
Stipulations: Python fundamentals, Microsoft Excel
Variations: Python 3.10, Plotly 5.9
Learn Time: 45 minutes
Introduction
So that you need to find out about making information visualizations, huh? Properly, you’re in the precise spot!
Knowledge visualization is translating information into a visible illustration to make it simpler on the human eye. It makes speaking advanced concepts simpler, fast, and straightforward to observe. It’s tremendous necessary because it makes information extra accessible and digestible.
Plotly Specific makes it simple to start studying this course of. It’s an easy-to-use, high-level module that creates widespread figures akin to line graphs and scatter plots. Plotly was really the primary library I used after I began my journey in information!
On this tutorial, we’ll create information visualizations of well-liked YouTube channels utilizing Python, Plotly Specific, and Google Colab. We’ll use a histogram to have a look at subscriber counts, a pie chart to match video classes, and a field plot to seek out patterns within the years that creators began YouTubing.
Let’s get into it (yuh)!
Setting Up
First, go to colab.analysis.google.com and begin a “New pocket book”.
After that, be sure you have the most recent model of Python in your machine. You may test this by typing $ python --version within the Home windows command immediate or the terminal on Mac and Linux. It could be finest in case you had been working Python model 3.10 or above.
After you have checked this, pull up the Plotly Specific docs web page. It can come in useful whereas working. Lastly, obtain the dataset used for this tutorial from down under. There wouldn’t be an information visualization with out some information!
In regards to the Dataset
For this tutorial, we’ll use the “Most Subscribed YouTube Channels” dataset from Kaggle. The file known as most_subscribed_youtube_channels.csv. You may obtain it right here.
Because the title suggests, it incorporates information in regards to the prime 1000 YouTube channels.
There are seven columns:
-
rank: Rank of the channel as per whole subscribers (1-1000) -
youtuber: Channel title -
subscribers: Whole variety of followers -
video views: Whole views of all of the movies mixed -
video depend: Variety of movies uploaded -
class: Channel style -
began: The 12 months that the channel began
It seems to be one thing like:

We have now made acquaintance with our dataset. Now, let’s soar into some visualizations!
Importing the Knowledge to Google Colab
First issues first (I’m the realest), we’re going to import our information into our pocket book. After downloading your dataset, you need to return to your helpful dandy Google Colab pocket book.
Contained in the pocket book, go forward and enter the next:
from google.colab import recordsdata
uploaded = recordsdata.add()
Press the play button, and there shall be a immediate to add recordsdata out of your laptop. Look in your native drive for the dataset (most_subscribed_youtube_channels.csv) and add the file.
It’s best to have one thing like this!
Importing Pandas and Declaring a DataFrame
Pandas is essentially the most broadly used open supply Python bundle to carry out information analytics. To make use of it, we’ll import pandas as pd. pd serves because the alias (nickname) for referring to the Pandas bundle in our program.
After importing Pandas, we might want to import io. Doing it will allow us to import our information right into a DataFrame and work with file-related enter/output operations:
import pandas as pd
import io
After you have performed that, we have to create a Pandas DataFrame. A Pandas DataFrame shops information as a 2-dimensional desk in Python. As analysts, we need to be fast in producing graphs, so we are able to take our time analyzing and reporting our findings. And DataFrames are a good way to construction our information; they’re quick, simple to make use of, and integral to the Python information science ecosystem. You should utilize any shorthand title for the DataFrame variable, however for this instance, we’ll use df.
The df variable will retailer the DataFrame returned from the pd.read_csv() technique. To try this, you’d put in pd.read_csv(io.BytesIO(uploaded[file_name.csv])). This line reads our CSV (comma-separated worth) file and returns it as a DataFrame.
And lastly, use the show() perform to point out the df DataFrame.
It’s best to have the next after finishing the steps above:
import pandas as pd
import io
df = pd.read_csv(io.BytesIO(uploaded["most_subscribed_youtube_channels.csv"]))
show(df)
Your pocket book ought to now appear to be this:

Discover how in a number of the numeric columns, there are commas in between the numbers? Let’s take out the commas utilizing:
df = df.exchange(",", "")
show(df)
Right here, we’re utilizing the .exchange() technique to switch all occurrences of commas "," with nothing "".
For the following part, we shall be creating three totally different graphs:
- A histogram to have a look at subscriber depend.
- A pie chart to investigate video classes.
- A field plot to discover the totally different years folks begin YouTubing.
Let’s kick issues off with the histogram!
Part 1: Make a Histogram
Usually, folks will import their library throughout setup. Nevertheless, I wish to have my imports and graph code collectively. Subsequently, we’re going to import the Plotly Python bundle by writing import plotly.specific as px. px will function the alias for the bundle on this portion of the method. After you could have imported Plotly Specific, we shall be prepared to start out on our histogram!
The import assertion ought to be as follows:
import plotly.specific as px
Making a histogram in Plotly Specific is a lot simpler than you assume. Have you learnt how we create them? Drum roll, please… 🥁
fig = px.histogram(df, x="subscribers", title="Subscriber Depend")
fig.present()
Alright, let’s break down this line of code.
First, we have to declare a variable fig. fig will permit us to work with the Plotly Specific library that’s accessible utilizing the px alias. Bear in mind px from earlier? We use it to find out the kind of graph we need to make the most of. For instance, we typed out px.histogram() as a result of we needed to plot a histogram.
The arguments handed within the technique name are:
- The DataFrame
df. - The
xworth that must be displayed within the histogram. Since we’re taking a look at subscriber depend on this train, thexworth would be the title of the column that incorporates the subscribers information within the DataFrame. - The title for our graph. We do that by the
titlevariable. Be sure you put citation marks round them since they’re thought of a string.
After we do that, we’ll use fig.present(), and the pocket book ought to show one thing like this!

There may be a lot occurring proper now within the histogram, so let’s take it step-by-step.
The very first thing we need to do is take note of our axes. On the x-axis, we’ve our variable subscribers. On the y-axis, we’ve the depend of channels with subscribers in that vary. In histograms, the bars present us frequency reasonably than a stable variety of issues. For our instance, we are able to see a excessive frequency of YouTubers with between 0 and 40 million subscribers.
Additionally, a fast shoutout to the channel all the way in which on the finish that made it to 200 million (T-Collection). We already know their fan base is grinding.
Part 2: Make a Pie Chart
We’re going to do the identical factor we did earlier than, however this time we’ll create a pie chart. For this pie chart, we’re going to analyze the totally different video classes and the highest channel they belong to.
All we have to do is exchange px.histogram(df, x="subscribers") with px.pie(df, values="subscribers" names="class", title="YouTube Classes"):
import plotly.specific as px
fig = px.pie(df, values="subscribers", names="class", title="YouTube Classes")
fig.present()
Nevertheless, this time we have to cross the next arguments to our technique name:
-
valuesfrom our information that can symbolize a portion of the pie chart. -
namesthat can symbolize the names for these areas of the pie chart. For this half, you would wish to make use of a column with numeric values for thevaluesargument and a column with string values for thenamesvariable. -
titleto call the graph. You may select no matter title you need right here, however for the sake of this instance, we’ll name our graph “YouTube Classes”.
That’s it. All that’s left now’s to show the pie chart utilizing the fig.present() technique.
It’s best to find yourself with one thing like this:

Pie charts are very easy to learn. The larger the chunk, the better amount we’ve. We will see right here that the highest class in our dataset is Music (24.9%). Coming in at quantity two is Leisure (22.1%).
Part 3: Make a Field Plot
I hope you all aren’t too sq. to make a field plot. Field plots can present us how unfold out our information is. For this instance, we’re going to use a field plot to investigate the totally different years folks begin YouTube.
Sticking to the theme of simplicity, all we’ve to do to create our field plot is enter the next:
import plotly.specific as px
fig = px.field(df, y="began", title="Years Began")
fig.present()
The px.field() technique follows the conference we’ve been utilizing on this tutorial:
- First, we handed in our DataFrame,
df. - Then, we handed in our
yvariable,began. - Ending issues off, we named our graph “Years Began”.
And like earlier than, the graph is full however isn’t proven on the pocket book web page. So, to point out the graph, we use fig.present() technique.
It ought to look one thing like this:
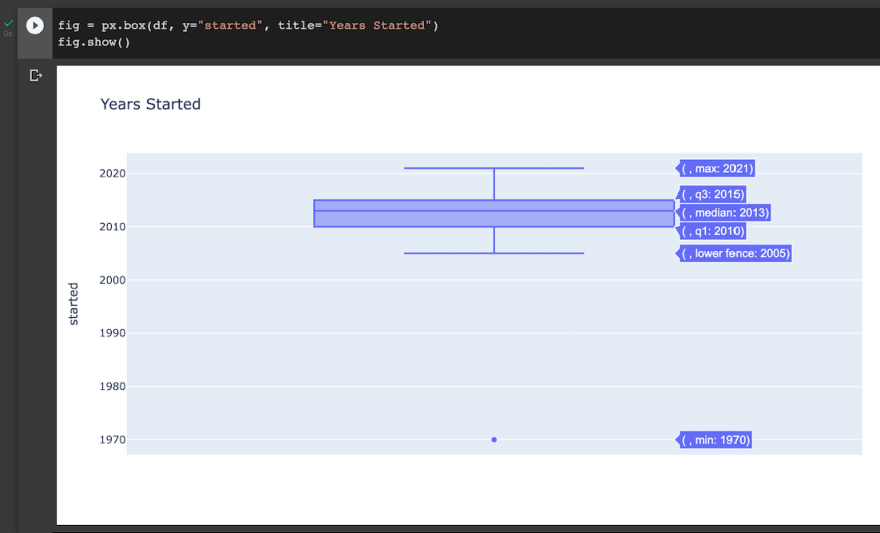
Like that one Tegan and Sara music, let’s get just a little bit nearer with our graph. In a field plot, we’ve our minimal worth, decrease fence, Q1, median, Q3, and most worth. For this tutorial, we’ll solely be taking a look at our decrease fence, median, and most.
- Within the decrease fence, we’ve the 12 months 2005. This conveys that the earliest prime channels acquired began in 2005. Speak about being there from the very begin!
- The median, 2013, represents the typical 12 months our prime channels began their profession. Ah, 2013. What a time to be alive.
- Our most worth was 2021. This was the most recent 12 months a prime channel in our dataset began. As they at all times say, it is by no means too late to start your journey to the highest!
Wrapping Up
Congrats, you simply created three information visualizations analyzing the highest canines on YouTube!
Many individuals assume information visualization is such a posh factor, however it may be as simple as working a number of traces of code. One piece of recommendation I’d provide you with is to follow utilizing one kind of library on your first few months of studying information visualizations. It offers you the chance to get the cling of issues and find out about your preferences.
Extra Sources
In regards to the Writer:
Miracle Awonuga is a senior at Belmont College learning Knowledge Science and Video Manufacturing. Currently, she has been engaged on WaffleHacks, a student-led hackathon because the Co-Director of Folks and Communications. 🧇

{kind=link}