The 2021 State of DevOps report signifies that higher than 74% of organizations surveyed have Change Failure Fee (CFR) higher than 16% (the report gives a spread from 16% to 30%). Of those, a major proportion (> 35%) possible have CFRs exceeding 23%.
Because of this whereas organizations search to extend software program change velocity (as measured by the opposite DORA metrics within the report), a major variety of deployments lead to degraded service (or service outage) in manufacturing and subsequently require remediation (together with hotfix, rollback, repair ahead, patch and so forth.). The frequent failures doubtlessly impair income and buyer expertise, in addition to incur vital prices to remediate.
Most clients whom we communicate to are unable to proactively predict the danger of a change going into manufacturing. In truth, the 2021 State of Testing in DevOps report additionally signifies that higher than 70% of organizations surveyed usually are not assured in regards to the high quality of their releases. A smaller, however nonetheless vital, proportion (15%) “Launch and Pray” that their adjustments gained’t degrade manufacturing.
Reliability is a key product/service/system high quality metric. CFR is one among many reliability metrics. Different metrics embody availability, latency, thruput, efficiency, scalability, imply time between failures, amongst others. Whereas reliability engineering in software program has been a longtime self-discipline, we clearly have an issue making certain reliability.
With a purpose to guarantee reliability for software program methods, we have to set up practices that plan for, specify, engineer, measure and analyze reliability constantly alongside the DevOps life cycle. We name this “Steady Reliability” (CR).
Key Practices for Steady Reliability
Steady Reliability derives from the precept of “Steady All the things” in DevOps. The emergence (and adoption) of Website Reliability Engineering (SRE) ideas has led to CR evolving to be a key observe in DevOps and Steady Supply. In CR, the main focus is to take a steady proactive strategy at each step of the DevOps lifecycle to make sure that reliability targets will probably be met in manufacturing.
This suggests that we’re in a position to perceive and management the dangers of adjustments (and deployments) earlier than they make it to manufacturing.
The important thing pillars of CR are proven within the determine beneath:
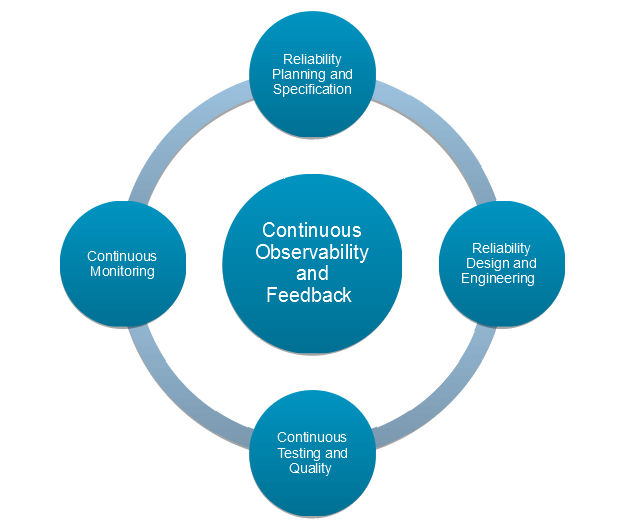
CR just isn’t, nevertheless, the purview of website reliability engineers (SREs) alone. Like different DevOps practices, CR requires lively collaboration amongst a number of personas comparable to SREs, product managers/homeowners, architects, builders, testers, launch/deployment engineers and operations engineers.
A few of the key practices for supporting CR (which might be overlaid on high of the core SRE ideas) are described beneath.
1) Steady Testing for Reliability
Steady Testing (CT) is a longtime observe in Steady Supply. Nevertheless, the usage of CT for steady reliability validation is much less widespread. Particularly for validation of the important thing reliability metrics (comparable to availability, latency, throughput, efficiency, scalability), many organizations nonetheless use waterfall-style efficiency testing, the place many of the testing is completed in lengthy length assessments earlier than launch. This not solely slows down the deployment, however does an incomplete job of validation.
Our really useful strategy is to validate these reliability metrics progressively at each step of the CI/CD lifecycle. That is described intimately in my prior weblog on Steady Efficiency Testing.
2) Steady Observability
Observability can also be a longtime observe in DevOps. Nevertheless, most observability options (comparable to Enterprise Companies Reliability) give attention to manufacturing knowledge and occasions.
What is required for CR is to “shift-left” observability into all levels of the CI/CD lifecycle, in order that reliability insights could be gleaned from pre-production knowledge (along side manufacturing knowledge). For instance, it’s doable to glean reliability insights from patterns of code adjustments (in supply code administration methods), take a look at outcomes and protection, in addition to efficiency monitoring by correlating such knowledge with previous failure/reliability historical past in manufacturing.
Pre-production environments are extra knowledge wealthy than manufacturing environments (when it comes to selection); nevertheless, many of the knowledge just isn’t correlated and mined for insights. Such observability requires us to arrange “methods of intelligence” (SOI, see determine beneath) the place we constantly accumulate and analyze pre-production knowledge alongside the CI/CD lifecycle to generate quite a lot of reliability predictions as and when functions change (see subsequent part).
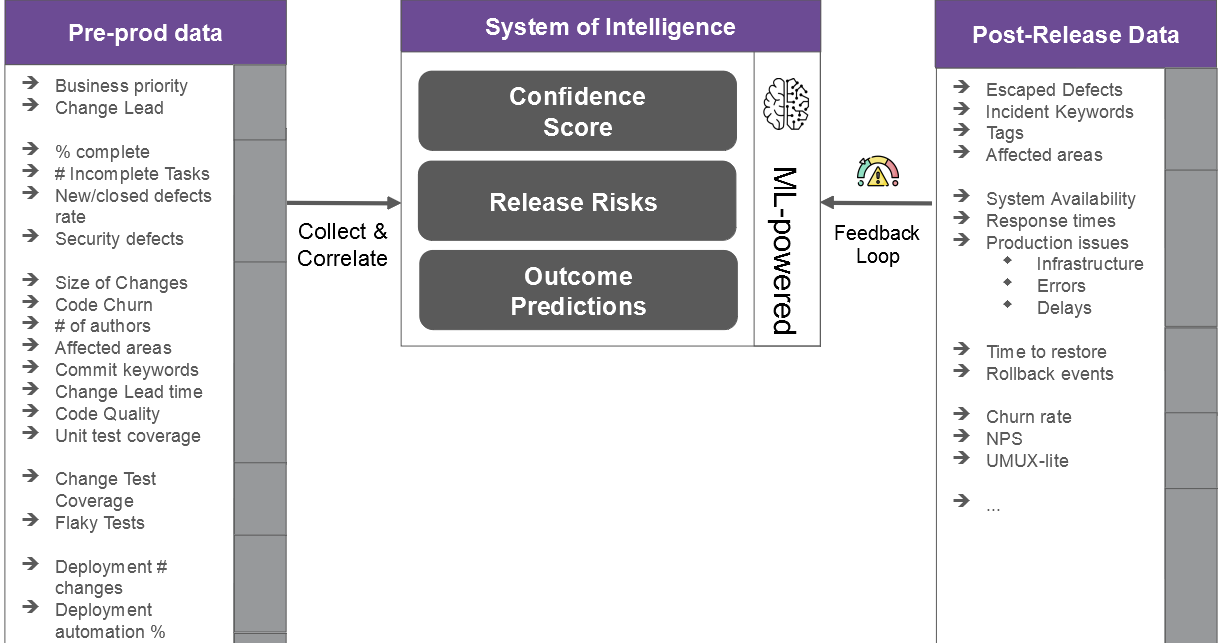
3) Steady Failure, Danger Insights and Prediction
An observability system in pre-production permits us to constantly assess and monitor failure threat alongside the CI/CD lifecycle. This permits us to proactively assess (and even predict) the failure threat related to adjustments.
For instance, we arrange a easy SOI for an utility (utilizing Google Analytics) the place I collected code change knowledge (from the supply code administration system) in addition to historical past of escaped defects (from previous deployments to manufacturing). By correlating such knowledge (gradient boosted tree algorithm), I used to be in a position to set up an understanding of what code change patterns resulted in increased ranges of escaped defects. On this case, I discovered a major correlation between code churn and defects leaked (see determine beneath).
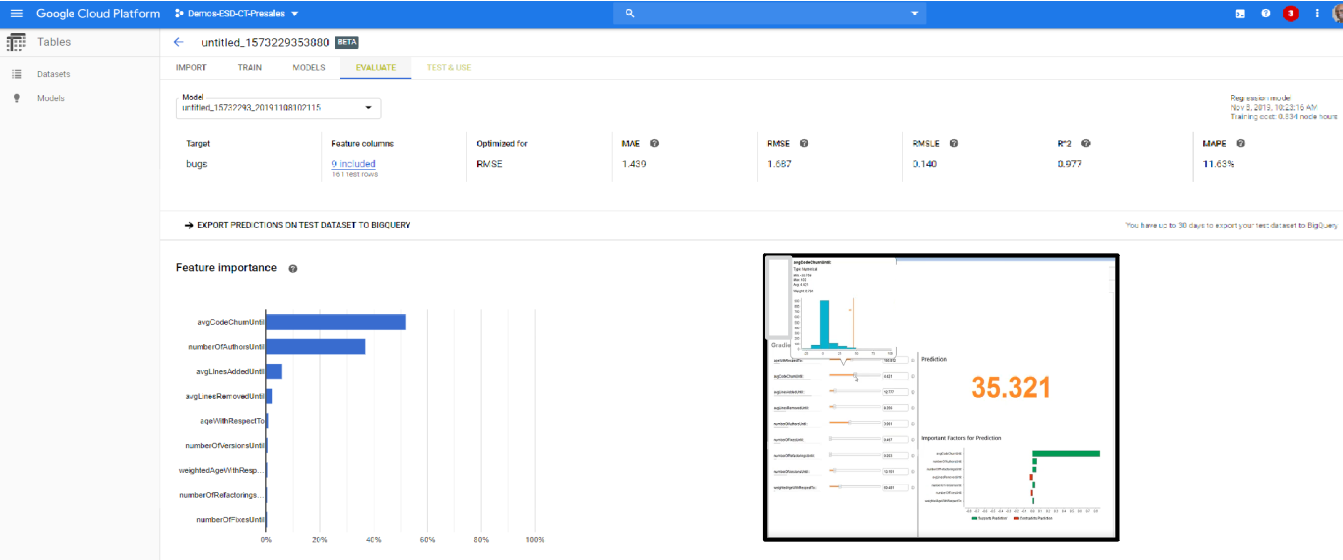
We had been then in a position to make use of the identical analytics to foretell how escaped defects would change based mostly on code churn in my present deployment (see inset within the determine above).
Whereas it is a quite simple instance of reliability prediction utilizing a restricted knowledge set, we will do steady failure threat prediction by exploiting a broader set of knowledge from pre-production, together with testing and deployment knowledge.
For instance, in my earlier article on Steady Efficiency Testing, I mentioned numerous approaches for efficiency testing of component-based functions. Such testing generates an enormous quantity of knowledge that’s extraordinarily troublesome to course of manually. An observability system can then be used to gather the information to determine baselines of part reliability and efficiency, and in flip used to generate insights when it comes to how system reliability could also be impacted by adjustments in particular person utility elements (or different system elements).
4) Steady Suggestions
One of many key advantages of an observability system is to have the ability to present fast and steady suggestions to the event/take a look at/launch/SRE groups on the danger related to adjustments and supply useful insights on how you can handle them. This is able to enable improvement groups to proactively handle these dangers earlier than the adjustments are deployed to manufacturing. For instance, improvement groups could be alerted as quickly as performing a commit (or a pull request) of the failure dangers related to the adjustments they’ve made. Testers can get suggestions on the assessments which might be crucial to run. Equally, SREs can get early planning insights into the extent of error budgets they should plan for the subsequent launch cycle.
Subsequent up: Steady High quality
Reliability, nevertheless, is only one dimension of utility/system high quality. It doesn’t, for instance, totally handle how we maximize buyer expertise that’s influenced by different components comparable to worth to customers, ease of use, and extra. With a purpose to get true worth from DevOps and Steady Supply initiatives, we have to set up practices for predictively attaining high quality – we name this “Steady High quality.” I’ll talk about this in my subsequent weblog.

{kind=link}