Applicable knowledge sampling strategies matter for coaching an excellent mannequin
Knowledge sampling in mannequin coaching is an missed space in machine studying. Machine studying has two sides: modeling and knowledge. Each of them are equally essential and ought to be thought of rigorously in a real-life machine studying venture. Nonetheless, many textbooks, papers, blogs discuss concerning the modeling aspect, solely few of them discuss concerning the knowledge aspect.
We use ‘knowledge’ as an alternative of ‘dataset’ right here as a result of their ideas are completely different: ‘dataset’ is finite, mounted, and stationary, whereas ‘knowledge’ is infinite, unfixed, and dynamic. After we prepare a mannequin, we don’t have entry to all of the corresponding attainable knowledge on the planet; the information for use is a subset created by some sampling strategies. Knowledge is filled with potential biases, probably as a consequence of some human components throughout gathering, sampling, or labeling of the information. For the reason that biases are perpetuated within the fashions educated on this knowledge, sampling applicable subsets that may cut back the biases within the knowledge is essential.
Subsequently, understanding completely different sampling strategies is essential in that first, it helps us keep away from potential biases within the knowledge and second, it helps us to enhance the information effectivity in coaching.
Throughout knowledge sampling, with a purpose to prepare dependable fashions, the sampled subsets ought to characterize the real-world knowledge to scale back the choice biases [1]. Fortuitously, probabilistic knowledge sampling strategies can assist us notice this. Right here, I’ll introduce 5 consultant probabilistic knowledge sampling strategies in mannequin coaching.
Easy Random Sampling
It’s the easiest type of probabilistic sampling. All of the samples within the inhabitants have the identical probability of being sampled, thus their chances type a uniform distribution. For instance, if you wish to pattern 5 out of a ten inhabitants, the chance of each factor being chosen is 0.5.
The strategy is easy and straightforward to implement, however the uncommon courses within the inhabitants may not be sampled within the choice. Suppose you wish to pattern 1% out of your knowledge, however a uncommon class seems solely in 0.01% of the inhabitants: samples of this uncommon class may not be chosen. On this situation, fashions educated with the sampled subsets may not know the existence of the uncommon class.
Stratified Sampling
To keep away from the drawbacks of easy random sampling, you may divide the inhabitants to a number of teams in accordance with your necessities, for instance the labels, and pattern from every group individually. Every group is known as a stratum and this technique is known as stratified sampling.
For instance, to pattern 1% of a inhabitants that has courses A and B, you may divide the inhabitants to 2 teams and pattern 1% from the 2 teams, respectively. On this means, irrespective of how uncommon A or B is, the sampled subsets are ensured to comprise each of the 2 courses.
Nonetheless, a downside of stratified sampling is that the inhabitants is just not at all times dividable. For instance, in a multi-label studying activity by which every pattern has a number of labels, it’s difficult to divide the inhabitants in accordance with completely different labels.
Weighted Sampling
In weighted sampling, every pattern is assigned a weight—the chance of being sampled. For instance, for a inhabitants containing courses A and B, when you assign weights of 0.8 to class A and 0.2 to class B, the chances of being sampled for sophistication A and B are 80% and 20%, respectively.
Weight sampling can leverage area experience, which is essential for decreasing sampling biases. For instance, in coaching some on-line studying fashions, latest knowledge is rather more essential than previous knowledge. By means of assigning greater weights to latest knowledge and smaller weights to previous knowledge, you may prepare a mannequin extra reliably.
Reservoir Sampling
Reservoir sampling is an fascinating and stylish algorithm to cope with streaming knowledge in on-line studying fashions, which is sort of well-liked in merchandise.
Suppose the information is generated in a sequential streaming method, for instance, a time collection, and you may’t match all the information to the reminiscence, nor have you learnt how a lot knowledge will probably be generated sooner or later. You could pattern a subset with ok samples to coach a mannequin, however you don’t know which pattern to pick out as a result of many samples haven’t been generated but.
Reservoir sampling can cope with this downside that 1) all of the samples are chosen with equal chance and a couple of) when you cease the algorithm at any time, the samples are at all times chosen with appropriate chance. The algorithm incorporates 3 steps:
- Put the primary ok samples in a reservoir, which may very well be an array or a listing
- When the nth pattern is generated, randomly choose a quantity m throughout the vary of 1 to n. If the chosen quantity m is throughout the vary of 1 to ok, exchange the mth pattern within the reservoir with the nth generated pattern, in any other case do nothing.
- Repeat 2 till the cease of algorithm.
We will simply show that for every newly generated pattern, the chance of being chosen to the reservoir is ok/n. We will additionally show that for every pattern that’s already within the reservoir, the chance of not being changed can be ok/n. Thus when the algorithm stops, all of the samples within the reservoir are chosen with appropriate chance.
Significance Sampling
Significance sampling is likely one of the most essential sampling strategies. It permits us to pattern from a distribution after we solely have entry to a different distribution.
For instance, we wish to pattern from a distribution P(x), however can’t entry it. Nonetheless, we are able to entry one other distribution Q(x). The next equation exhibits that, in expectation, x sampled from P(x) equals to x sampled from Q(x) weighted by P(x)/Q(x).
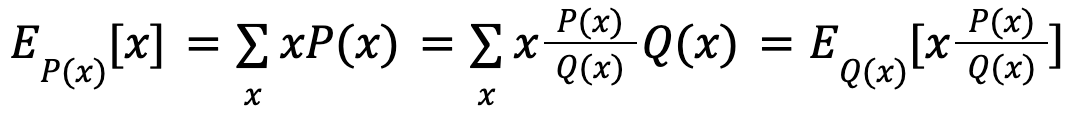
Subsequently, as an alternative of sampling from P(x), we are able to alternatively pattern from Q(x) which is accessible, and weight the sampled outcomes by P(x)/Q(x). The outcomes are the identical as we immediately pattern from P(x).
Conclusion
On this publish, I launched 5 consultant probabilistic knowledge sampling strategies for mannequin coaching. These strategies are task-agnostic, and can be utilized in all duties throughout varied machine studying areas: pc imaginative and prescient, NLP, reinforcement studying, and tabular knowledge evaluation, and so forth. Which sampling strategies to make use of is determined by the particular duties, datasets, downside settings, and what you need out of your fashions. I recommend utilizing a easy one like easy random sampling at first, and altering to different strategies as your understanding will get deeper. You would possibly discover it tough at first look, however issues will get clear with the progress of mannequin coaching and knowledge monitoring.
