Steady enchancment of knowledge science initiatives requires dedication to the grind
One of many extra underappreciated features of organizations with comparatively mature knowledge science groups is a robust tradition of steady enchancment. Within the context of technical groups liable for the creation and upkeep of complicated software program options, it’s particularly essential to interact in practices that enhance the general high quality of a group’s code base. Whether or not it’s present processes which are already in manufacturing or standardized packages/code to perform repeatable duties, periodic & rigorous code evaluate advantages each main and tertiary stakeholders by lowering the opportunity of errors, safety points, and useful resource utilization.
Reviewing code another person has written, usually with little documentation or context, may be tough and unsightly at occasions. However that’s how the sausage is made.
Right here I illustrate an instance the place I used to be in a position to considerably cut back max compute area and total processing time required for a program to run. What’s actually cool is I wasn’t initially in search of to try this; it arose from an initiative designed to retool that program to carry out higher on a set of established KPIs. Typically the most effective issues occur once you aren’t anticipating them.
First, some context. At a sure level, this system (written in Python) takes a random pattern of a set of objects and information key metrics for that group. It does this many occasions. The target is to determine a pattern of objects that maximize the values of the important thing metrics, for use at a later time. Whereas reviewing the code for correctness, I recognized one thing that considerably added to total runtime and reminiscence utilization that didn’t have to be there.
The problem arose in how the outcomes of the random pattern was being saved. Because the pattern was wanted in later steps, this system initially created a listing that saved a pandas DataFrame of every pattern for every iteration utilizing a for loop. Whereas this served it’s objective, the scale of the record in reminiscence elevated as a operate of two variables: the variety of iterations within the for loop, in addition to the scale of the pattern being taken. For comparatively small samples and iterations, this course of runs wonderful. However what occurs in case you enhance the pattern measurement from, say, 1,000 to 100,000 and the variety of iterations from 5,000 to 500,000? It might probably drastically alter required reminiscence utilization— and no matter your tech stack, inefficient applications price actual cash to a corporation by way of pointless compute sources and wasted time.
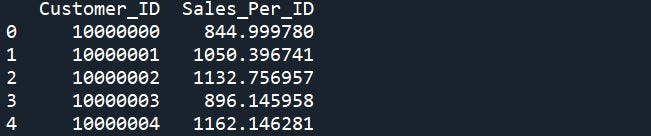
Shortly, let’s construct an instance set of knowledge as an instance the problem. We’ll use an instance of purchaser IDs with gross sales for a particular timeframe; it might be gross sales particular to a set of merchandise, gross sales channel, geographic location, and so forth. — use your creativeness!
import pandas as pd
import numpy as np# Set what number of iterations to run, & measurement of ID pattern in every iteration
n_iters = 100000
smpl_sz = 500000# Create a pattern df with 10MM distinctive IDs
# - Generate some dummy gross sales knowledge to play with later
id_samp = pd.DataFrame(vary(10000000,20000000))
id_samp.columns = ['Customer_ID']
id_samp['Sales_Per_ID'] = np.random.regular(loc = 1000, scale = 150, measurement = len(id_samp))
print(id_samp.head())
As mentioned, this system initially saved every pattern because it was generated in a grasp record — which introduces pattern measurement into the reminiscence storage equation. This could get even worse with dearer knowledge objects, i.e. strings or user-created objects vs. integers.
# Unique model
# Initialize knowledge objects to retailer pattern, information for every iteration’s pattern
metric_of_interest = []
samples = []# Within the loop, retailer every pattern because it's created
for i in vary(n_iters):
samp = id_samp.pattern(n = smpl_sz, axis = ‘rows’, random_state = i)
samples.append(samp)
# Do one thing with the pattern & document add’l information as crucial
metric_of_interest.append(samp[‘Sales_Per_ID’].imply())
The important thing right here is that we don’t should retailer every pattern because it’s created to be able to entry it afterward. We will benefit from the inherent properties of the random sampling operate to make use of a random seed for reproducibility. I gained’t delve into the usage of random seeds as a finest observe; however right here’s one other Medium article with a fairly thorough rationalization, and right here you’ll be able to see some NumPy and Pandas documentation about utilizing seeds/random states. The primary takeaway is that an integer worth can be utilized to “decide the beginning” of the sampling course of; so in case you retailer the worth you’ll be able to reproduce the pattern. On this method, we have been in a position to eradicate the impact of pattern measurement and knowledge sorts on reminiscence utilization by optimizing our storage methodology.
The consequence will probably be to create a randomly chosen group of integers with 1 worth per loop iteration to create samples. Under I present my very own distinctive technique for randomly deciding on these integers, however this may be achieved in some ways.
# Create a random pattern of integers to be used as ID pattern random state seed
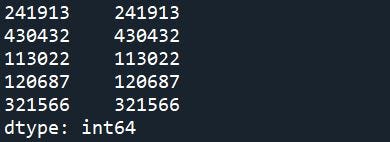
#Right here, we pull a seq of nums 50x better than num iters to samp from
rndm_st_sd_pop = pd.Sequence(vary(0,n_iters*50))
rndm_st_sd_samp = rndm_st_sd_pop.pattern(n = n_iters, axis = ‘rows’)
del(rndm_st_sd_pop)
print(rndm_st_sd_samp.head())
Be aware: the index and random seed worth are equal on this instance
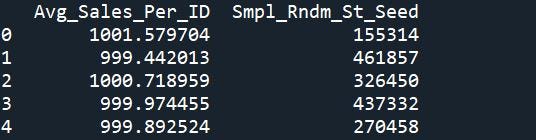
Now, you’ll be able to iterate by way of your random seed pattern and feed every worth as a parameter to the sampling operate. Needless to say this parameter ought to exist for any sampling operate price utilizing, no matter language.
# Initialize knowledge object(s) to retailer information for every iter’s pattern
metric_of_interest = []# Within the loop, use the random state/seed to provide a pattern you'll be able to simply reproduce later
for i in rndm_st_sd_samp:
samp = id_samp.pattern(n = smpl_sz, axis = ‘rows’, random_state = i)
# Do one thing with the pattern & document add’l information as crucial
metric_of_interest.append(samp[‘Sales_Per_ID’].imply())# Bind the data saved for every iter to resp seed val for simple lookup
sample_data = pd.DataFrame(
{'Avg_Sales_Per_ID': metric_of_interest,
'Smpl_Rndm_St_Seed': rndm_st_sd_samp })
sample_data.reset_index(inplace = True)
print(sample_data.head())