This put up discusses semi-supervised studying algorithms that be taught from proxy labels assigned to unlabelled information.
Notice: Elements of this put up are primarily based on my ACL 2018 paper Robust Baselines for Neural Semi-supervised Studying underneath Area Shift with Barbara Plank.
Desk of contents:
- Self-training
- Multi-view coaching
- Co-training
- Democratic Co-learning
- Tri-training
- Tri-training with disagreement
- Uneven tri-training
- Multi-task tri-training
- Self-ensembling
- Ladder networks
- Digital Adversarial Coaching
- (Pi) mannequin
- Temporal Ensembling
- Imply Trainer
- Associated strategies and areas
- Distillation
- Studying from weak supervision
- Studying with noisy labels
- Information augmentation
- Ensembling a single mannequin
Unsupervised studying constitutes one of many primary challenges for present machine studying fashions and one of many key parts that’s lacking for basic synthetic intelligence. Whereas unsupervised studying by itself remains to be elusive, researchers have a made loads of progress in combining unsupervised studying with supervised studying. This department of machine studying analysis is known as semi-supervised studying.
Semi-supervised studying has an extended historical past. For a (barely outdated) overview, seek advice from Zhu (2005) and Chapelle et al. (2006) . Significantly just lately, semi-supervised studying has seen some success, significantly decreasing the error fee on necessary benchmarks. Semi-supervised studying additionally makes an look in Amazon’s annual letter to shareholders the place it’s credited with decreasing the quantity of labelled information wanted to attain the identical accuracy enchancment by (40times).
On this weblog put up, I’ll concentrate on a selected class of semi-supervised studying algorithms that produce proxy labels on unlabelled information, that are used as targets along with the labelled information. These proxy labels are produced by the mannequin itself or variants of it with none extra supervision; they thus don’t replicate the bottom reality however would possibly nonetheless present some sign for studying. In a way, these labels could be thought of noisy or weak. I’ll spotlight the connection to studying from noisy labels, weak supervision in addition to different associated subjects in the long run of this put up.
This class of fashions is of specific curiosity in my view, as a) deep neural networks have been proven to be good at coping with noisy labels and b) these fashions have achieved state-of-the-art in semi-supervised studying for pc imaginative and prescient. Notice that many of those concepts usually are not new and lots of associated strategies have been developed up to now. In a single half of this put up, I’ll thus cowl basic strategies and focus on their relevance for present approaches; within the different half, I’ll focus on strategies which have just lately achieved state-of-the-art efficiency. A number of the following approaches have been known as self-teaching or bootstrapping algorithms; I’m not conscious of a time period that captures all of them, so I’ll merely seek advice from them as proxy-label strategies.
I’ll divide these strategies in three teams, which I’ll focus on within the following: 1) self-training, which makes use of a mannequin’s personal predictions as proxy labels; 2) multi-view studying, which makes use of the predictions of fashions educated with completely different views of the information; and three) self-ensembling, which ensembles variations of a mannequin’s personal predictions and makes use of these as suggestions for studying. I’ll present pseudo-code for crucial algorithms. You could find the LaTeX supply right here.
There are various fascinating and equally necessary instructions for semi-supervised studying that I can’t cowl on this put up, e.g. graph-convolutional neural networks .
Self-training
Self-training (Yarowsky, 1995; McClosky et al., 2006) is among the earliest and easiest approaches to semi-supervised studying and essentially the most easy instance of how a mannequin’s personal predictions could be integrated into coaching. Because the title implies, self-training leverages a mannequin’s personal predictions on unlabelled information in an effort to receive extra info that can be utilized throughout coaching. Usually essentially the most assured predictions are taken at face worth, as detailed subsequent.
Formally, self-training trains a mannequin (m) on a labeled coaching set (L) and an unlabeled information set (U). At every iteration, the mannequin gives predictions (m(x)) within the type of a likelihood distribution over the (C) courses for all unlabeled examples (x) in (U). If the likelihood assigned to the most definitely class is increased than a predetermined threshold (tau), (x) is added to the labeled examples with (DeclareMathOperator*{argmax}{argmax} p(x) = argmax m(x)) as pseudo-label. This course of is usually repeated for a hard and fast variety of iterations or till no extra predictions on unlabelled examples are assured. This instantiation is essentially the most extensively used and proven in Algorithm 1.
Traditional self-training has proven combined success. In parsing it proved profitable with small datasets (Reichart, and Rappoport, 2007; Huang and Harper, 2009) or when a generative element is used along with a reranker when extra information is out there (McClosky et al., 2006; Suzuki and Isozaki , 2008) . Some success was achieved with cautious task-specific information choice (Petrov and McDonald, 2012) , whereas others report restricted success on quite a lot of NLP duties (He and Zhou, 2011; Plank, 2011; Van Asch and Daelemans, 2016; van der Goot et al., 2017) .
The principle draw back of self-training is that the mannequin is unable to right its personal errors. If the mannequin’s predictions on unlabelled information are assured however improper, the inaccurate information is nonetheless integrated into coaching and the mannequin’s errors are amplified. This impact is exacerbated if the area of the unlabelled information is completely different from that of the labelled information; on this case, the mannequin’s confidence shall be a poor predictor of its efficiency.
Multi-view coaching
Multi-view coaching goals to coach completely different fashions with completely different views of the information. Ideally, these views complement one another and the fashions can collaborate in enhancing one another’s efficiency. These views can differ in numerous methods resembling within the options they use, within the architectures of the fashions, or within the information on which the fashions are educated.
Co-training Co-training (Blum and Mitchell, 1998) is a basic multi-view coaching methodology, which makes comparatively sturdy assumptions. It requires that the information (L) could be represented utilizing two conditionally impartial characteristic units (L^1) and (L^2) and that every characteristic set is adequate to coach a great mannequin. After the preliminary fashions (m_1) and (m_2) are educated on their respective characteristic units, at every iteration, solely inputs which can be assured (i.e. have a likelihood increased than a threshold (tau)) in accordance with precisely one of the 2 fashions are moved to the coaching set of the opposite mannequin. One mannequin thus gives the labels to the inputs on which the different mannequin is unsure. Co-training could be seen in Algorithm 2.
Within the unique co-training paper (Blum and Mitchell, 1998), co-training is used to categorise internet pages utilizing the textual content on the web page as one view and the anchor textual content of hyperlinks on different pages pointing to the web page as the opposite view. As two conditionally impartial views usually are not at all times out there, Chen et al. (2011) suggest pseudo-multiview regularization (Chen et al., 2011) in an effort to cut up the options into two mutually unique views in order that co-training is efficient. To this finish, pseudo-multiview regularization constrains the fashions in order that at the least certainly one of them has a zero weight for every characteristic. That is much like the orthogonality constraint just lately utilized in area adaptation to encourage shared and personal areas (Bousmalis et al., 2016) . A second constraint requires the fashions to be assured on completely different subsets of (U). Chen et al. (2011) use pseudo-multiview regularization to adapt co-training to area adaptation.
Democratic Co-learning Fairly than treating completely different characteristic units as views, democratic co-learning (Zhou and Goldman, 2004) employs fashions with completely different inductive biases. These could be completely different community architectures within the case of neural networks or utterly completely different studying algorithms. Democratic co-learning first trains every mannequin individually on the whole labelled information (L). The fashions then make predictions on the unlabelled information (U). If a majority of fashions confidently agree on the label of an instance, the instance is added to the labelled dataset. Confidence is measured within the unique formulation by measuring if the sum of the imply confidence intervals (w) of the fashions, which agreed on the label is bigger than the sum of the fashions that disagreed. This course of is repeated till no extra examples are added. The ultimate prediction is made with a majority vote weighted with the boldness intervals of the fashions. The total algorithm could be seen under. (M) is the set of all fashions that predict the identical label (j) for an instance (x).
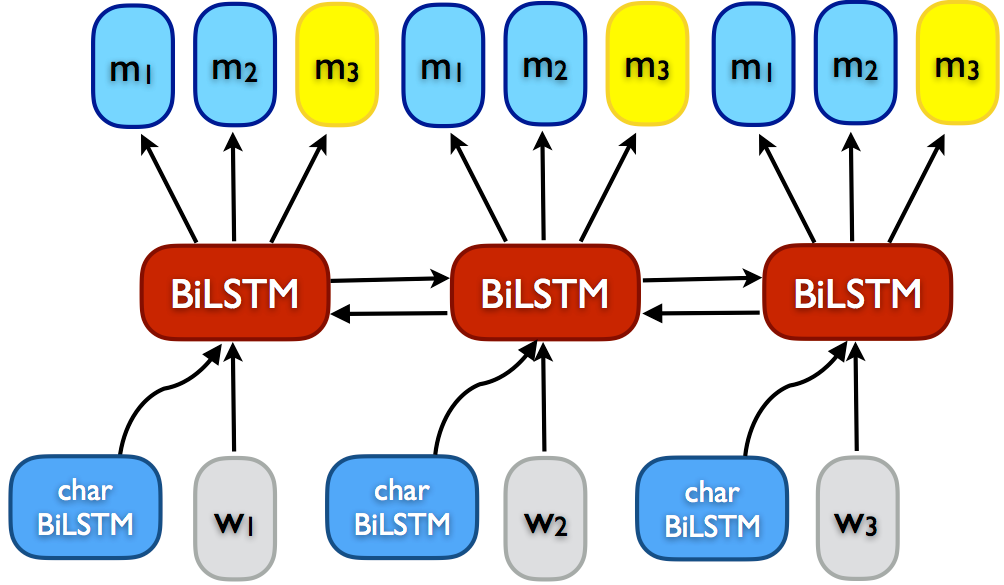
Tri-training Tri-training (Zhou and Li, 2005) is among the finest recognized multi-view coaching strategies. It may be seen as an instantiation of democratic co-learning, which leverages the settlement of three independently educated fashions to cut back the bias of predictions on unlabeled information. The principle requirement for tri-training is that the preliminary fashions are numerous. This may be achieved utilizing completely different mannequin architectures as in democratic co-learning. The most typical strategy to receive variety for tri-training, nonetheless, is to acquire completely different variations (S_i) of the unique coaching information (L) utilizing bootstrap sampling. The three fashions (m_1), (m_2), and (m_3) are then educated on these bootstrap samples, as depicted in Algorithm 4. An unlabeled information level is added to the coaching set of a mannequin (m_i) if the opposite two fashions (m_j) and (m_k) agree on its label. Coaching stops when the classifiers don’t change anymore.
Regardless of having been proposed greater than 10 years in the past, earlier than the arrival of Deep Studying, we present in a current paper (Ruder and Plank, 2018) that basic tri-training is a powerful baseline for neural semi-supervised with and with out area shift for NLP and that it outperforms even current state-of-the-art strategies.
Tri-training with disagreement Tri-training with disagreement (Søgaard, 2010) is predicated on the instinct {that a} mannequin ought to solely be strengthened in its weak factors and that the labeled information shouldn’t be skewed by simple information factors. So as to obtain this, it provides a easy modification to the unique algorithm (altering line 8 in Algorithm 4), requiring that for an unlabeled information level on which (m_j) and (m_k) agree, the opposite mannequin (m_i) disagrees on the prediction. Tri-training with disagreement is extra data-efficient than tri-training and has achieved aggressive outcomes on part-of-speech tagging (Søgaard, 2010).
Uneven tri-training Asymmetic tri-training (Saito et al., 2017) is a just lately proposed extension of tri-training that achieved state-of-the-art outcomes for unsupervised area adaptation in pc imaginative and prescient. For unsupervised area adaptation, the check information and unlabeled information are from a special area than the labelled examples. To adapt tri-training to this shift, uneven tri-training learns one of many fashions solely on proxy labels and never on labelled examples (a change to line 10 in Algorithm 4) and makes use of solely this mannequin to categorise goal area examples at check time. As well as, all three fashions share the identical characteristic extractor.
Multi-task tri-training Tri-training sometimes depends on coaching separate fashions on bootstrap samples of a doubtlessly great amount of coaching information, which is dear. Multi-task tri-training (MT-Tri) (Ruder and Plank, 2018) goals to cut back each the time and area complexity of tri-training by leveraging insights from multi-task studying (MTL) (Caruana, 1993) to share data throughout fashions and speed up coaching. Fairly than storing and coaching every mannequin individually, MT-Tri shares the parameters of the fashions and trains them collectively utilizing MTL. Notice that the mannequin does solely pseudo MTL as all three fashions successfully carry out the identical job.
The output softmax layers are model-specific and are solely up to date for the enter of the respective mannequin. Because the fashions leverage a joint illustration, variety is much more essential. We have to be certain that the options used for prediction within the softmax layers of the completely different fashions are as numerous as attainable, in order that the fashions can nonetheless be taught from one another’s predictions. In distinction, if the parameters in all output softmax layers had been the identical, the tactic would degenerate to self-training. Just like pseudo-view regularization, we thus use an orthogonality constraint (Bousmalis et al., 2016) on two of the three softmax output layers as an extra loss time period.
The pseudo-code could be seen under. In distinction to basic tri-training, we will prepare the multi-task mannequin with its three model-specific outputs collectively and with out bootstrap sampling on the labeled supply area information till convergence, because the orthogonality constraint enforces completely different representations between fashions (m_1) and (m_2). From this level, we will leverage the pair-wise settlement of two output layers so as to add pseudo-labeled examples as coaching information to the third mannequin. We prepare the third output layer (m_3) solely on pseudo-labeled goal cases in an effort to make tri-training extra sturdy to a site shift. For the ultimate prediction, we use majority voting of all three output layers. For extra details about multi-task tri-training, self-training, different tri-training variants, you’ll be able to seek advice from our current ACL 2018 paper.
Self-ensembling
Self-ensembling strategies are similar to multi-view studying approaches in that they mix completely different variants of a mannequin. Multi-task tri-training, as an illustration, can be seen as a self-ensembling methodology the place completely different variations of a mannequin are used to create a stronger ensemble prediction. In distinction to multi-view studying, variety just isn’t a key concern. Self-ensembling approaches principally use a single mannequin underneath completely different configurations in an effort to make the mannequin’s predictions extra sturdy. A lot of the following strategies are very current and a number of other have achieved state-of-the-art leads to pc imaginative and prescient.
Ladder networks The (Gamma) (gamma) model of Ladder Networks (Rasmus et al., 2015) goals to make a mannequin extra sturdy to noise. For every unlabelled instance, it makes use of the mannequin’s prediction on the clear instance as a proxy label for prediction on a perturbed model of the instance. This manner, the mannequin learns to develop options which can be invariant to noise and predictive of the labels on the labelled coaching information. Ladder networks have been principally utilized in pc imaginative and prescient the place many types of perturbation and information augmentation can be found.
Digital Adversarial Coaching If perturbing the unique pattern just isn’t attainable or desired, we will as an alternative perturb the instance in characteristic area. Fairly than randomly perturbing it by e.g. including dropout, we will apply the worst attainable perturbation for the mannequin, which transforms the enter into an adversarial pattern. Whereas adversarial coaching requires entry to the labels to carry out these perturbations, digital adversarial coaching (Miyato et al., 2017) requires no labels and is thus appropriate for semi-supervised studying. Digital adversarial coaching successfully seeks to make the mannequin sturdy to perturbations in instructions to which it’s most delicate and has achieved good outcomes on textual content classification datasets.
(Pi) mannequin Fairly than treating clear predictions as proxy labels, the (Pi) (pi) mannequin (Laine and Aila, 2017) ensembles the predictions of the mannequin underneath two completely different perturbations of the enter information and two completely different dropout situations (z) and (tilde{z}). The total pseudo-code could be seen in Algorithm 6 under. (g(x)) is the stochastic enter augmentation operate. The primary loss time period encourages the predictions underneath the 2 completely different noise settings to be constant, with (lambda) figuring out the contribution, whereas the second loss time period is the usual cross-entropy loss (H) with respect to the label (y). In distinction to the fashions we encountered earlier than, we apply the unsupervised loss element to each unlabelled and labelled examples.
Temporal Ensembling As a substitute of ensembling over the identical mannequin underneath completely different noise configurations, we will ensemble over completely different fashions. As coaching separate fashions is dear, we will as an alternative ensemble the predictions of a mannequin at completely different timesteps. We are able to save the ensembled proxy labels (Z) as an exponential shifting common of the mannequin’s previous predictions on all examples as depicted under in an effort to save area. As we initialize the proxy labels as a zero vector, they’re biased in direction of (0). We are able to right this bias much like Adam (Kingma and Ba, 2015) primarily based on the present epoch (t) to acquire bias-corrected goal vectors (tilde{z}). We then replace the mannequin much like the (Pi) mannequin.
Imply Trainer Lastly, as an alternative of averaging the predictions of our mannequin over coaching time, we will common the mannequin weights. Imply instructor (Tarvainen and Valpola, 2017) shops an exponential shifting common of the mannequin parameters. For each instance, this imply instructor mannequin is then used to acquire proxy labels (tilde{z}). The consistency loss and supervised loss are computed as in temporal ensembling.
Imply instructor has achieved state-of-the-art outcomes for semi-supervised studying for pc imaginative and prescient. For reference, on ImageNet with 10% of the labels, it achieves an error fee of (9.11), in comparison with an error fee of (3.79) utilizing all labels with the state-of-the-art. For extra details about self-ensembling strategies, take a look at this intuitive weblog put up by the Curious AI firm. We’ve run experiments with temporal ensembling for NLP duties, however didn’t handle to acquire constant outcomes. My assumption is that the unsupervised consistency loss is extra appropriate for steady inputs. Imply instructor would possibly work higher, as averaging weights aka Polyak averaging (Polyak and Juditsky, 1992) is a tried methodology for accelerating optimization.
Very just lately, Oliver et al. (2018) elevate some questions relating to the true applicability of those strategies: They discover that the efficiency distinction to a correctly tuned supervised baseline is smaller than sometimes reported, that switch studying from a labelled dataset (e.g. ImageNet) outperforms the introduced strategies, and that efficiency degrades severely underneath a site shift. So as to cope with the latter, algorithms resembling uneven or multi-task tri-training be taught completely different representations for the goal distribution. It stays to be seen if these insights translate to different domains; a mixture of switch studying and semi-supervised adaptation to the goal area appears notably promising.
Distillation Proxy-label approaches could be seen as completely different types of distillation (Hinton et al., 2015) . Distillation was initially conceived as a way to compress the knowledge of a big mannequin or an ensemble in a smaller mannequin. In the usual setup, a sometimes massive and totally educated instructor mannequin gives proxy targets for a scholar mannequin, which is usually smaller and sooner. Self-learning is akin to distillation with out a instructor, the place the scholar is left to be taught by themselves and with no-one to right its errors. For multi-view studying, completely different fashions work collectively to show one another, alternately performing as each lecturers and college students. Self-ensembling, lastly, has one mannequin assuming the twin function of instructor and scholar: As a instructor, it generates new targets, that are then integrated by itself as a scholar for studying.
Studying from weak supervision Studying from weak supervision, because the title implies, could be seen as a weaker type of supervised studying or alternatively as a stronger type of semi-supervised studying: Whereas supervised studying gives us with labels that we all know to be right and semi-supervised studying solely gives us with a small set of labelled examples, weak supervision permits us to acquire labels that we all know to be noisy for the unlabelled information as an additional sign for studying. Usually, the weak annotator is an unsupervised methodology that could be very completely different from the mannequin we use for studying the duty. For sentiment evaluation, this could possibly be a easy lexicon-based methodology . Lots of the introduced strategies could possibly be prolonged to the weak supervision setting by incorporating the weak labels as suggestions. Self-ensembling strategies, as an illustration, would possibly make use of one other instructor mannequin that gauges the standard of weakly annotated examples much like Deghani et al. (2018) . For an outline of weak supervision, take a look at this weblog put up by Stanford’s Hazy Analysis group.
Studying with noisy labels Studying with noisy labels is much like studying from weak supervision. In each circumstances, labels can be found that can not be utterly trusted. For studying with noisy labels, labels are sometimes assumed to be permuted with a hard and fast random permutation. Whereas proxy-label approaches provide the noisy labels themselves, when studying with noisy labels, the labels are a part of the information. Just like studying from weak supervision, we will attempt to mannequin the noise to evaluate the standard of the labels (Sukhbaatar et al., 2015) . Just like self-ensembling strategies, we will implement consistency between the mannequin’s preditions and the proxy labels (Reed et al., 2015) .
Information augmentation A number of self-ensembling strategies make use of information augmentation to implement consistency between mannequin predictions underneath completely different noise settings. Information augmentation is generally utilized in pc imaginative and prescient, however noise within the type of completely different dropout masks can be utilized to the mannequin parameters as within the (Pi) mannequin and has additionally been utilized in LSTMs (Zolna et al., 2018) . Whereas regularization within the type of dropout, batch normalization, and many others. can be utilized when labels can be found in an effort to make predictions extra sturdy, a consistency loss is required within the case with out labels. For supervised studying, adversarial coaching could be employed to acquire adversarial examples and has been used efficiently e.g. for part-of-speech tagging (Yasunaga et al., 2018) .
Ensembling a single mannequin The mentioned self-ensembling strategies all make use of ensemble predictions not simply to make predictions extra sturdy, however as suggestions to enhance the mannequin itself throughout coaching in a self-reinforcing loop. Within the supervised setting, this suggestions may not be mandatory; ensembling a single mannequin remains to be helpful, nonetheless, to avoid wasting time in comparison with coaching a number of fashions. Two strategies which were proposed to ensemble a mannequin from a single coaching run are checkpoint ensembles and snapshot ensembles. Checkpoint ensembles (Sennrich et al., 2016) ensemble the final (n) checkpoints of a single coaching run and have been used to attain state-of-the-art in machine translation. Snapshot ensembles (Huang et al., 2017) ensemble fashions converged to completely different minima throughout a coaching run and have been used to attain state-of-the-art in object recognition.
Conclusion
I hope this put up was in a position to provide you with an perception into part of the semi-supervised studying panorama that appears to be notably helpful to enhance the efficiency of present fashions. Whereas studying utterly with out labelled information is unrealistic at this level, semi-supervised studying allows us to enhance our small labelled datasets with massive quantities of obtainable unlabelled information. A lot of the mentioned strategies are promising in that they deal with the mannequin as a black field and might thus be used with any current supervised studying mannequin. As at all times, if in case you have any questions or observed any errors, be at liberty to jot down a remark within the feedback part under.

{kind=link}