
Methods to handle bigger portions of information

Pandas is arguably the most well-liked module in relation to knowledge manipulation with Python. It has large utility, accommodates an enormous number of options, and boasts substantial neighborhood help.
That being stated, Pandas has one obtrusive shortcoming: its efficiency ranges drop with bigger datasets.
The computational demand of processing bigger datasets with Pandas can incur long term instances and should even end in errors attributable to inadequate reminiscence.
Whereas it is perhaps tempting to pursue different instruments which are more proficient at coping with bigger datasets, it’s worthwhile to first discover the measures that may be taken to deal with huge portions of information with Pandas.
Right here, we cowl the methods customers can implement to preserve reminiscence and course of huge portions of information with Pandas.
Be aware: Every technique will probably be demonstrated with a faux dataset generated by Mockaroo.
1. Load much less knowledge
Eradicating columns from a knowledge body is a typical step in knowledge preprocessing.
Oftentimes, the columns are omitted after the info is loaded.
As an example, the next code masses the mock dataset after which omits all however 5 columns.
Whereas it is a possible method normally, it’s wasteful as you’re utilizing quite a lot of reminiscence to load knowledge that’s not even required. We are able to gauge the reminiscence utilization of the mock dataset with the memory_usage perform.

A preferable answer can be to omit undesirable columns throughout the info loading course of. It will be certain that reminiscence is barely used for the related data.
This may be achieved with the usecols parameter, which permits customers to pick the columns to incorporate whereas loading the dataset.
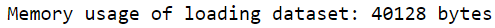
The inclusion of the parameter alone decreases reminiscence consumption by a major diploma.
2. Use memory-efficient knowledge sorts
Loads of reminiscence will be saved simply by deciding on the suitable knowledge sorts for the variables in query.
If the consumer doesn’t explicitly choose the info sort for every variable, the Pandas module will assign it by default.

Whereas this could be a handy function, the info sorts assigned to every column might not be best by way of reminiscence effectivity.
A key step in lowering reminiscence utilization lies in manually assigning the variables with essentially the most memory-efficient knowledge sort.
Knowledge Varieties For Numeric Variables
The Pandas module makes use of the int64 and float64 knowledge sorts for numeric variables.
The int64 and float64 knowledge sorts accommodate values with the best magnitude and precision. Nonetheless, in return, these knowledge sorts require essentially the most quantity of reminiscence.
Right here is the general reminiscence consumption of the mock dataset.
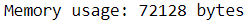
Thankfully, variables that take care of numbers with smaller magnitudes or precision don’t want such memory-consuming knowledge sorts.
For instance, within the mock dataset, smaller knowledge sorts will suffice for variables like age, weight, revenue, and peak. Let’s see how the reminiscence of the numeric knowledge modifications when assigning new knowledge sorts for these variables.
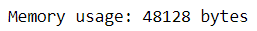
The straightforward act of changing knowledge sorts can cut back reminiscence utilization significantly.
Warning: Utilizing a knowledge sort that doesn’t accommodate the variables’ values will result in data loss. Watch out when assigning knowledge sorts manually.
Be aware that the revenue column was assigned the int32 knowledge sort as an alternative of the int8 knowledge sort for the reason that variable accommodates bigger values.
To spotlight the significance of choosing the proper knowledge sort, let’s examine the unique revenue values within the dataset with the revenue values with the int32 and int8 knowledge sorts.
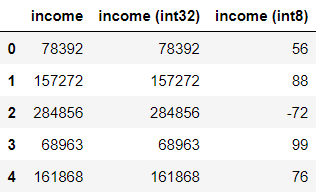
As proven by the output, selecting the flawed knowledge sort (int8 on this case) will alter the values and hamper the outcomes of any subsequent knowledge manipulation.
Having a transparent understanding of your knowledge and the vary of values afforded by the obtainable knowledge sorts (e.g., int8, int16, int32, and so on.) is crucial when assigning knowledge sorts for the variables of curiosity.
For reminiscence effectivity, apply is to specify knowledge sorts whereas loading the dataset with the dtype parameter.
Knowledge Varieties For Categorial Variables
Reminiscence will also be saved by assigning categorical variables the “class” knowledge sort.
For instance, let’s see how the reminiscence consumption modifications after assigning the “class” knowledge sort to the gender column.

Clearly, the conversion yields a major discount in reminiscence utilization.
Nonetheless, there’s a caveat to this method. Columns with the “class” knowledge sort devour extra reminiscence when it accommodates a bigger variety of distinctive values. Thus, this conversion isn’t viable for each variable.
To spotlight this, we are able to look at the impact of this conversion on the entire categorical variables within the knowledge body.

As proven by the output, though the gender and job columns have much less reminiscence utilization after the conversion, the first_name and last_name columns have higher reminiscence utilization. This may be attributed to a lot of distinctive first names and final names current within the dataset.
For that cause, train warning when assigning columns with the “class” knowledge sort when trying to protect reminiscence.
3. Load knowledge in chunks
For datasets which are too giant to slot in reminiscence, Pandas gives the chunk_size parameter, which permits customers to resolve what number of rows needs to be imported at every iteration.
When assigning a price to this parameter, the read_csv perform will return an iterator object as an alternative of an precise knowledge body.

Acquiring the info would require iterating by way of this object. By segmenting the big dataset into smaller items, knowledge manipulation will be carried out whereas staying throughout the reminiscence constraints.
Right here, we iterate by way of every subset of the dataset, filter the info, after which append it to an inventory.
After that, we merge all parts within the checklist along with the concat perform to acquire one complete dataset.
Limitations of Pandas
Pandas could have options that account for bigger portions of information, however they’re inadequate within the face of “huge knowledge”, which may comprise many gigabytes or terabytes of information.
The module carries out its operations in a single core of the CPU. Sadly, performing duties with one processor is solely infeasible as soon as reminiscence utilization and computational demand reaches a sure stage.
For such circumstances, it’s essential to implement strategies like parallel processing, which entails working a job throughout a number of cores of a machine.
Python gives libraries like Dask and PySpark that incorporate parallel processing and allow customers to execute operations at a lot higher speeds.
That being stated, these instruments primarily specialise in dealing with data-intensive duties and should not provide the identical options as Pandas. So, it’s best to not depend on them until it’s essential.
Conclusion
Whereas Pandas is principally used for small to medium-sized knowledge, it shouldn’t be shunned for duties that use marginally bigger datasets. The module possesses options that assist accommodate higher portions of information, albeit to a restricted extent.
The Pandas library has stood the take a look at of time and stays the go-to library for knowledge manipulation, so don’t be too keen to leap to different options until you completely must.
I want you the very best of luck together with your knowledge science endeavors!

{kind=link}