
Consideration is a cognitive and behavioral perform that provides us the power to focus on a tiny portion of the incoming info selectively, which is advantageous to the duty we’re attending. It offers the mind the power to restrict the quantity of its inputs by ignoring irrelevant perceptible info and deciding on high-value info. Once we observe a scene with a particular necessary half associated to the duty we’re doing, we extract that half to course of extra meticulously; we will be taught to concentrate on these elements extra optimally when these scenes seem once more.
In accordance with J. Ok Tsotsos et al. [1], the eye mechanism will be categorized into two courses.
- bottom-up unconscious consideration
- top-down aware consideration
The primary class is bottom-up unconscious consideration — saliency-based consideration — which is stimulated by exterior components. To exemplify, louder voices will be heard extra simply in contrast with quieter ones. We will produce related ends in deep studying fashions utilizing the max-pooling and gating mechanism, which passes bigger values (i.e. extra salient values) to the subsequent layer (S. Hochreiter et al. [2]). The following sort is top-down aware consideration — centered consideration — that has a predetermined objective and follows particular duties. Due to this fact, utilizing centered consideration, we will focus on a particular object or phenomenon consciously and actively.
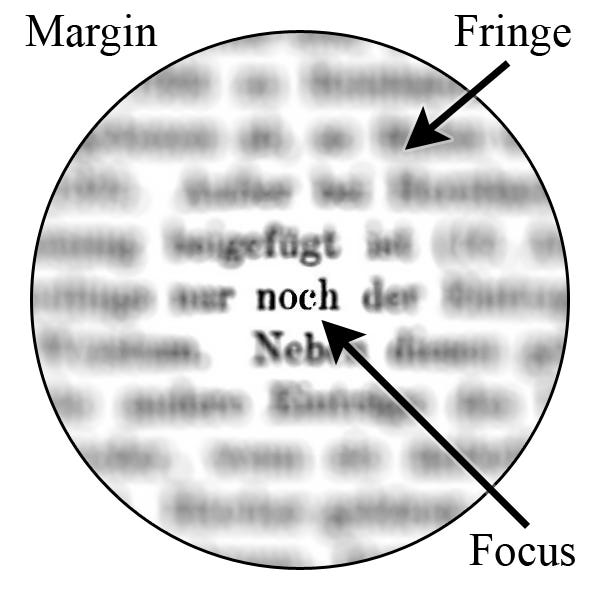
Consideration is the allocation of a cognitive useful resource scheme with restricted processing energy as described by [3]. It’s manifested by the attentional bottleneck, which limits the quantity of data handed to the subsequent steps. Therefore, it could actually drastically improve the efficiency by specializing in extra necessary elements of the knowledge. Because of this, efforts have been made to breed the human mind’s consideration mechanisms and incorporate spatial and temporal consideration in varied duties. As an example, researchers introduced this idea to machine imaginative and prescient by introducing a computational visible saliency mannequin to seize potential salient areas of the photographs[4]. By adaptively deciding on a sequence of areas, V. Mnih et al. proposed a novel recurrent mannequin to extract essentially the most related areas of a picture and solely course of the chosen ones. Fig. 2 illustrates an instance of how visible consideration operates. Bahdanau et al [5]. used consideration mechanisms to permit a mannequin to robotically seek for elements wanted for translating to the goal phrase[5].
Consideration mechanisms have turn into a vital a part of trendy neural community architectures utilized in varied duties, resembling machine translation [Vaswani et al. 2017–16], textual content classification, picture caption era, motion recognition, speech recognition, advice, and graph. Additionally, it has a number of use-cases in real-world functions and achieved splendid success in autonomous driving, medical, human-computer interplay, emotion detection, monetary, meteorology, conduct and motion evaluation, and industries.
Researchers in machine studying have been impressed by the concepts in organic fundamentals of the mind for a very long time and nonetheless, it’s nonetheless not completely clear how the human mind attends to completely different surrounding phenomena, they’ve tried to mathematically mannequin them. To delve into the incorporation of deep studying and a focus mechanisms, I’ll undergo Bahdanau’s consideration [5] structure, which is a machine translation mannequin. Fig. 1 exhibits typical widespread consideration mechanisms.
2.1. RNNSearch
Previous to the mannequin proposed by Bahdanau et al [5]., most architectures for neural machine translation go underneath the umbrella of encoder-decoder fashions. These fashions attempt to encode a supply sentence right into a fixed-length vector, from which the decoder generates a translation into the goal language [see fig. 3]. One essential problem with this strategy is that, when the sentences turn into longer than these within the coaching corpus, it turns into tough for the encoder to deal with. Due to this fact, the authors of this paper got here up with an environment friendly answer to deal with this problem by introducing a brand new technique that collectively learns the translations and alignments. The concept right here is that, through the means of translating a phrase in every step, it (soft-)searches for essentially the most related info positioned in numerous positions within the supply sentence. It then generates translations for the supply phrase wrt. the context vector of those related positions and beforehand generated phrases collectively.
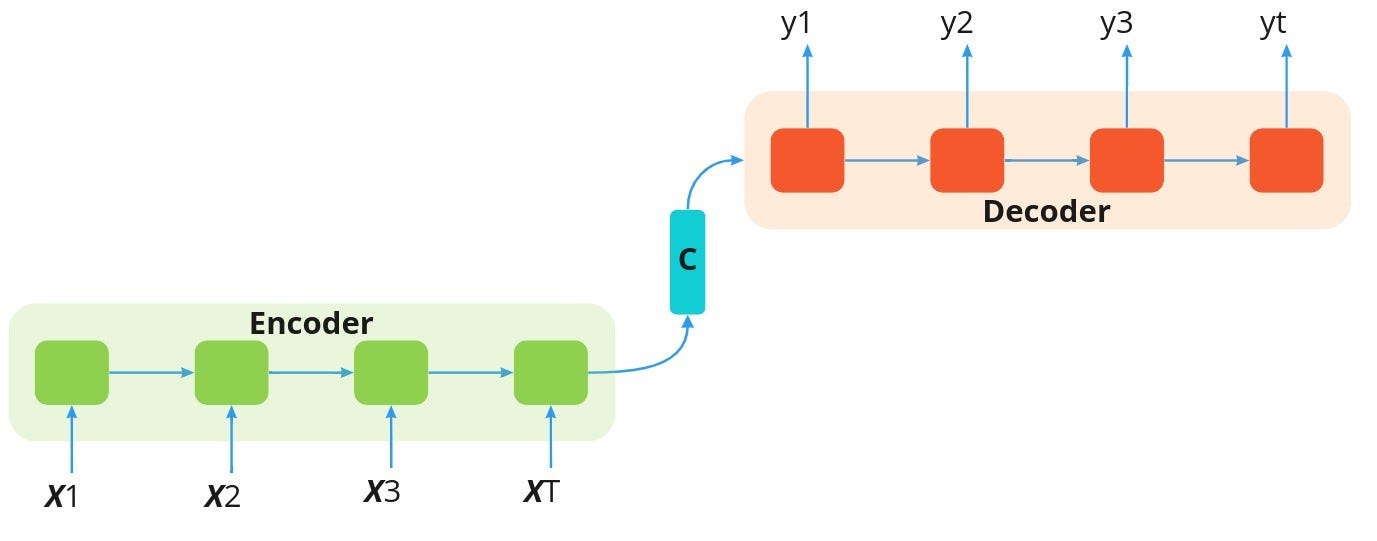
RNNSearch includes a bidirectional recurrent neural community (BiRNN) as its encoder and a decoder to mimic the looking out from the supply sentence when decoding a translation (see fig. 4).
The inputs (from X_1 to X_T) are fed into the ahead RNN to provide the ahead hidden states.
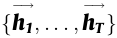
and the backward RNN reads the inputs within the reverse order (from X_T to X_1), leading to backward hidden states.
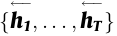
The mannequin generates an annotation for X_i by concatenating the ahead and backward hidden states, leading to h_i.
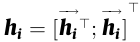
One other recurrent neural community (RNN) and an consideration block make up the decoder. The eye block computes the context vector c, which represents the connection between the present output and the complete inputs. The context vector c_t is then computed as a weighted sum of the hidden states h_j at every time step:
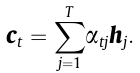
α_tj is the eye weight for every h_j annotation that’s computed as follows:
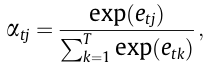
and e_tj is,
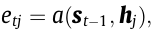
the place a is an alignment mannequin which represents how properly the annotation h_j is well-suited for the subsequent hidden state s_t contemplating earlier state s_t-1.
the place s_i is calculated as:

The mannequin then generates essentially the most possible output y_t on the present step:
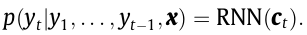
Intuitively, through the use of this formulation, the mannequin can selectively concentrate on necessary elements of the enter sequence at every time step and distribute the supply sentence all through the complete sequence as a substitute of a fixed-length vector.
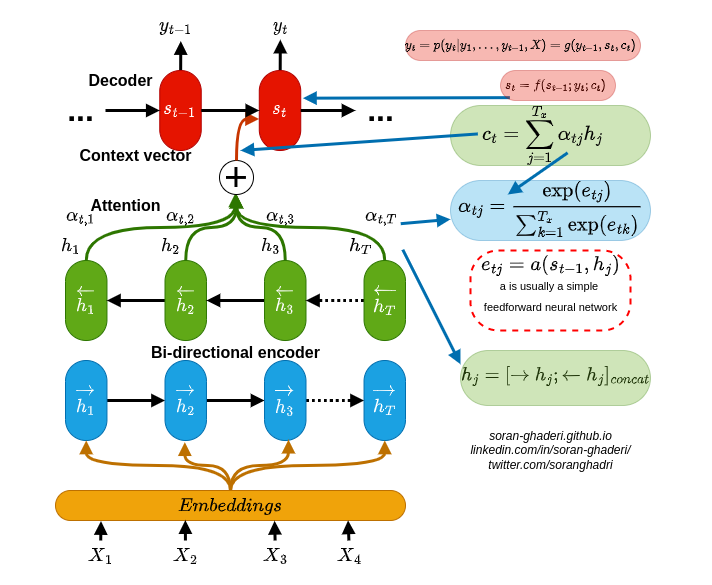
Fig. 4. illustrates the eye mechanism and integrates the underlying arithmetic with the mannequin visualization.
2.2 What precisely are keys, queries, and values in consideration mechanisms?
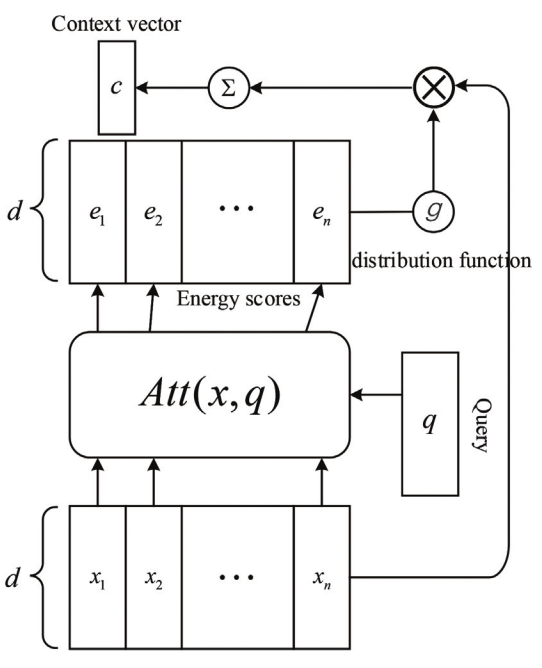
Subsequent to the Bahdanau mannequin adoption in machine translation, varied consideration mechanisms had been devised by researchers. Usually talking, there are two essential widespread steps amongst them. The primary one is the computation of consideration distribution on the inputs, and the subsequent one is the calculation of the context vector primarily based on this distribution. Within the means of computing the eye distribution.
The eye fashions infer the keys (Ok) from the supply information in step one of computing the eye distributions, which will be in quite a lot of varieties and representations relying on the duty(s). As an example, Ok generally is a textual content or doc embeddings, a portion of a picture options (an space from the picture), or hidden states of sequential fashions (RNN, and so on.). Question, Q, is one other time period used for the vector, matrix [7], or two vectors that you will calculate the eye for, merely put, it’s just like s_t-1 (earlier output hidden state) within the RNNsearch. The objective is to determine the connection (weights) between the Q and all Oks by a scoring perform f (additionally referred to as vitality perform and compatibility perform) to calculate the vitality rating that exhibits the significance of Q with respect to all Oks earlier than producing the subsequent output
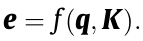
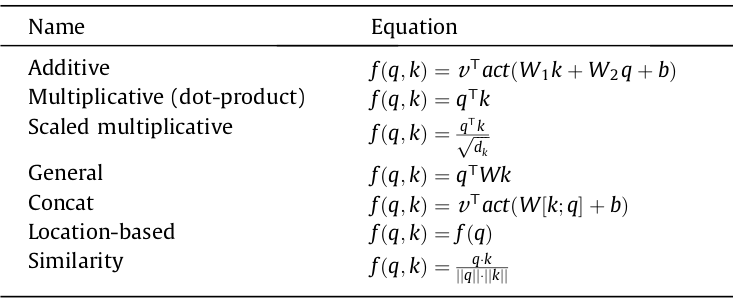
There are a number of scoring features that compute the connection between Qs and Oks. A lot of generally used scoring features are proven in desk 1. Additive consideration [6] and multiplicative consideration (dot-product) [8] are among the many most generally used features.
Within the subsequent step, these vitality scores are fed into an consideration distribution perform named g just like the softmax layer within the RNNsearch to compute the eye weights α by normalizing all vitality scores to a chance distribution
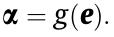
There are drawbacks to the softmax(z) perform, i.e. it produces a outcome for each aspect of z which causes computational overhead in circumstances the place the sparse chance distribution is required. Consequently, researchers proposed a brand new chance distribution perform referred to as sparsemax [9] that is ready to assign zero worth to the irrelevant parts within the output. Moreover, logistic sigmoid [10] was proposed, which scaled vitality scores to the [0–1] vary.
As a substitute of utilizing keys within the illustration of enter information for each context vectors and a focus distributions — which makes the coaching course of troublesome — it’s higher to make use of one other characteristic illustration vector named V and separate these characteristic representations explicitly. To make it extra tangible, in key-value consideration mechanisms, Ok and V are completely different representations of the identical enter information and within the case of self-attention, all Ok, Q, and V are segregated embeddings of the identical information i.e. inputs.
After calculating the eye weights, the context vector is computed as
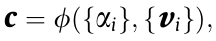
the place the ϕ is often a weighted sum of V and is represented as a single vector:
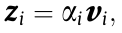
and

the place Z_i is a weighted illustration of V parts and n represents the dimensions of Z.
Merely put, widespread consideration mechanisms ‘‘will be described as mapping a question and a set of key-value pairs to an output, the place the question, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, the place the load assigned to every worth is computed by a compatibility perform of the question with the corresponding key.” as expressed by Vaswani et al. [7].
As for evaluating the eye mechanisms, researchers often embed them inside deep studying fashions and measure their efficiency with and with out consideration to evaluate the eye mechanisms’ impact, i.e. ablation examine. They are often visualized as illustrated in fig. 5, which in flip can be utilized for analysis, though it’s not quantifiable.

To this point, I’ve gone by the mathematical modeling of consideration mechanisms. On this part, I’ll present extra particulars on the taxonomy of those mechanisms. Though the eye mechanisms have the same underlying idea, they fluctuate within the particulars to a excessive diploma to give you the issue in making use of them to completely different duties. A number of taxonomies have been proposed to date, that are principally related. Right here, I’ll use the fashions proposed by Niu et al. 2021 [6] and Chaudhari et al. 2021 [11].

Notice that spotlight mechanisms in numerous standards are usually not mutually unique and so they more than likely embrace completely different mixtures of standards.
3.1. The softness of consideration
The softness of consideration will be divided into 4 varieties:
- Gentle: makes use of a weighted common of all keys to construct the context vector.
- Laborious: context vector is computed from stochastically sampled keys.
- Native: mushy consideration in a window round a place.
- International: just like mushy consideration.
In mushy consideration — first proposed by Bahdanau et al. [5] — the eye module is differentiable with respect to the inputs, thus, the entire mannequin is trainable by customary back-propagation strategies.
However, the onerous consideration — first proposed by Xu et al. 2015 [12] — computes context vector from stochastically sampled keys. Correspondingly, the α in Eq. 8 is calculated as:

On account of stochastic sampling, onerous consideration is computationally inexpensive in contrast with mushy consideration which tries to compute all consideration weights at every step. Clearly, making a tough resolution on enter options has its personal setbacks resembling non-differentiability which makes it troublesome to optimize. Due to this fact the entire mannequin must be optimized through maximizing an approximate variational decrease certain or reinforcing.
Subsequently, Luong et al. 2015 [13] proposed native and international consideration for machine translation. As beforehand acknowledged, international consideration and mushy consideration are related mechanisms; nevertheless, native consideration will be seen as a mix of onerous and mushy consideration, by which I imply it makes use of a subset of the enter options as a substitute of the entire vector. This strategy, in comparison with mushy or international consideration, reduces the computational complexity and, not like onerous consideration, it’s differentiable which makes it simple to implement and optimize.
3.2. Types of enter characteristic
Within the former one, enter illustration is a sequence of specific objects or equivalently an encoding from the inputs. To exemplify, Bahdanau et al. [5] use a single phrase embedding in RNNsearch and a single characteristic map is utilized in SENet. The eye mannequin encodes these things as a separate code and calculates their respective weights through the decoding course of. When mixed with the mushy/onerous consideration mechanisms, within the case of item-wise mushy consideration, it calculates a weight for every merchandise, after which combines them linearly; whereas in onerous consideration, it stochastically selects a number of objects primarily based on their chances.
The latter tries to take care of enter options which are troublesome to pin down discrete definitions of things specifically visible options. Usually talking, they’re often utilized in visible duties; the decoder processes the multi-resolution crop of the inputs at every step, and in some works, it transforms the task-related area right into a canonical, meant pose to pave the best way for simpler inference all through the complete mannequin. In combining location-wise and mushy consideration, a complete characteristic map is fed into the mannequin and a reworked output is produced. Once we mix it with onerous consideration, the very best possible sub-regions WRT. the eye module are chosen stochastically.

3.3. Enter illustration
Consideration mechanisms have a number of types of enter representations, amongst which a quantity are extra widespread, resembling distinctive consideration offered by Chaudhari et al. 2019 [11] which:
- Features a single enter and corresponding output sequence
- The keys and queries belong to 2 impartial sequences
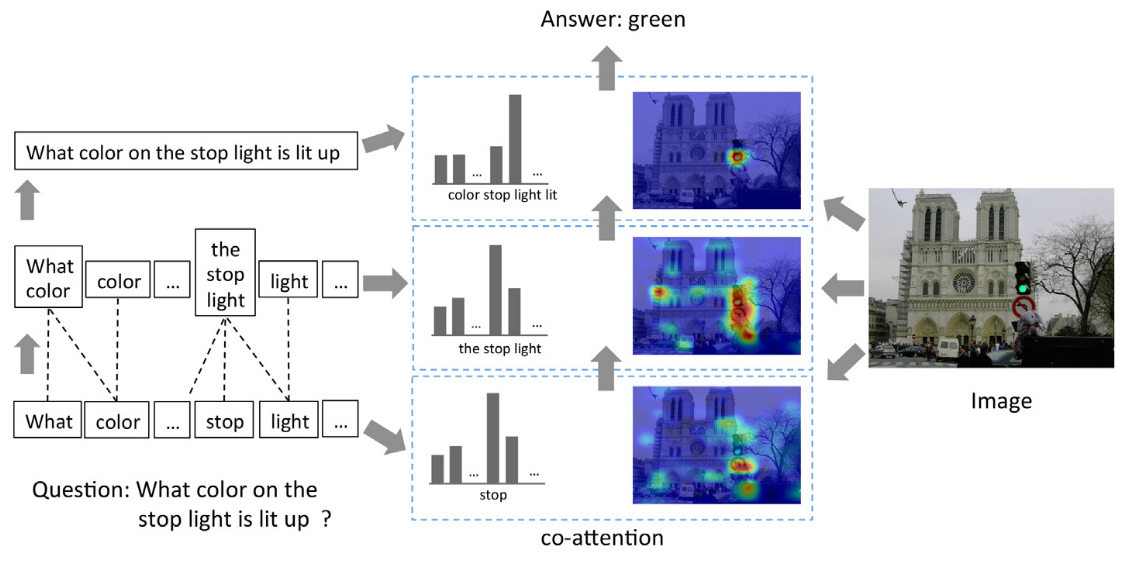
and co-attention, in addition to hierarchical consideration fashions, that settle for multi-inputs resembling within the visible query answering activity offered by Lu et al. 2016 [14]. There are two methods for co-attention to be carried out: a) Parallel: concurrently produces visible and query consideration; b) Various: sequentially alternates between the 2 attentions.
Fan et al. 2018 [15] proposed fine-grained and coarse-grained consideration fashions. They used the embeddings of the opposite enter because the question for every enter to compute the eye weights. However, the fine-grained mannequin calculates the impact of every aspect of the enter on the weather of the opposite enter.
There are a number of profitable use circumstances wherein they’ve deployed co-attention resembling sentiment classification, textual content matching, named entity recognition, entity disambiguation, emotion trigger evaluation, and sentiment classification.
Self (interior) consideration is one other mannequin which solely makes use of inputs for calculating consideration weights proposed by Wang et al. [16]. Key, Question, and worth are representations of the identical enter sequence in numerous areas; self-attention effectivity has been reproduced by a number of researchers in numerous manners, amongst which, Transformer [7] is broadly acclaimed, the primary sequence transduction mannequin which solely used self-attention with out RNNs.
To increase the eye to different ranges of inputs’ embeddings, Yang et al. [17] proposed a hierarchical consideration mannequin (HAM) for doc classification. It makes use of two completely different ranges of consideration: word-level which permits HAM to combination related phrases right into a sentence and sentence-level which allows it to combination key sentences into paperwork. Researchers even prolonged it to increased (consumer) ranges; employed it on the doc stage. On the opposite excessive, a top-down strategy was offered by Zhao and Zhang [18]. Some works have additionally introduced hierarchical consideration to pc imaginative and prescient, wherein they used it for object-level and part-level consideration. This was additionally the primary picture classification technique that didn’t use further info to calculate consideration weights.
3.4. Output illustration
One other criterion for categorization of the eye fashions is the best way they signify the outputs. Single-output consideration is a well known technique that outputs one and just one vector as its vitality scores in every time step. Though the one output is a standard technique utilized in varied conditions, some downstream duties require a extra complete context to be accomplished. Due to this fact, different strategies resembling multi-head and multi-dimensional consideration — which go underneath the umbrella of multi-output consideration fashions — proposed by researchers. By the best way of instance, it has been proven that in pc imaginative and prescient duties in addition to some sequence-based fashions, the one output consideration might not appropriately signify the contexts of the inputs. Vaswani et al. [7] in Transformer, projected enter vectors (Ok, Q, V) into a number of subspaces linearly, adopted by scaled dot-product after which concatenating them utilizing multi-head consideration, as proven in Fig. 7, which permits the mannequin to concurrently calculate the eye weights primarily based on a number of illustration subspaces at completely different positions.
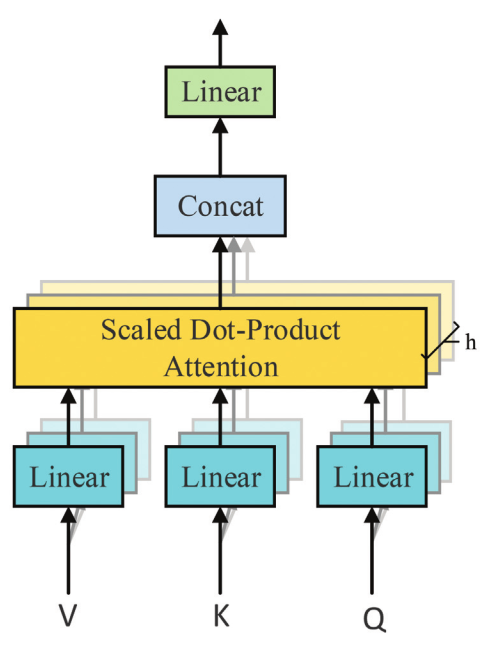
To additional reinforce the multi-head consideration weights range, disagreement regularizations had been added to the subspace, the attended positions, and the output illustration; due to this fact, completely different heads had been extra more likely to signify options in a extra distinct manner.
Subsequent, multi-dimensional consideration was devised to calculate the feature-wise rating vector for Ok through the use of a matrix slightly than the load scores vector. It permits the mannequin to deduce a number of consideration distributions from the identical information. It could possibly assist with a distinguished problem named polysemy within the realm of pure language understanding, the place representations lack the power to signify the coexistence of a number of meanings for a similar phrase or phrase.
Just like the earlier, researchers added penalties (i.e. Frobenius penalties) to encourage the mannequin to be taught extra distinct options from the inputs and proved its effectiveness by making use of it to a number of duties resembling creator profiling, sentiment classification, textual entailment, and distantly supervised relation extraction.
Nonetheless, the eye mechanisms have been broadly adopted in a number of analysis instructions, there nonetheless exists nice potential and leeway to maneuver. A number of the challenges researchers dealing with are talked about under:
- As proven by Zhu et al. [20] and Tay et al. [21], combining Ok (keys) and Q (queries) has resulted in excellent performances. Due to this fact it stays a query of whether or not it’s useful to mix keys, queries, and values in self-attention.
- A lot of current research by Tsai et al. [22] and Katharopoulos et al. [23] present that the efficiency of the eye fashions will be considerably improved by decreasing the complicity of consideration perform because it drastically impacts their computational complexity.
- Making use of the eye fashions devised for particular duties resembling NLP to different fields, like pc imaginative and prescient, can also be a promising orientation. By the best way of instance, when self-attention is utilized to pc imaginative and prescient, it improves efficiency whereas negatively affecting effectivity as demonstrated by Wang et al. [24].
- Engaged on combining the adaptive mechanism and a focus mechanism might result in resembling the hierarchical consideration outcomes with none specific architectural design.
- Devising new methods of evaluating the fashions can also be of nice significance. Sen et al. [25] have proposed a number of analysis strategies to quantitatively measure the similarities between consideration within the human mind and neural networks utilizing novel attention-map similarity metrics.
- Reminiscence modeling is changing into a pattern in deep studying analysis. Frequent fashions principally endure from the shortage of specific reminiscence, therefore, consideration to reminiscence will be studied additional. Neural turning machines paper [26] is an instance of those hybrid fashions and has the potential to be explored extra meticulously.
4.1 Collaboration
In case you are concerned with researching the subjects talked about on my private web site, I welcome additional discussions. please drop me a message! Let’s join on LinkedIn and Twitter.
Comply with this Medium web page and take a look at my GitHub to remain in tune with future content material. In the meantime, have enjoyable!
On this article, I primarily mentioned the eye fashions from varied elements resembling a quick overview of consideration and the human mind; its use-cases in deep studying; the underlying arithmetic; offered a unified mannequin for the eye mechanisms (derived from Niu et al. [6]); their taxonomy primarily based on a variety of standards outlined a number of frontiers to be explored.
For sure, consideration mechanisms have been a major milestone in the midst of the trail towards synthetic intelligence. They’ve revolutionized machine translation, textual content classification, picture caption era, motion recognition, speech recognition, pc imaginative and prescient, and advice. Because of this, they’ve achieved nice success in real-world functions resembling autonomous driving, drugs, human-computer interplay, emotion recognition, and plenty of extra.
[1] J.Ok. Tsotsos, S.M. Culhane, W.Y.Ok. Wai, Y. Lai, N. Davis, F. Nuflo, Modeling
visible consideration through selective tuning, Artif. Intell. 78 (1995) 507–545.
[2] S. Hochreiter, J. Schmidhuber, Lengthy short-term reminiscence, Neural Comput. 9 (1997) 1735–1780.
[3] J. R. Anderson, 2005, Cognitive Psychology and Its Implications, Value Publishers, 2005.
[4] Lu, S., Lim, JH. (2012). Saliency Modeling from Picture Histograms. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds) Laptop Imaginative and prescient — ECCV 2012. ECCV 2012. Lecture Notes in Laptop Science, vol 7578. Springer, Berlin, Heidelberg.
[5] D. Bahdanau, Ok. Cho, Y. Bengio, Neural machine translation by collectively studying to align and translate, in: ICLR.
[6] Z. Niu, G. Zhong, H. Yu, A overview on the eye mechanism of deep studying, Neurocomputing, Quantity 452, 2021, pp. 78–88.
[7] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, Consideration is all you want, in: NIPS, pp. 5998–6008.
[8] D. Britz, A. Goldie, M. Luong, Q.V. Le, Large exploration of neural machine translation architectures, CoRR abs/1703.03906 (2017).
[9] A.F.T. Martins, R.F. Astudillo, From softmax to sparsemax: A sparse mannequin of consideration and multi-label classification, in: ICML, Quantity 48 of JMLR Workshop and Convention Proceedings, JMLR.org, 2016, pp. 1614–1623
[10] Y. Kim, C. Denton, L. Hoang, A.M. Rush, Structured consideration networks, arXiv: Computation and Language (2017)
[11] S. Chaudhari, V. Mithal, G. Polatkan, R. Ramanath, An Attentive Survey of Consideration Fashions, ACM Transactions on Clever Programs and TechnologyVolume, 2021 Article No.: 53, pp 1–32.
[12] Ok. Xu, J. Ba, R. Kiros, Ok. Cho, A.C. Courville, R. Salakhutdinov, R.S. Zemel, Y. Bengio, Present, attend and inform: neural picture caption era with visible consideration, in: ICML, Quantity 37 of JMLR Workshop and Convention Proceedings, JMLR.org, 2015, pp. 2048–2057.
[13] T. Luong, H. Pham, C.D. Manning, Efficient approaches to attention-based neural machine translation, in: EMNLP, The Affiliation for Computational Linguistics, 2015, pp. 1412–1421.
[14] J. Lu, J. Yang, D. Batra, D. Parikh, Hierarchical question-image co-attention for visible query answering, in: NIPS, pp. 289–297.
[15] F. Fan, Y. Feng, D. Zhao, Multi-grained consideration community for aspect-level
sentiment classification, in: EMNLP, Affiliation for Computational Linguistics, 2018, pp. 3433–3442.
[16] B. Wang, Ok. Liu, J. Zhao, Internal attention-based recurrent neural networks for reply choice, in: ACL (1), The Affiliation for Laptop Linguistics, 2016.
[17] Z. Yang, D. Yang, C. Dyer, X. He, A.J. Smola, E.H. Hovy, Hierarchical consideration networks for doc classification, in: HLT-NAACL, The Affiliation for Computational Linguistics, 2016, pp. 1480–1489.
[18] S. Zhao, Z. Zhang, Consideration-via-attention neural machine translation, in:AAAI, AAAI Press, 2018, pp. 563–570.
[19] J. Du, J. Han, A. Method, D. Wan, Multi-level structured self-attentions for
distantly supervised relation extraction, in: EMNLP, Affiliation for
Computational Linguistics, 2018, pp. 2216–2225.
[20] X. Zhu, D. Cheng, Z. Zhang, S. Lin, J. Dai, An empirical examine of spatial consideration mechanisms in deep networks, in: 2019 IEEE/CVF Worldwide Convention on Laptop Imaginative and prescient, ICCV 2019, Seoul, Korea (South), October 27–November 2, 2019, IEEE, 2019, pp. 6687–6696.
[21] Y. Tay, D. Bahri, D. Metzler, D. Juan, Z. Zhao, C. Zheng, Synthesizer: rethinking self-attention in transformer fashions, CoRR abs/2005.00743 (2020).
[22] Y.H. Tsai, S. Bai, M. Yamada, L. Morency, R. Salakhutdinov, Transformer dissection: An unified understanding for transformer’s consideration through the lens of the kernel, in: Ok. Inui, J. Jiang, V. Ng, X. Wan (Eds.), Proceedings of the 2019 Convention on Empirical Strategies in Pure Language Processing and the ninth Worldwide Joint Convention on Pure Language Processing, EMNLP- IJCNLP 2019, Hong Kong, China, November 3–7, 2019, Affiliation for Computational Linguistics, 2019, pp. 4343–4352.
[23] A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret, Transformers are rnns: Quick autoregressive transformers with linear consideration, CoRR abs/2006.16236
(2020).
[24] X. Wang, R. B. Girshick, A. Gupta, Ok. He, Non-local neural networks, in: CVPR, IEEE Laptop Society, 2018, pp. 7794–7803.
[25] C. Sen, T. Hartvigsen, B. Yin, X. Kong, E.A. Rundensteiner, Human consideration maps for textual content classification: Do people and neural networks concentrate on the identical phrases?, in: D. Jurafsky, J. Chai, N. Schluter, J.R. Tetreault (Eds.), Proceedings of the 58th Annual Assembly of the Affiliation for Computational
Linguistics, ACL 2020, On-line, July 5–10, 2020, Affiliation for Computational Linguistics, 2020, pp. 4596–4608.
[26] A. Graves, G. Wayne, I. Danihelka, Neural Turing Machines, arXiv preprint: Arxiv-1410.5401.
[27] Z. Lin, M. Feng, C.N. dos Santos, M. Yu, B. Xiang, B. Zhou, Y. Bengio, A
structured self-attentive sentence embedding, in: ICLR (Poster), OpenReview.
internet, 2017.

{kind=link}