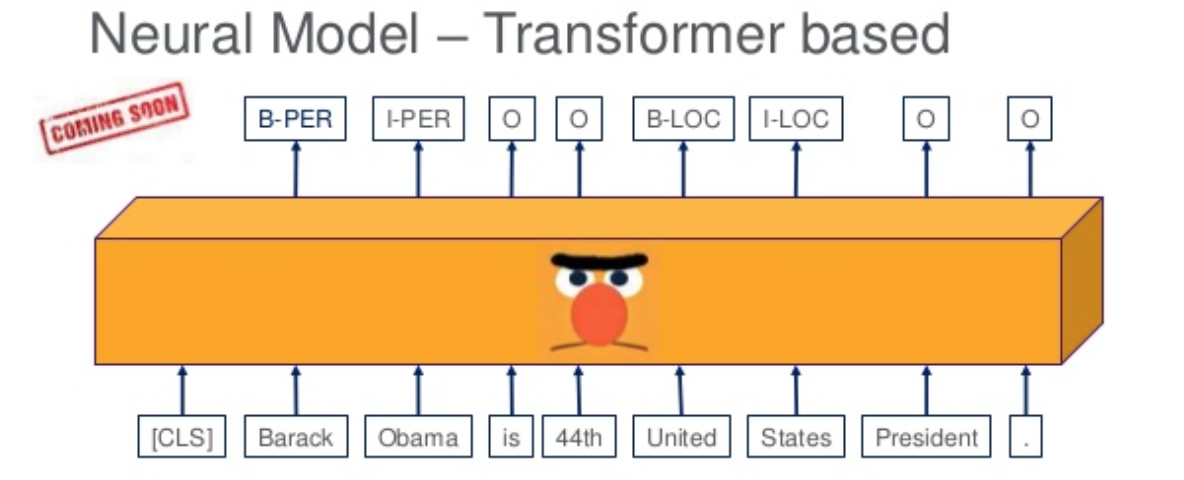
The determine under is from a slide in my speak, exhibiting at a excessive stage how fine-tuning a BERT primarily based NER works. Word that this setup is distinct from the setup the place you merely use BERT as a supply of embeddings in a BiLSTM-CRF community. In a fine-tuning setup reminiscent of this, the mannequin is actually the BERT language mannequin with a completely related community connected to its head. You fine-tune this community by coaching it with pairs of token and tag sequences and a low studying charge. Fewer epochs of coaching are wanted as a result of the weights of the pre-trained BERT language mannequin layers are already optimized and want solely be up to date a little bit to accommodate the brand new job.
There was additionally a query on the speak about whether or not there was a CRF concerned. I did not suppose there was a CRF layer on the time, however I wasn’t certain, however my understanding now’s that the TokenClassification fashions from the Hugging Face transformers library do not contain a CRF layer. That is primarily as a result of they implement the mannequin described within the paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin, Chang, Lee, and Toutanova, 2018), and that doesn’t use a CRF. There have been some experiments reminiscent of this one, the place the addition of a CRF didn’t appear to appreciably enhance efficiency.
Though utilizing the Hugging Face transformers library is a gigantic benefit in comparison with constructing these things up from scratch, a lot of the work in a typical NER pipeline is to pre-process our enter right into a kind wanted to coach or predict with the fine-tuning mannequin, and post-processing the output of the mannequin to a kind usable by the pipeline. Enter to a NERDS pipeline is in the usual IOB format. A sentence is provided as a tab separated file of tokens and corresponding IOB tags, reminiscent of that proven under:
Mr B-PER . I-PER Vinken I-PER is O chairman O of O Elsevier B-ORG N I-ORG . I-ORG V I-ORG . I-ORG , O the O Dutch B-NORP publishing O group O . O
This enter will get remodeled into the NERDS commonplace inside format (in my fork) as a listing of tokenized sentences and labels:
knowledge: [['Mr', '.', 'Vinken', 'is', 'chairman', 'of', 'Elsevier', 'N', '.', 'V', '.', ',',
'the', 'Dutch', 'publishing', 'group', '.']]
labels: [['B-PER', 'I-PER', 'I-PER', 'O', 'O', 'O', 'B-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'O',
'O', 'B-NORP', 'O', 'O', 'O']]
Every sequence of tokens then will get tokenized by the suitable word-piece tokenizer (in case of our BERT instance, the BertTokenizer, additionally offered by the Transformers library). Phrase-piece tokenization is a approach to get rid of or reduce the incidence of unknown phrase lookups from the mannequin’s vocabulary. Vocabularies are finite, and previously, if a token couldn’t be discovered within the vocabulary, it could be handled as an unknown phrase, or UNK. Phrase-piece tokenization tries to match complete phrases so far as doable, but when it isn’t doable, it should attempt to signify a phrase as an mixture of phrase items (subwords and even characters) which are current in its vocabulary. As well as (and that is particular to the BERT mannequin, different fashions have totally different particular tokens and guidelines about the place they’re positioned), every sequence must be began utilizing the [CLS] particular token, and separated from the subsequent sentence by the [SEP] particular token. Since we solely have a single sentence for our NER use case, the token sequence for the sentence is terminated with the [SEP] token. Thus, after tokenizing the info with the BertTokenizer, and making use of the particular tokens, the enter appears to be like like this:
[['[CLS]', 'Mr', '.', 'Vin', '##ken', 'is', 'chairman', 'of', 'El', '##se', '##vier', 'N', '.', 'V', '.', ',', 'the', 'Dutch', 'publishing', 'group', '.', '[SEP]']]
This tokenized sequence will should be featurized so it may be fed into the BertForTokenClassification community. The BertForTokenClassification solely mandates the input_ids and label_ids (for coaching), that are mainly ids for the matched tokens within the mannequin’s vocabulary and label index respectively, padded (or truncated) to the usual most sequence size utilizing the [PAD] token. Nevertheless, the code in run_ner.py instance within the huggingface/transformers repo additionally builds the attention_mask (often known as masked_positions) and token_type_ids (often known as segment_ids). The previous is a mechanism to keep away from performing consideration on [PAD] tokens, and the latter is used to tell apart between the positions for the primary and second sentence. In our case, since we’ve a single sentence, the token_type_ids are all 0 (first sentence).
There may be a further consideration with respect to word-piece tokenization and label IDs. Take into account the PER token sequence [‘Mr’, ‘.’, ‘Vinken’] in our instance. The BertTokenizer has tokenized this to [‘Mr’, ‘.’, ‘Vin’, ‘##ken’]. The query is how will we distribute our label sequence [‘B-PER’, ‘I-PER’, ‘I-PER’]. One risk is to disregard the ‘##ken’ word-piece and assign it the ignore index of -100. One other risk, advised by Ashutosh Singh, is to deal with the ‘##ken’ token as a part of the PER sequence, so the label sequence turns into [‘B-PER’, ‘I-PER’, ‘I-PER’, ‘I-PER’] as an alternative. I attempted each approaches and didn’t get a major efficiency bump by hook or by crook. Right here we undertake the technique of ignoring the ‘##ken’ token.
Here’s what the options appear like for our single instance sentence.
| input_ids | 101 1828 119 25354 6378 1110 3931 1104 2896 2217 15339 151 119 159 119 117 1103 2954 5550 1372 119 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 |
|---|---|
| attention_mask | 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 |
| token_type_ids | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 |
| labels | -100 5 6 6 -100 3 3 3 1 -100 -100 4 4 4 4 3 3 2 3 3 3 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 -100 |
On the output facet, throughout predictions, predictions will probably be generated towards the input_id, attention_mask, and token_type_ids, to provide predicted label_ids. Word that the predictions are on the word-piece stage and your labels are on the phrase stage. So along with changing your label_ids again to precise tags, you additionally have to just be sure you align the prediction and label IOB tags so they’re aligned.
The Transformers library offers utility code in its github repository to do many of those transformations, not just for its BertForTokenClassification mannequin, however for its different supported Token Classification fashions as effectively. Nevertheless, it doesn’t expose the performance by its library. Consequently, your choices are to both try and adapt the instance code to your personal Transformer mannequin, or copy over the utility code into your venture and import performance from it. As a result of a BERT primarily based NER was going to be solely one among many NERs in NERDS, I went with the primary possibility and concentrated solely on constructing a BERT primarily based NER mannequin. You may see the code for my BertNER mannequin. Sadly, I used to be not in a position to make it work effectively (and I feel I do know why as I write this submit, I’ll replace the submit with my findings if I’m able to make it carry out higher**).
As I used to be constructing this mannequin, adapting bits and items of code from the Transformers NER instance code, I might typically want that they’d make the performance accessible by the library. Luckily for me, Thilina Rajapakse, the creator of SimpleTransformers library, had the identical thought. SimpleTransformers is mainly a sublime wrapper on high of the Transformers library and its instance code. It exposes a quite simple and straightforward to make use of API to the consumer, and does a number of the heavy lifting behind the scenes utilizing the Hugging Face transformers library.
I used to be initially hesitant about having so as to add extra library dependencies to NERDS (a NER primarily based on the SimpleTransformers library wants the Hugging Face transformers library, which I had already, plus pandas and simpletransformers). Nevertheless, even aside from the plain maintainability side of fewer traces of code, a TransformerNER is probably in a position to make use of all of the language fashions supported by the underlying SimpleTransformers library – presently, the SimpleTransformers NERModel helps BERT, RoBERTa, DistilBERT, CamemBERT, and XLM-RoBERTa language fashions. So including a single TransformerNER to NERDS permits it to entry 5 totally different Transformer Language Mannequin backends! So the choice to change from a standalone BertNER that relied immediately on the Hugging Face transformers library, versus a TransformerNER that relied on the SimpleTransformers library was nearly a no brainer.
Right here is the code for the brand new TransformerNER mannequin in NERDS. As outlined in my earlier weblog submit about Incorporating the FLair NER into NERDS, you additionally have to listing the extra library dependencies, hook up the mannequin so it’s callable within the nerds.fashions package deal, create a brief repeatable unit check, and supply some utilization examples (with BioNLP, with GMB). Discover that, in comparison with the opposite NER fashions, we’ve a further name to align the labels and predictions — that is to right for the word-piece tokenization creating sequences which are too lengthy and due to this fact get truncated. A method round this might be to set a better maximum_sequence_length parameter.
Efficiency-wise, the TransformerNER with the BERT bert-base-cased mannequin scored the very best (common weighted F1-score) among the many NERs already obtainable in NERDS (utilizing default hyperparameters) towards each the NERDS instance datasets GMB and BioNLP. The classification experiences are proven under.
| GMB | BioNLP |
|---|---|
precision recall f1-score assist
artwork 0.11 0.24 0.15 97
eve 0.41 0.55 0.47 126
geo 0.90 0.88 0.89 14016
gpe 0.94 0.96 0.95 4724
nat 0.34 0.80 0.48 40
org 0.80 0.81 0.81 10669
per 0.91 0.90 0.90 10402
tim 0.89 0.93 0.91 7739
micro avg 0.87 0.88 0.88 47813
macro avg 0.66 0.76 0.69 47813
weighted avg 0.88 0.88 0.88 47813
|
precision recall f1-score assist
cell_line 0.80 0.60 0.68 1977
cell_type 0.75 0.89 0.81 4161
protein 0.88 0.81 0.84 10700
DNA 0.84 0.82 0.83 2912
RNA 0.85 0.79 0.82 325
micro avg 0.83 0.81 0.82 20075
macro avg 0.82 0.78 0.80 20075
weighted avg 0.84 0.81 0.82 20075
|
So anyway, actually simply needed to share the information that we now have a TransformerNER mannequin in NERDS utilizing which you leverage what’s just about the innovative in NLP expertise at present. I’ve been desirous to play with the Hugging Face transformers library for some time, and this appeared like a very good alternative initially, and the excellent news is that I’ve been in a position to apply this studying to less complicated architectures at work (single and double sentence fashions utilizing BertForSequenceClassification). Nevertheless, the SimpleTransformers library from Thilina Rajapakse undoubtedly made my job a lot simpler — due to his efforts, NERDS has an NER implementation that’s on the reducing fringe of NLP, and extra maintainable and highly effective on the identical time.
**Replace (Jan 21, 2020): I had thought that the poor efficiency I used to be seeing on the BERT NER was attributable to the inaccurate preprocessing (I used to be padding first after which including the [CLS] and [SEP] the place I ought to have been doing the other), so I fastened that, and that improved it considerably, however outcomes are nonetheless not similar to these from TransformerNER. I believe it might be the coaching schedule in run_ner.py which is unchanged in SimpleTransformers, in comparison with tailored (simplified) in case of my code.

{kind=link}