This submit discusses main current advances in NLP specializing in neural network-based strategies.
This submit initially appeared on the AYLIEN weblog.
That is the primary weblog submit in a two-part collection. The collection expands on the Frontiers of Pure Language Processing session organized by Herman Kamper and me on the Deep Studying Indaba 2018. Slides of your entire session may be discovered right here. This submit discusses main current advances in NLP specializing in neural network-based strategies. The second submit discusses open issues in NLP. You could find a recording of the speak this submit is predicated on right here.
Disclaimer This submit tries to condense ~15 years’ value of labor into eight milestones which can be essentially the most related right now and thus omits many related and necessary developments. Particularly, it’s closely skewed in direction of present neural approaches, which can give the misunderstanding that no different strategies have been influential throughout this era. Extra importantly, most of the neural community fashions offered on this submit construct on non-neural milestones of the identical period. Within the closing part of this submit, we spotlight such influential work that laid the foundations for later strategies.
Desk of contents:
Language modelling is the duty of predicting the subsequent phrase in a textual content given the earlier phrases. It’s in all probability the only language processing activity with concrete sensible functions akin to clever keyboards, e-mail response suggestion (Kannan et al., 2016), spelling autocorrection, and so forth. Unsurprisingly, language modelling has a wealthy historical past. Traditional approaches are primarily based on n-grams and make use of smoothing to cope with unseen n-grams (Kneser & Ney, 1995).
The primary neural language mannequin, a feed-forward neural community was proposed in 2001 by Bengio et al., proven in Determine 1 under.
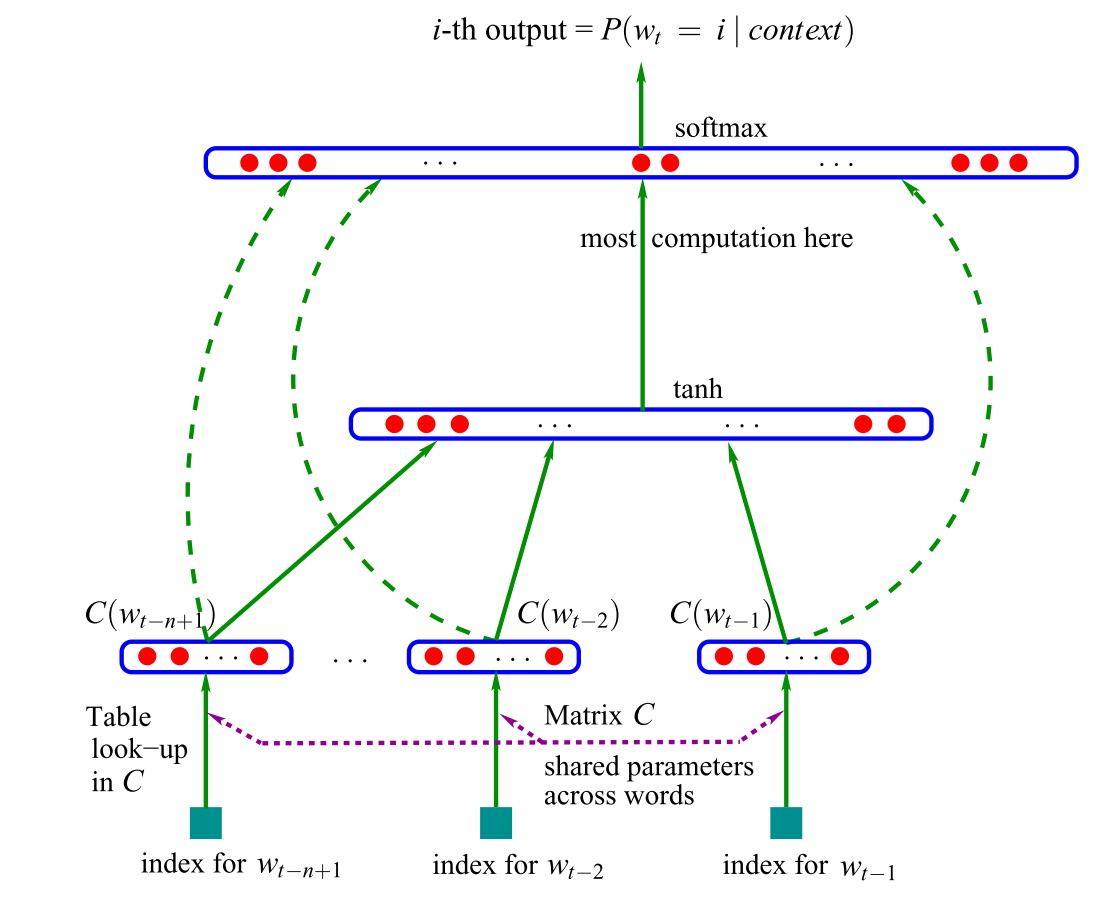
This mannequin takes as enter vector representations of the (n) earlier phrases, that are regarded up in a desk (C). These days, such vectors are generally known as phrase embeddings. These phrase embeddings are concatenated and fed right into a hidden layer, whose output is then offered to a softmax layer. For extra details about the mannequin, take a look at this submit.
Extra just lately, feed-forward neural networks have been changed with recurrent neural networks (RNNs; Mikolov et al., 2010) and lengthy short-term reminiscence networks (LSTMs; Graves, 2013) for language modelling. Many new language fashions that stretch the basic LSTM have been proposed lately (take a look at this web page for an outline). Regardless of these developments, the basic LSTM stays a powerful baseline (Melis et al., 2018). Even Bengio et al.’s basic feed-forward neural community is in some settings aggressive with extra subtle fashions as these usually solely be taught to think about the latest phrases (Daniluk et al., 2017). Understanding higher what data such language fashions seize consequently is an energetic analysis space (Kuncoro et al., 2018; Blevins et al., 2018).
Language modelling is often the coaching floor of alternative when making use of RNNs and has succeeded at capturing the creativeness, with many getting their first publicity through Andrej’s weblog submit. Language modelling is a type of unsupervised studying, which Yann LeCun additionally calls predictive studying and cites as a prerequisite to buying widespread sense (see right here for his Cake slide from NIPS 2016). In all probability essentially the most outstanding side about language modelling is that regardless of its simplicity, it’s core to most of the later advances mentioned on this submit:
- Phrase embeddings: The target of word2vec is a simplification of language modelling.
- Sequence-to-sequence fashions: Such fashions generate an output sequence by predicting one phrase at a time.
- Pretrained language fashions: These strategies use representations from language fashions for switch studying.
This conversely implies that lots of crucial current advances in NLP cut back to a type of language modelling. With a purpose to do “actual” pure language understanding, simply studying from the uncooked type of textual content possible won’t be sufficient and we’ll want new strategies and fashions.
Multi-task studying is a normal technique for sharing parameters between fashions which can be skilled on a number of duties. In neural networks, this may be achieved simply by tying the weights of various layers. The concept of multi-task studying was first proposed in 1993 by Wealthy Caruana and was utilized to road-following and pneumonia prediction (Caruana, 1998). Intuitively, multi-task studying encourages the fashions to be taught representations which can be helpful for a lot of duties. That is notably helpful for studying normal, low-level representations, to focus a mannequin’s consideration or in settings with restricted quantities of coaching information. For a extra complete overview of multi-task studying, take a look at this submit.
Multi-task studying was first utilized to neural networks for NLP in 2008 by Collobert and Weston. Of their mannequin, the look-up tables (or phrase embedding matrices) are shared between two fashions skilled on completely different duties, as depicted in Determine 2 under.
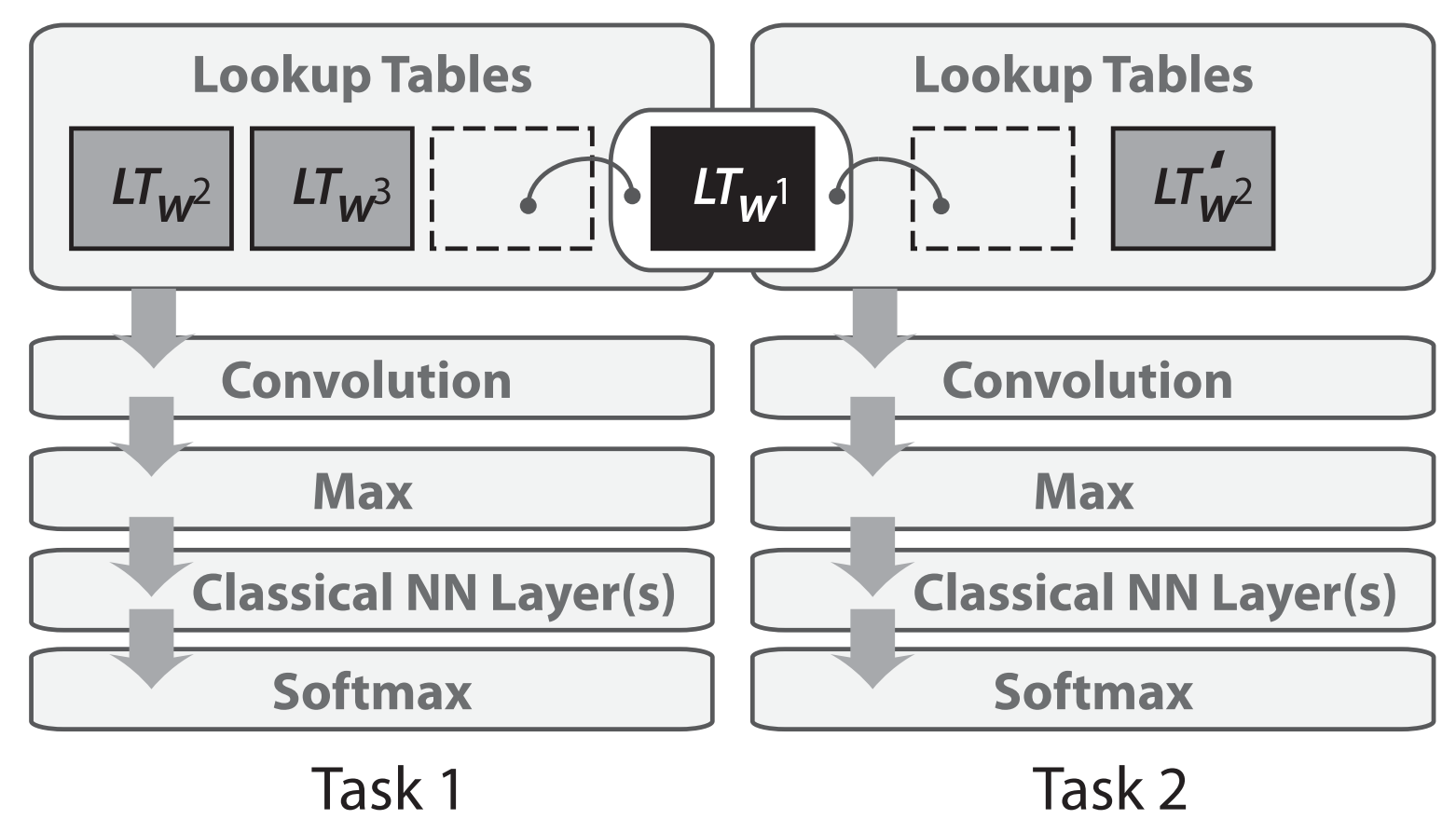
Sharing the phrase embeddings permits the fashions to collaborate and share normal low-level data within the phrase embedding matrix, which generally makes up the biggest variety of parameters in a mannequin. The 2008 paper by Collobert and Weston proved influential past its use of multi-task studying. It spearheaded concepts akin to pretraining phrase embeddings and utilizing convolutional neural networks (CNNs) for textual content which have solely been extensively adopted within the final years. It gained the test-of-time award at ICML 2018 (see the test-of-time award speak contextualizing the paper right here).
Multi-task studying is now used throughout a variety of NLP duties and leveraging present or “synthetic” duties has turn out to be a useful gizmo within the NLP repertoire. For an outline of various auxiliary duties, take a look at this submit. Whereas the sharing of parameters is often predefined, completely different sharing patterns can be realized throughout the optimization course of (Ruder et al., 2017). As fashions are being more and more evaluated on a number of duties to gauge their generalization capacity, multi-task studying is gaining in significance and devoted benchmarks for multi-task studying have been proposed just lately (Wang et al., 2018; McCann et al., 2018).
Sparse vector representations of textual content, the so-called bag-of-words mannequin have an extended historical past in NLP. Dense vector representations of phrases or phrase embeddings have been used as early as 2001 as we’ve seen above. The principle innovation that was proposed in 2013 by Mikolov et al. was to make the coaching of those phrase embeddings extra environment friendly by eradicating the hidden layer and approximating the target. Whereas these adjustments have been easy in nature, they enabled—together with the environment friendly word2vec implementation—large-scale coaching of phrase embeddings.
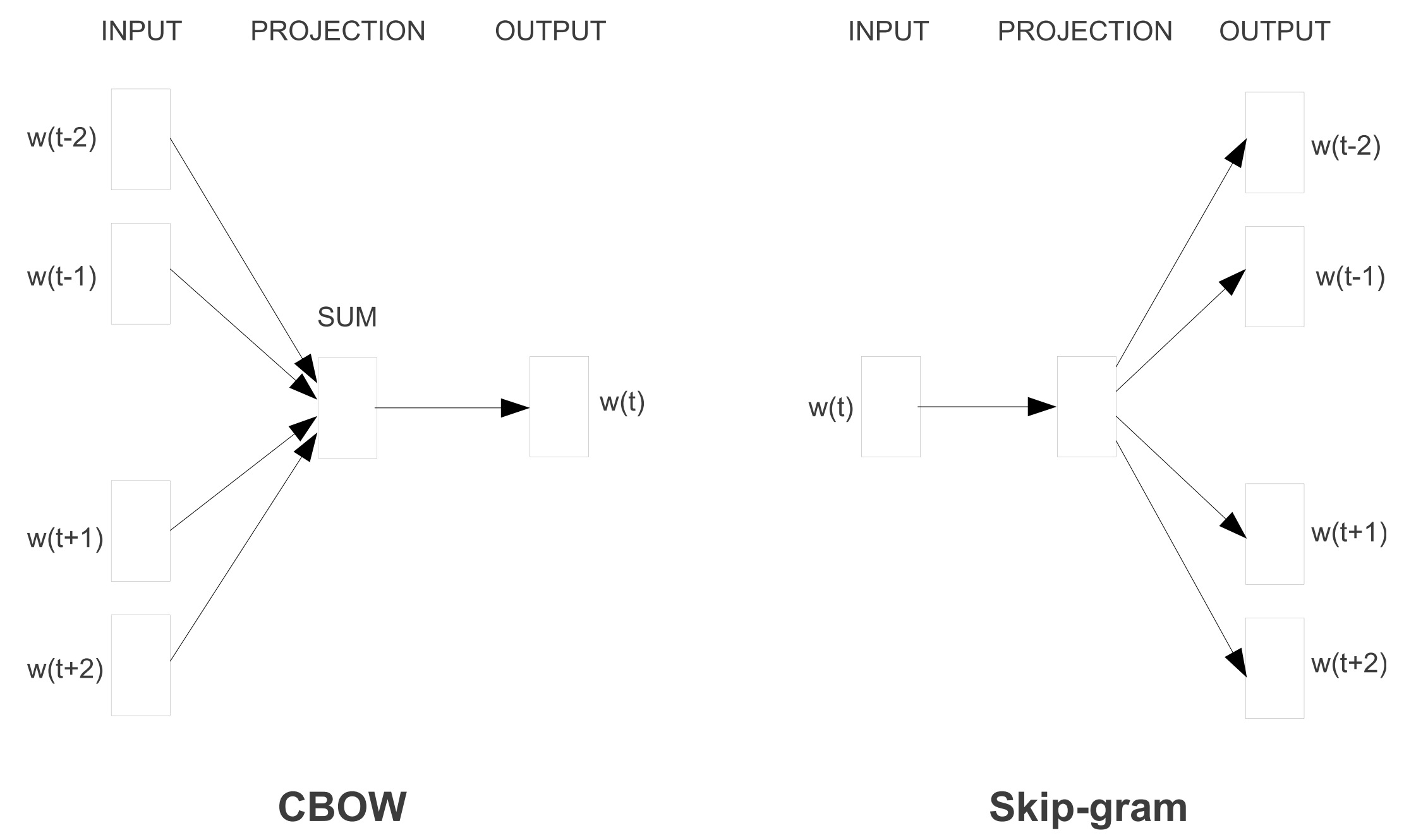
Word2vec is available in two flavours that may be seen in Determine 3 under: steady bag-of-words (CBOW) and skip-gram. They differ of their goal: one predicts the centre phrase primarily based primarily based on the encompassing phrases, whereas the opposite does the alternative.
Whereas these embeddings aren’t any completely different conceptually than those realized with a feed-forward neural community, coaching on a really massive corpus permits them to approximate sure relations between phrases akin to gender, verb tense, and country-capital relations, which may be seen in Determine 4 under.
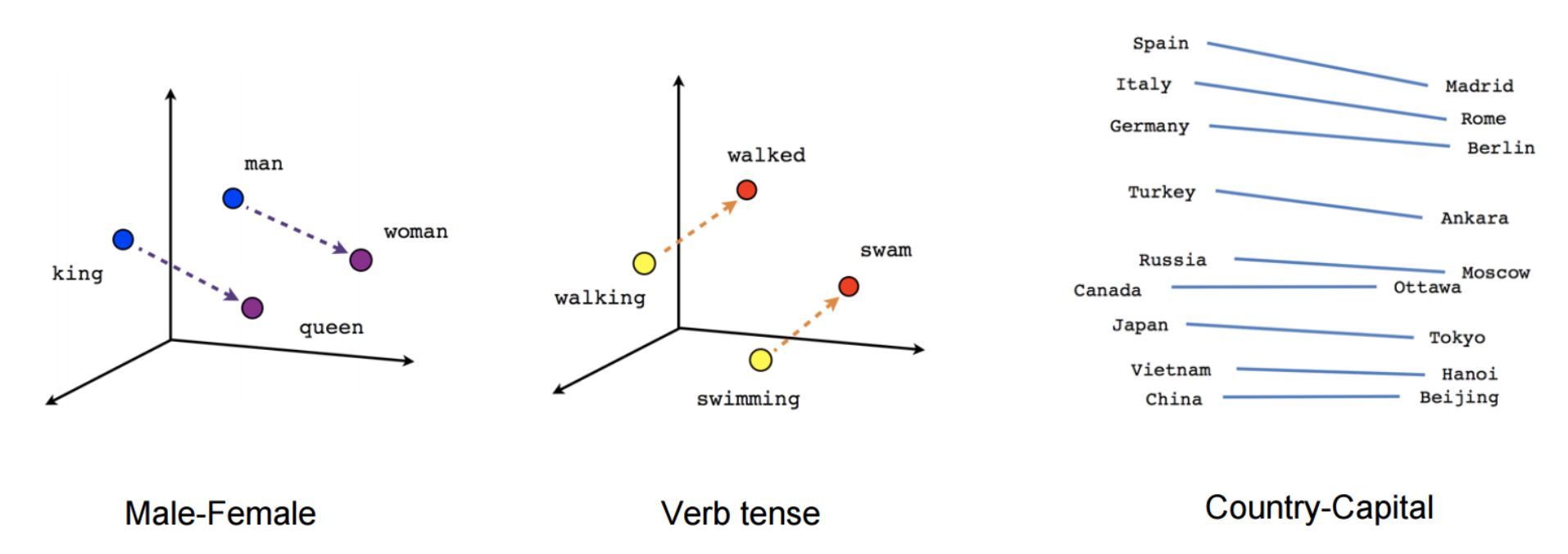
These relations and the that means behind them sparked preliminary curiosity in phrase embeddings and plenty of research have investigated the origin of those linear relationships (Arora et al., 2016; Mimno & Thompson, 2017; Antoniak & Mimno, 2018; Wendlandt et al., 2018). Nonetheless, later research confirmed that the realized relations aren’t with out bias (Bolukbasi et al., 2016). What cemented phrase embeddings as a mainstay in present NLP was that utilizing pretrained embeddings as initialization was proven to enhance efficiency throughout a variety of downstream duties.
Whereas the relations word2vec captured had an intuitive and virtually magical high quality to them, later research confirmed that there’s nothing inherently particular about word2vec: Phrase embeddings can be realized through matrix factorization (Pennington et al, 2014; Levy & Goldberg, 2014) and with correct tuning, basic matrix factorization approaches like SVD and LSA obtain related outcomes (Levy et al., 2015).
Since then, numerous work has gone into exploring completely different aspects of phrase embeddings (as indicated by the staggering variety of citations of the unique paper). Take a look at this submit for some developments and future instructions. Regardless of many developments, word2vec remains to be a preferred alternative and extensively used right now. Word2vec’s attain has even prolonged past the phrase degree: skip-gram with adverse sampling, a handy goal for studying embeddings primarily based on native context, has been utilized to be taught representations for sentences (Mikolov & Le, 2014; Kiros et al., 2015)—and even going past NLP—to networks (Grover & Leskovec, 2016) and organic sequences (Asgari & Mofrad, 2015), amongst others.
One notably thrilling route is to venture phrase embeddings of various languages into the identical area to allow (zero-shot) cross-lingual switch. It’s turning into more and more potential to be taught a great projection in a very unsupervised means (at the least for related languages) (Conneau et al., 2018; Artetxe et al., 2018; Søgaard et al., 2018), which opens functions for low-resource languages and unsupervised machine translation (Lample et al., 2018; Artetxe et al., 2018). Take a look at (Ruder et al., 2018) for an outline.
2013 and 2014 marked the time when neural community fashions began to get adopted in NLP. Three primary kinds of neural networks grew to become essentially the most extensively used: recurrent neural networks, convolutional neural networks, and recursive neural networks.
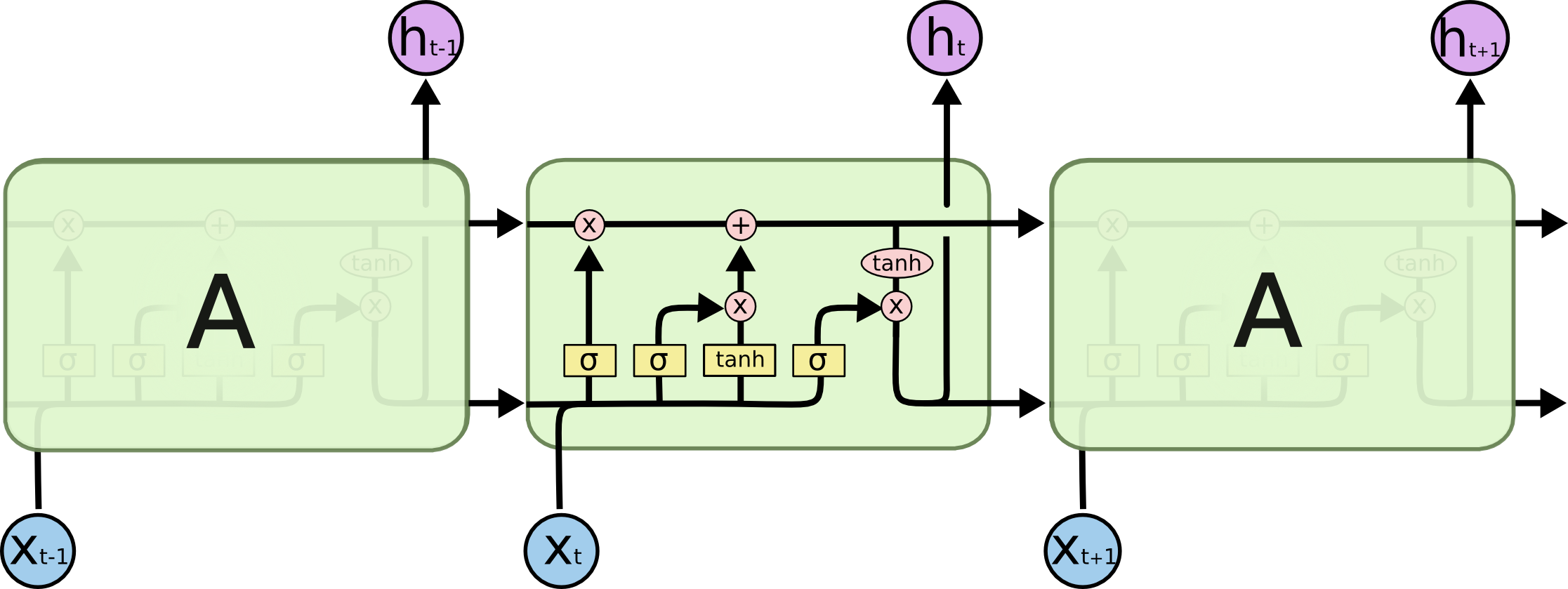
Recurrent neural networks Recurrent neural networks (RNNs) are an apparent option to cope with the dynamic enter sequences ubiquitous in NLP. Vanilla RNNs (Elman, 1990) have been shortly changed with the basic lengthy short-term reminiscence networks (Hochreiter & Schmidhuber, 1997), which proved extra resilient to the vanishing and exploding gradient drawback. Earlier than 2013, RNNs have been nonetheless considered tough to coach; Ilya Sutskever’s PhD thesis was a key instance on the best way to altering this popularity. A visualization of an LSTM cell may be seen in Determine 5 under. A bidirectional LSTM (Graves et al., 2013) is often used to cope with each left and proper context.
Convolutional neural networks With convolutional neural networks (CNNs) being extensively utilized in laptop imaginative and prescient, additionally they began to get utilized to language (Kalchbrenner et al., 2014; Kim et al., 2014). A convolutional neural community for textual content solely operates in two dimensions, with the filters solely needing to be moved alongside the temporal dimension. Determine 6 under reveals a typical CNN as utilized in NLP.
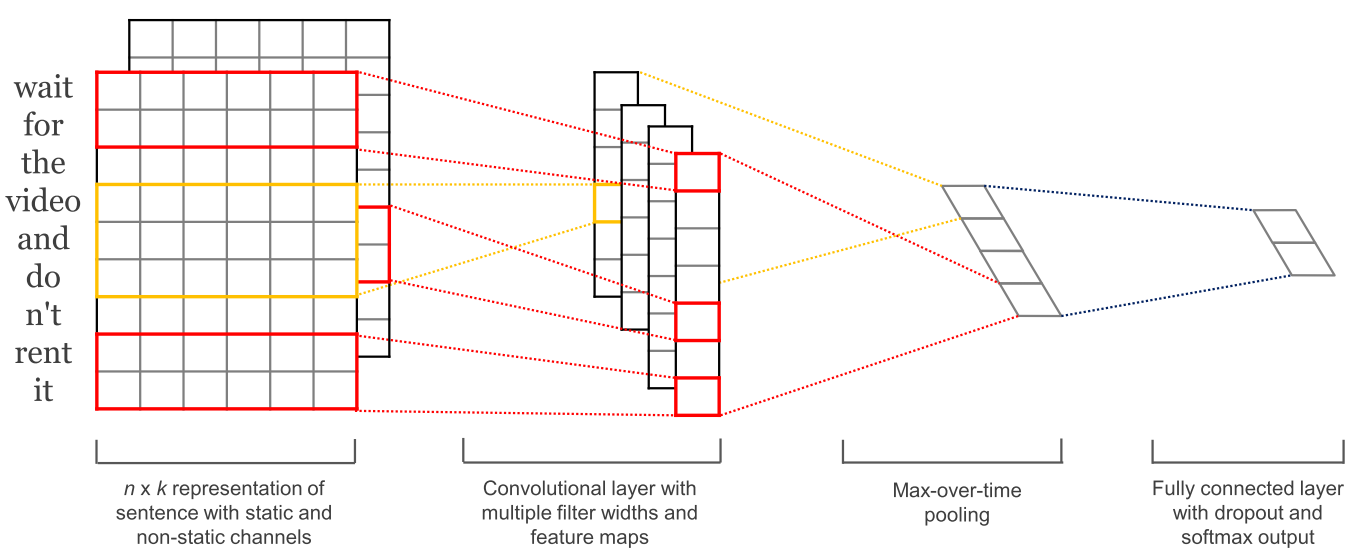
A bonus of convolutional neural networks is that they’re extra parallelizable than RNNs, because the state at each timestep solely depends upon the native context (through the convolution operation) moderately than all previous states as within the RNN. CNNs may be prolonged with wider receptive fields utilizing dilated convolutions to seize a wider context (Kalchbrenner et al., 2016). CNNs and LSTMs can be mixed and stacked (Wang et al., 2016) and convolutions can be utilized to hurry up an LSTM (Bradbury et al., 2017).
Recursive neural networks RNNs and CNNs each deal with the language as a sequence. From a linguistic perspective, nevertheless, language is inherently hierarchical: Phrases are composed into higher-order phrases and clauses, which might themselves be recursively mixed in response to a set of manufacturing guidelines. The linguistically impressed thought of treating sentences as bushes moderately than as a sequence provides rise to recursive neural networks (Socher et al., 2013), which may be seen in Determine 7 under.
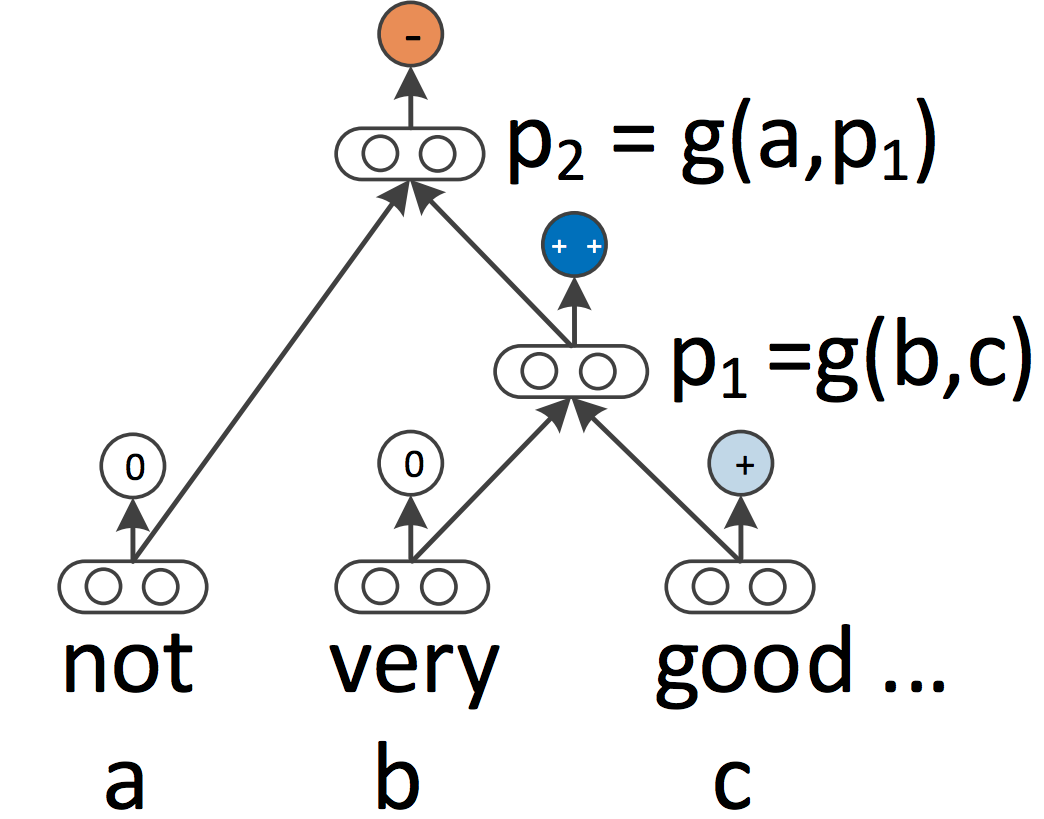
Recursive neural networks construct the illustration of a sequence from the underside up in distinction to RNNs who course of the sentence left-to-right or right-to-left. At each node of the tree, a brand new illustration is computed by composing the representations of the kid nodes. As a tree can be seen as imposing a unique processing order on an RNN, LSTMs have naturally been prolonged to bushes (Tai et al., 2015).
Not solely RNNs and LSTMs may be prolonged to work with hierarchical buildings. Phrase embeddings may be realized primarily based not solely on native however on grammatical context (Levy & Goldberg, 2014); language fashions can generate phrases primarily based on a syntactic stack (Dyer et al., 2016); and graph-convolutional neural networks can function over a tree (Bastings et al., 2017).
In 2014, Sutskever et al. proposed sequence-to-sequence studying, a normal framework for mapping one sequence to a different one utilizing a neural community. Within the framework, an encoder neural community processes a sentence image by image and compresses it right into a vector illustration; a decoder neural community then predicts the output image by image primarily based on the encoder state, taking as enter at each step the beforehand predicted image as may be seen in Determine 8 under.
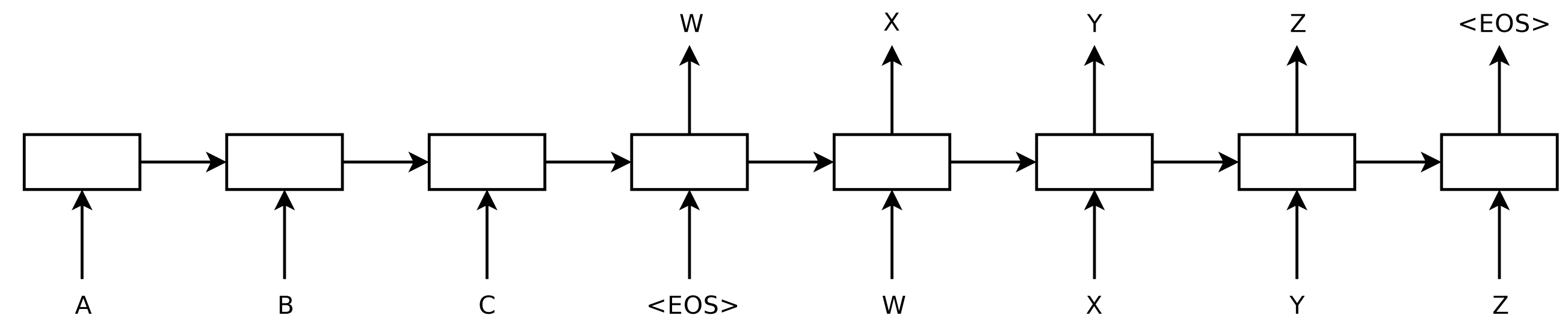
Machine translation turned out to be the killer utility of this framework. In 2016, Google introduced that it was beginning to substitute its monolithic phrase-based MT fashions with neural MT fashions (Wu et al., 2016). In keeping with Jeff Dean, this meant changing 500,000 traces of phrase-based MT code with a 500-line neural community mannequin.
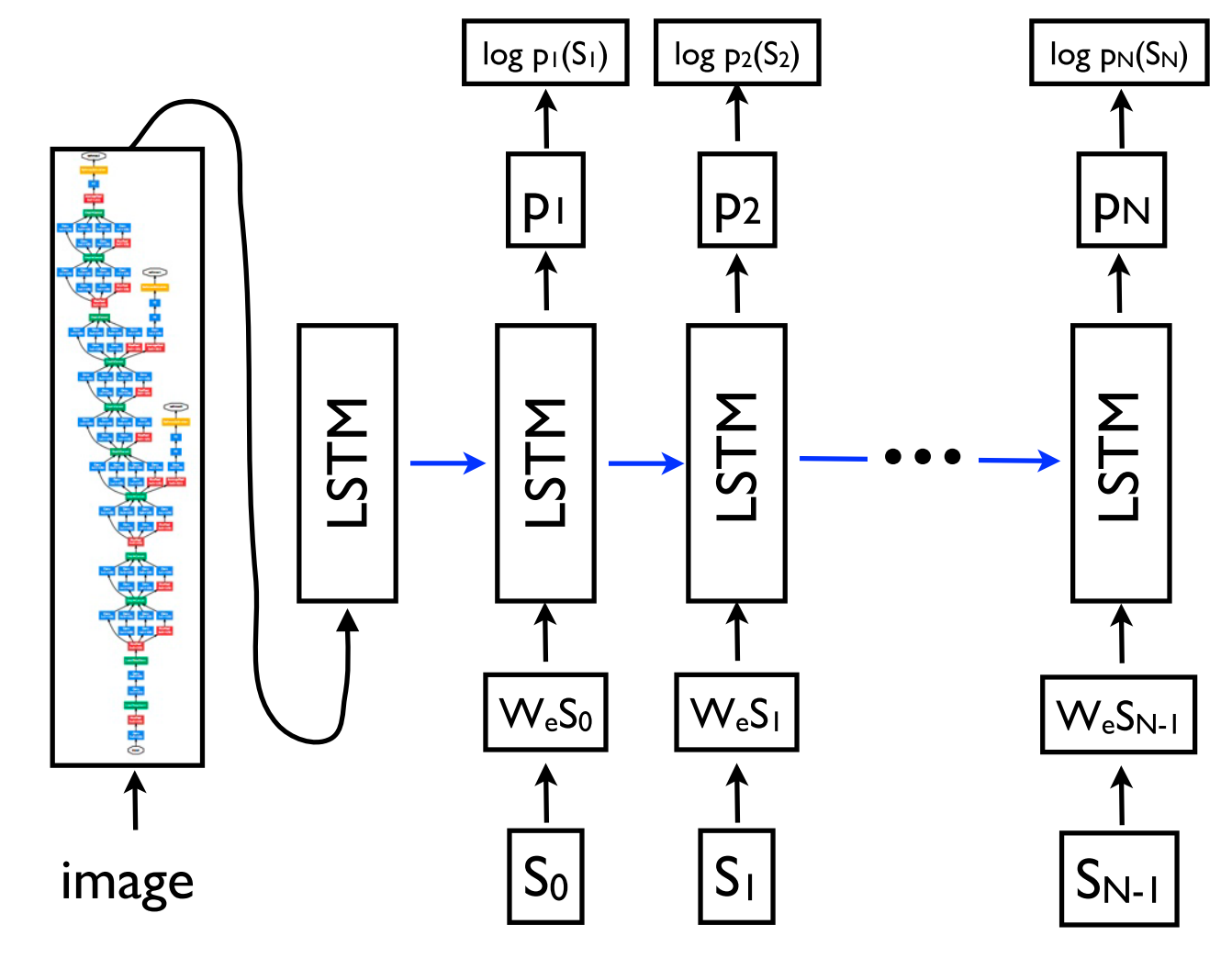
This framework as a result of its flexibility is now the go-to framework for pure language era duties, with completely different fashions taking up the function of the encoder and the decoder. Importantly, the decoder mannequin cannot solely be conditioned on a sequence, however on arbitrary representations. This allows as an example producing a caption primarily based on a picture (Vinyals et al., 2015) (as may be seen in Determine 9 under), textual content primarily based on a desk (Lebret et al., 2016), and an outline primarily based on supply code adjustments (Loyola et al., 2017), amongst many different functions.
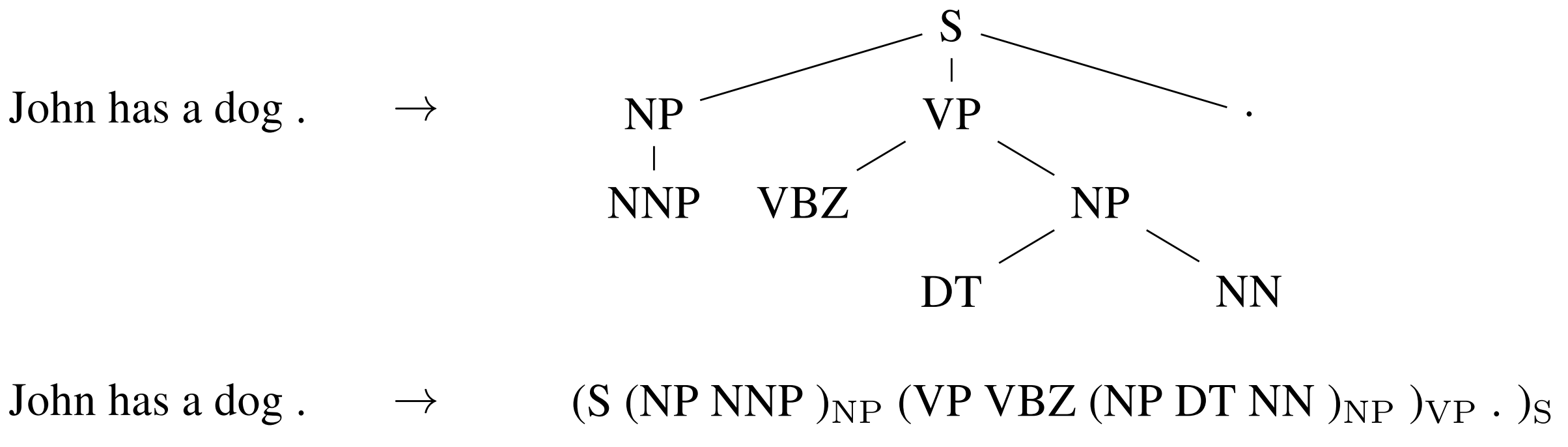
Sequence-to-sequence studying may even be utilized to structured prediction duties widespread in NLP the place the output has a specific construction. For simplicity, the output is linearized as may be seen for constituency parsing in Determine 10 under. Neural networks have demonstrated the flexibility to straight be taught to provide such a linearized output given adequate quantity of coaching information for constituency parsing (Vinyals et al, 2015), and named entity recognition (Gillick et al., 2016), amongst others.
Encoders for sequences and decoders are usually primarily based on RNNs however different mannequin sorts can be utilized. New architectures primarily emerge from work in MT, which acts as a Petri dish for sequence-to-sequence architectures. Current fashions are deep LSTMs (Wu et al., 2016), convolutional encoders (Kalchbrenner et al., 2016; Gehring et al., 2017), the Transformer (Vaswani et al., 2017), which might be mentioned within the subsequent part, and a mix of an LSTM and a Transformer (Chen et al., 2018).
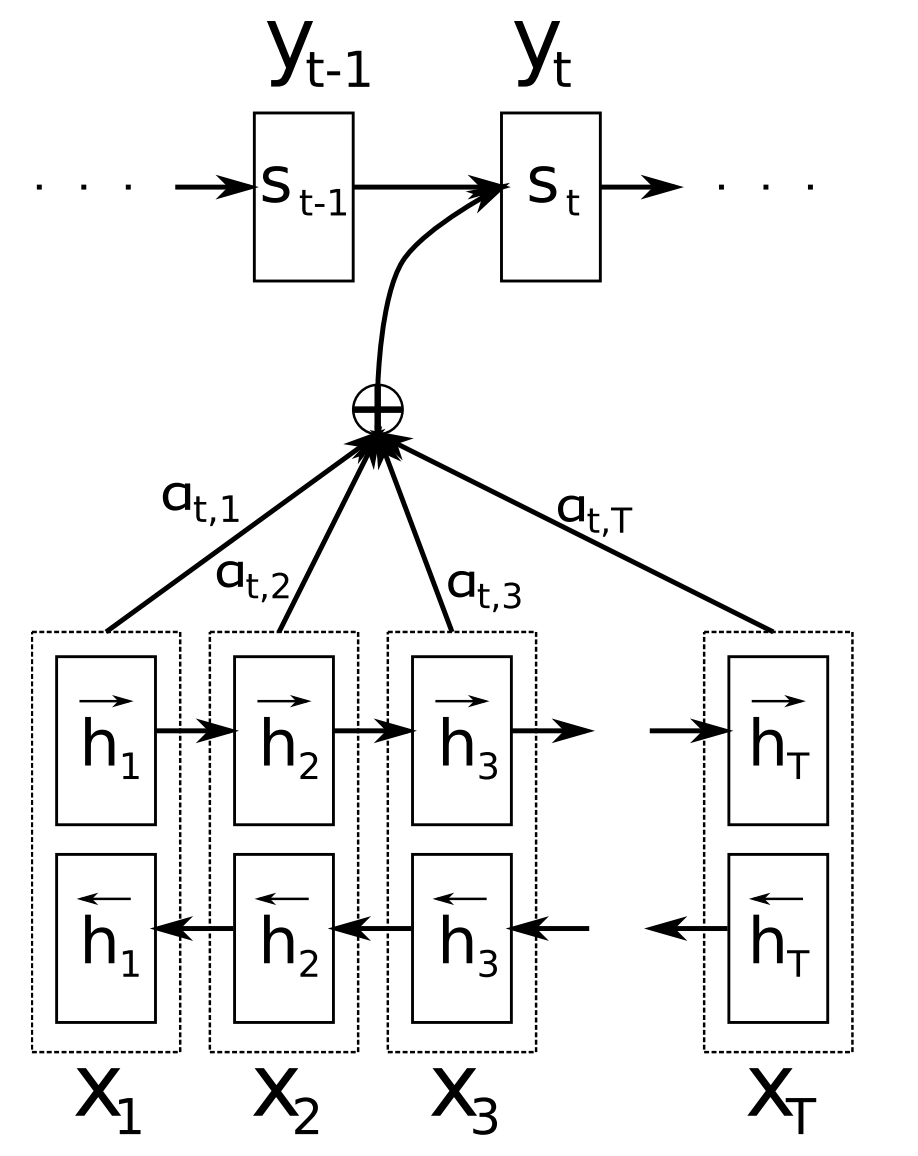
Consideration (Bahdanau et al., 2015) is without doubt one of the core improvements in neural MT (NMT) and the important thing concept that enabled NMT fashions to outperform basic phrase-based MT techniques. The principle bottleneck of sequence-to-sequence studying is that it requires to compress your entire content material of the supply sequence right into a fixed-size vector. Consideration alleviates this by permitting the decoder to look again on the supply sequence hidden states, that are then offered as a weighted common as extra enter to the decoder as may be seen in Determine 11 under.
Completely different types of consideration can be found (Luong et al., 2015). Take a look right here for a quick overview. Consideration is extensively relevant and probably helpful for any activity that requires making choices primarily based on sure elements of the enter. It has been utilized to consituency parsing (Vinyals et al., 2015), studying comprehension (Hermann et al., 2015), and one-shot studying (Vinyals et al., 2016), amongst many others. The enter doesn’t even must be a sequence, however can encompass different representations as within the case of picture captioning (Xu et al., 2015), which may be seen in Determine 12 under. A helpful side-effect of consideration is that it supplies a rare—if solely superficial—glimpse into the inside workings of the mannequin by inspecting which elements of the enter are related for a specific output primarily based on the eye weights.

Consideration can also be not restricted to simply trying on the enter sequence; self-attention can be utilized to have a look at the encompassing phrases in a sentence or doc to acquire extra contextually delicate phrase representations. A number of layers of self-attention are on the core of the Transformer structure (Vaswani et al., 2017), the present state-of-the-art mannequin for NMT.
Consideration may be seen as a type of fuzzy reminiscence the place the reminiscence consists of the previous hidden states of the mannequin, with the mannequin selecting what to retrieve from reminiscence. For a extra detailed overview of consideration and its connection to reminiscence, take a look at this submit. Many fashions with a extra specific reminiscence have been proposed. They arrive in numerous variants akin to Neural Turing Machines (Graves et al., 2014), Reminiscence Networks (Weston et al., 2015) and Finish-to-end Reminiscence Networks (Sukhbaatar et al., 2015), Dynamic Reminiscence Networks (Kumar et al., 2015), the Neural Differentiable Pc (Graves et al., 2016), and the Recurrent Entity Community (Henaff et al., 2017).
Reminiscence is usually accessed primarily based on similarity to the present state much like consideration and may usually be written to and browse from. Fashions differ in how they implement and leverage the reminiscence. For example, Finish-to-end Reminiscence Networks course of the enter a number of instances and replace the reminiscence to allow a number of steps of inference. Neural Turing Machines even have a location-based addressing, which permits them to be taught easy laptop packages like sorting. Reminiscence-based fashions are usually utilized to duties, the place retaining data over longer time spans needs to be helpful akin to language modelling and studying comprehension. The idea of a reminiscence may be very versatile: A data base or desk can perform as a reminiscence, whereas a reminiscence can be populated primarily based on your entire enter or specific elements of it.
Pretrained phrase embeddings are context-agnostic and solely used to initialize the primary layer in our fashions. In current months, a spread of supervised duties has been used to pretrain neural networks (Conneau et al., 2017; McCann et al., 2017; Subramanian et al., 2018). In distinction, language fashions solely require unlabelled textual content; coaching can thus scale to billions of tokens, new domains, and new languages. Pretrained language fashions have been first proposed in 2015 (Dai & Le, 2015); solely just lately have been they proven to be helpful throughout a various vary of duties. Language mannequin embeddings can be utilized as options in a goal mannequin (Peters et al., 2018) or a language mannequin may be fine-tuned heading in the right direction activity information (Ramachandran et al., 2017; Howard & Ruder, 2018). Including language mannequin embeddings provides a big enchancment over the state-of-the-art throughout many alternative duties as may be seen in Determine 13 under.
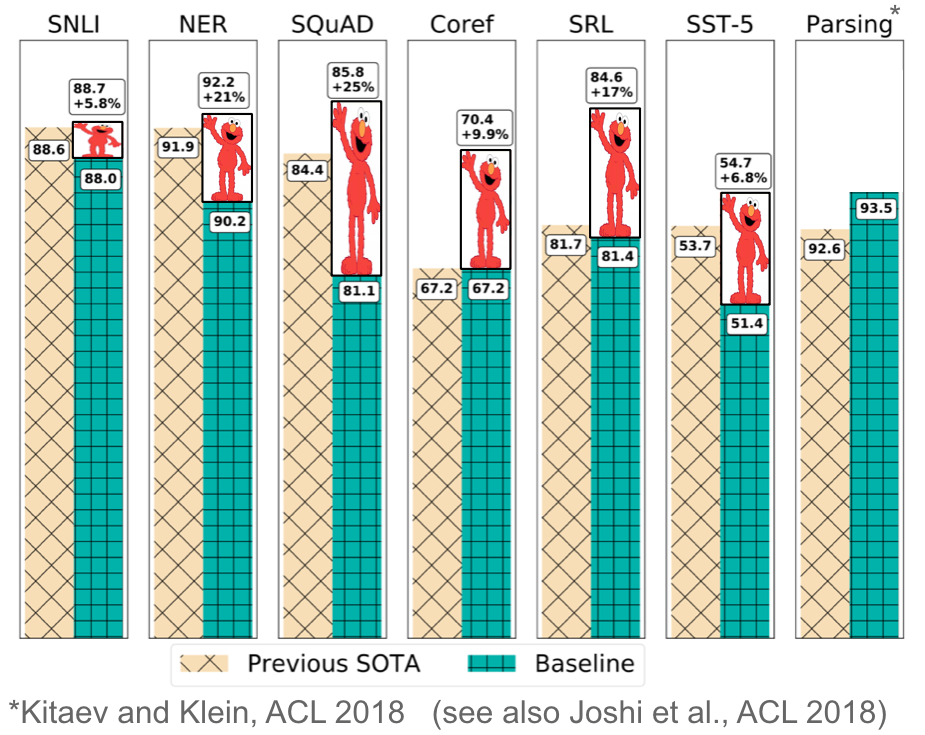
Pretrained language fashions have been proven allow studying with considerably much less information. As language fashions solely require unlabelled information, they’re notably helpful for low-resource languages the place labelled information is scarce. For extra details about the potential of pretrained language fashions, check with this text.
Another developments are much less pervasive than those talked about above, however nonetheless have wide-ranging affect.
Character-based representations Utilizing a CNN or an LSTM over characters to acquire a character-based phrase illustration is now pretty widespread, notably for morphologically wealthy languages and duties the place morphological data is necessary or which have many unknown phrases. Character-based representations have been first used for part-of-speech tagging and language modeling (Ling et al., 2015) and dependency parsing (Ballesteros et al., 2015). They later grew to become a core element of fashions for sequence labeling (Lample et al., 2016; Plank et al., 2016) and language modeling (Kim et al., 2016). Character-based representations alleviate the necessity of getting to cope with a hard and fast vocabulary at elevated computational price and allow functions akin to totally character-based NMT (Ling et al., 2016; Lee et al., 2017).
Adversarial studying Adversarial strategies have taken the sphere of ML by storm and have additionally been utilized in completely different types in NLP. Adversarial examples have gotten more and more extensively used not solely as a instrument to probe fashions and perceive their failure circumstances, but in addition to make them extra sturdy (Jia & Liang, 2017). (Digital) adversarial coaching, that’s, worst-case perturbations (Miyato et al., 2017; Yasunaga et al., 2018) and domain-adversarial losses (Ganin et al., 2016; Kim et al., 2017) are helpful types of regularization that may equally make fashions extra sturdy. Generative adversarial networks (GANs) aren’t but too efficient for pure language era (Semeniuta et al., 2018), however are helpful as an example when matching distributions (Conneau et al., 2018).
Reinforcement studying Reinforcement studying has been proven to be helpful for duties with a temporal dependency akin to choosing information throughout coaching (Fang et al., 2017; Wu et al., 2018) and modelling dialogue (Liu et al., 2018). RL can also be efficient for straight optimizing a non-differentiable finish metric akin to ROUGE or BLEU as a substitute of optimizing a surrogate loss akin to cross-entropy in summarization (Paulus et al, 2018; Celikyilmaz et al., 2018) and machine translation (Ranzato et al., 2016). Equally, inverse reinforcement studying may be helpful in settings the place the reward is simply too complicated to be specified akin to visible storytelling (Wang et al., 2018).
In 1998 and over the next years, the FrameNet venture was launched (Baker et al., 1998), which led to the duty of semantic function labelling, a type of shallow semantic parsing that’s nonetheless actively researched right now. Within the early 2000s, the shared duties organized along with the Convention on Pure Language Studying (CoNLL) catalyzed analysis in core NLP duties akin to chunking (Tjong Kim Sang et al., 2000), named entity recognition (Tjong Kim Sang et al., 2003), and dependency parsing (Buchholz et al., 2006), amongst others. Most of the CoNLL shared activity datasets are nonetheless the usual for analysis right now.
In 2001, conditional random fields (CRF; Lafferty et al., 2001), some of the influential courses of sequence labelling strategies have been launched, which gained the Take a look at-of-time award at ICML 2011. A CRF layer is a core a part of present state-of-the-art fashions for sequence labelling issues with label interdependencies akin to named entity recognition (Lample et al., 2016).
In 2002, the bilingual analysis understudy (BLEU; Papineni et al., 2002) metric was proposed, which enabled MT techniques to scale up and remains to be the usual metric for MT analysis today. In the identical 12 months, the structured preceptron (Collins, 2002) was launched, which laid the inspiration for work in structured notion. On the similar convention, sentiment evaluation, some of the common and extensively studied NLP duties, was launched (Pang et al., 2002). All three papers gained the Take a look at-of-time award at NAACL 2018. As well as, the linguistic useful resource PropBank (Kingsbury & Palmer, 2002) was launched in the identical 12 months. PropBank is much like FrameNet, however focuses on verbs. It’s regularly utilized in semantic function labelling.
2003 noticed the introduction of latent dirichlet allocation (LDA; Blei et al., 2003), some of the extensively used strategies in machine studying, which remains to be the usual option to do subject modelling. In 2004, novel max-margin fashions have been proposed which can be higher suited to capturing correlations in structured information than SVMs (Taskar et al., 2004a; 2004b).
In 2006, OntoNotes (Hovy et al., 2006), a big multilingual corpus with a number of annotations and excessive interannotator settlement was launched. OntoNotes has been used for the coaching and analysis of quite a lot of duties akin to dependency parsing and coreference decision. Milne and Witten (2008) described in 2008 how Wikipedia can be utilized to complement machine studying strategies. To this date, Wikipedia is without doubt one of the most helpful assets for coaching ML strategies, whether or not for entity linking and disambiguation, language modelling, as a data base, or quite a lot of different duties.
In 2009, the thought of distant supervision (Mintz et al., 2009) was proposed. Distant supervision leverages data from heuristics or present data bases to generate noisy patterns that can be utilized to mechanically extract examples from massive corpora. Distant supervision has been used extensively and is a standard method in relation extraction, data extraction, and sentiment evaluation, amongst different duties.
In 2016, Common Dependencies v1 (Nivre et al., 2016), a multilingual assortment of treebanks, was launched. The Common Dependencies venture is an open neighborhood effort that goals to create constant dependency-based annotations throughout many languages. As of January 2019, Common Dependencies v2 contains greater than 100 treebanks in over 70 languages.
Quotation
For attribution in educational contexts or books, please cite this work as:
Sebastian Ruder, "A Evaluation of the Neural Historical past of Pure Language Processing". http://ruder.io/a-review-of-the-recent-history-of-nlp/, 2018.
BibTeX quotation:
@misc{ruder2018reviewneuralhistory,
writer = {Ruder, Sebastian},
title = {{A Evaluation of the Neural Historical past of Pure Language Processing}},
12 months = {2018},
howpublished = {url{http://ruder.io/a-review-of-the-recent-history-of-nlp/}},
}
Translations
Due to Djamé Seddah, Daniel Khashabi, Shyam Upadhyay, Chris Dyer, and Michael Roth for offering pointers (see the Twitter thread).

{kind=link}