
What’s exploratory evaluation, how it’s structured and the best way to apply it in Python with the assistance of Pandas and different information evaluation and visualization libraries

Exploratory information evaluation (EDA) is an particularly vital exercise within the routine of an information analyst or scientist.
It allows an in depth understanding of the dataset, outline or discard hypotheses and create predictive fashions on a strong foundation.
It makes use of information manipulation methods and several other statistical instruments to explain and perceive the connection between variables and the way these can affect enterprise.
In actual fact, it’s because of EDA that we are able to ask ourselves significant questions that may affect enterprise.
On this article, I’ll share with you a template for exploratory evaluation that I’ve used through the years and that has confirmed to be strong for a lot of initiatives and domains. That is applied via using the Pandas library — a vital software for any analyst working with Python.
The method consists of a number of steps:
- Importing a dataset
- Understanding the large image
- Preparation
- Understanding of variables
- Research of the relationships between variables
- Brainstorming
This template is the results of many iterations and permits me to ask myself significant questions concerning the information in entrance of me. On the finish of the method, we will consolidate a enterprise report or proceed with the information modeling part.
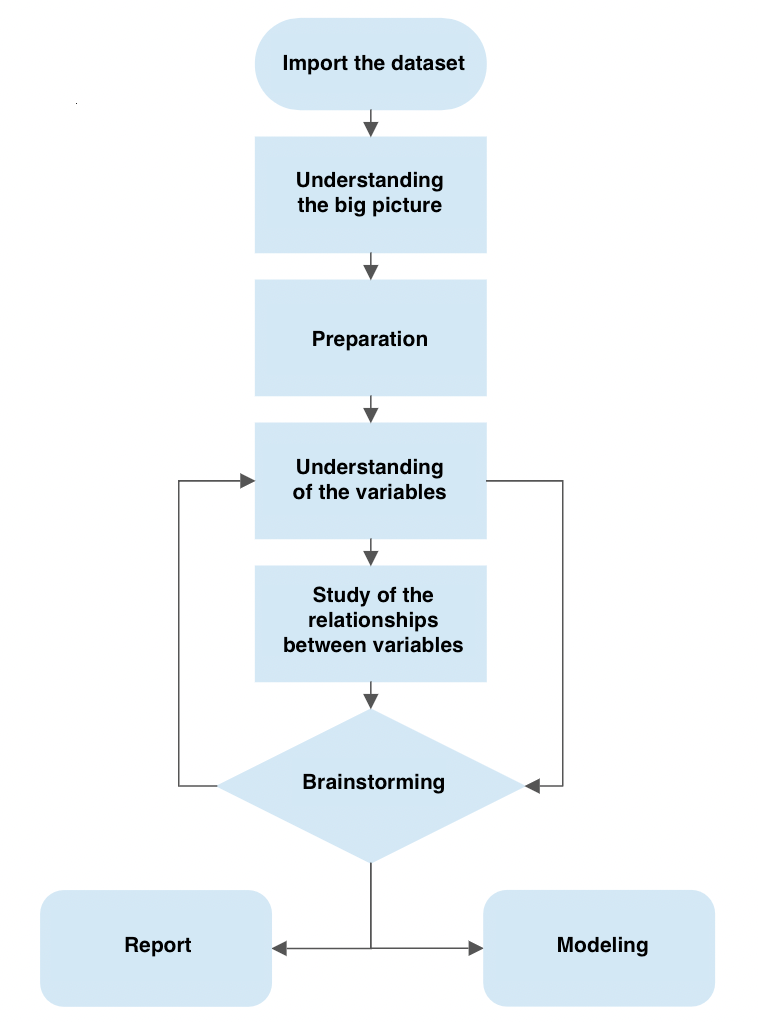
The picture under exhibits how the brainstorming part is linked with that of understanding the variables and the way this in flip is linked once more with the brainstorming part.
This course of describes how we are able to transfer to ask new questions till we’re happy.
We are going to see a few of the commonest and vital options of Pandas and likewise some methods to govern the information with a view to perceive it totally.
I’ve found with time and expertise that numerous corporations are on the lookout for insights and worth that come from essentially descriptive actions.
Which means that corporations are sometimes prepared to allocate sources to amass the mandatory consciousness of the phenomenon that we analysts are going to check.
The data of one thing.
If we’re in a position to examine the information and ask the precise questions, the EDA course of turns into extraordinarily highly effective. By combining information visualization expertise, a talented analyst is ready to construct a profession solely by leveraging these expertise. You don’t even have to enter modeling.
A very good strategy to EDA due to this fact permits us to offer added worth to many enterprise contexts, particularly the place our consumer / boss finds difficulties within the interpretation or entry to information.
That is the essential concept that led me to place down such a template.
I wrote a Twitter thread that places my ideas on the matter on paper
Earlier than beginning, let’s see what are the elemental libraries required to hold out the EDA. There are numerous helpful libraries however right here we are going to solely see those that this template leverages
The information evaluation pipeline begins with the import or creation of a working dataset. The exploratory evaluation part begins instantly after.
Importing a dataset is straightforward with Pandas via capabilities devoted to studying the information. If our dataset is a .csv file, we are able to simply use
df = pd.read_csv("path/to/my/file.csv")
df stands for dataframe, which is Pandas’s object much like an Excel sheet. This nomenclature is usually used within the subject. The read_csv perform takes as enter the trail of the file we need to learn. There are numerous different arguments that we are able to specify.
The .csv format isn’t the one one we are able to import — there are in actual fact many others reminiscent of Excel, Parquet and Feather.
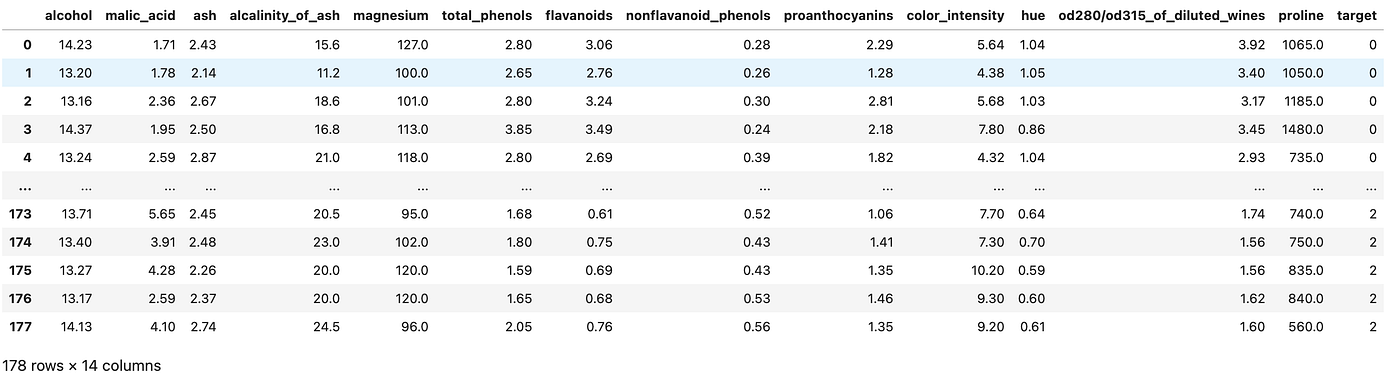
For ease, on this instance we are going to use Sklearn to import the wine dataset. This dataset is broadly used within the business for academic functions and accommodates data on the chemical composition of wines for a classification activity. We won’t use a .csv however a dataset current in Sklearn to create the dataframe
Now that we’ve imported a usable dataset, let’s transfer on to making use of the EDA pipeline.
On this first part, our purpose is to grasp what we’re taking a look at, however with out going into element. We attempt to perceive the issue we need to resolve, fascinated about your complete dataset and the which means of the variables.
This part could be sluggish and typically even boring, however it’ll give us the chance to make an opinion of our dataset.
Let’s take some notes
I often open Excel or create a textual content file in VSCode to place some notes down, on this trend:
- Variable: title of the variable
- Sort: the kind or format of the variable. This may be categorical, numeric, Boolean, and so forth
- Context: helpful data to grasp the semantic area of the variable. Within the case of our dataset, the context is all the time the chemical-physical one, so it’s straightforward. In one other context, for instance that of actual property, a variable might belong to a specific section, such because the anatomy of the fabric or the social one (what number of neighbors are there?)
- Expectation: how related is that this variable with respect to our activity? We will use a scale “Excessive, Medium, Low”.
- Feedback: whether or not or not we’ve got any feedback to make on the variable
Of all these, Expectation is without doubt one of the most vital as a result of it helps us develop the analyst’s “sixth sense” — as we accumulate expertise within the subject we will mentally map which variables are related and which aren’t.
In any case, the purpose of finishing up this exercise is that it allows us to do some preliminary reflections on our information, which helps us to start out the evaluation course of.
Helpful properties and capabilities in Pandas
We are going to leverage a number of Pandas options and properties to grasp the large image. Let’s see a few of them.
.head() and .tail()
Two of probably the most generally used capabilities in Pandas are .head() and .tail(). These two enable us to view an arbitrary variety of rows (by default 5) from the start or finish of the dataset. Very helpful for accessing a small a part of the dataframe rapidly.
.form
If we apply .form on the dataset, Pandas returns us a pair of numbers that symbolize the dimensionality of our dataset. This property could be very helpful for understanding the variety of columns and the size of the dataset.
.describe()
The describe perform does precisely this: it gives purely descriptive details about the dataset. This data consists of statistics that summarize the central tendency of the variable, their dispersion, the presence of empty values and their form.
.information()
In contrast to .describe(), .information() provides us a shorter abstract of our dataset. It returns us details about the information kind, non-null values and reminiscence utilization.
There are additionally .dtypes and .isna() which respectively give us the information kind information and whether or not the worth is null or not. Nevertheless, utilizing .information() permits us to entry this data with a single command.
What’s our purpose?
This is a crucial query that we should all the time ask ourselves. In our case, we see how the goal is a numeric categorical variable that covers the values of 0, 1 and a pair of. These numbers establish the kind of wine.
If we test the Sklearn documentation on this dataset we see that it was constructed exactly for classification duties. If we needed to do modeling, the concept would then be to make use of the options of the wine to foretell its kind. In an information evaluation setting as an alternative, we might need to research how the various kinds of wine have totally different options and the way these are distributed.
At this stage we need to begin cleansing our dataset with a view to proceed the evaluation. A number of the questions we are going to ask ourselves are
- are there any ineffective or redundant variables?
- are there any duplicate columns?
- does the nomenclature make sense?
- are there any new variables we need to create?
Let’s see the best way to apply these concepts to our dataset.
- All of the variables look like physical-chemical measures. This implies they might all be helpful and assist outline the segmentation of the kind of wine. We’ve got no cause to take away columns
- To test for duplicate rows we are able to use
.isduplicated().sum()— this can print us the variety of duplicated rows in our dataset
- The nomenclature can definitely be optimized. For instance od280 / od315_of_diluted_wines is obscure. Because it signifies a analysis methodology that measures protein focus within the liquid, we are going to name it protein_concentration
- One of the vital frequent characteristic engineering strategies is to create new options which are the linear / polynomial mixture of the present ones. This turns into helpful for offering extra data to a predictive mannequin to enhance its efficiency. We won’t do that in our case although.
Being a toy dataset, it’s virtually already ready for us. Nevertheless, these factors are nonetheless helpful to course of extra complicated datasets.
Whereas within the earlier level we’re describing the dataset in its entirety, now we attempt to precisely describe all of the variables that curiosity us. Because of this, this step will also be known as univariate evaluation.
Categorical variables
On this context, .value_counts() is without doubt one of the most vital capabilities to grasp what number of values of a given variable there are in our dataset. Let’s take the goal variable for instance.
It’s also possible to categorical the information as a proportion by passing normalize = True
We will additionally plot the information with
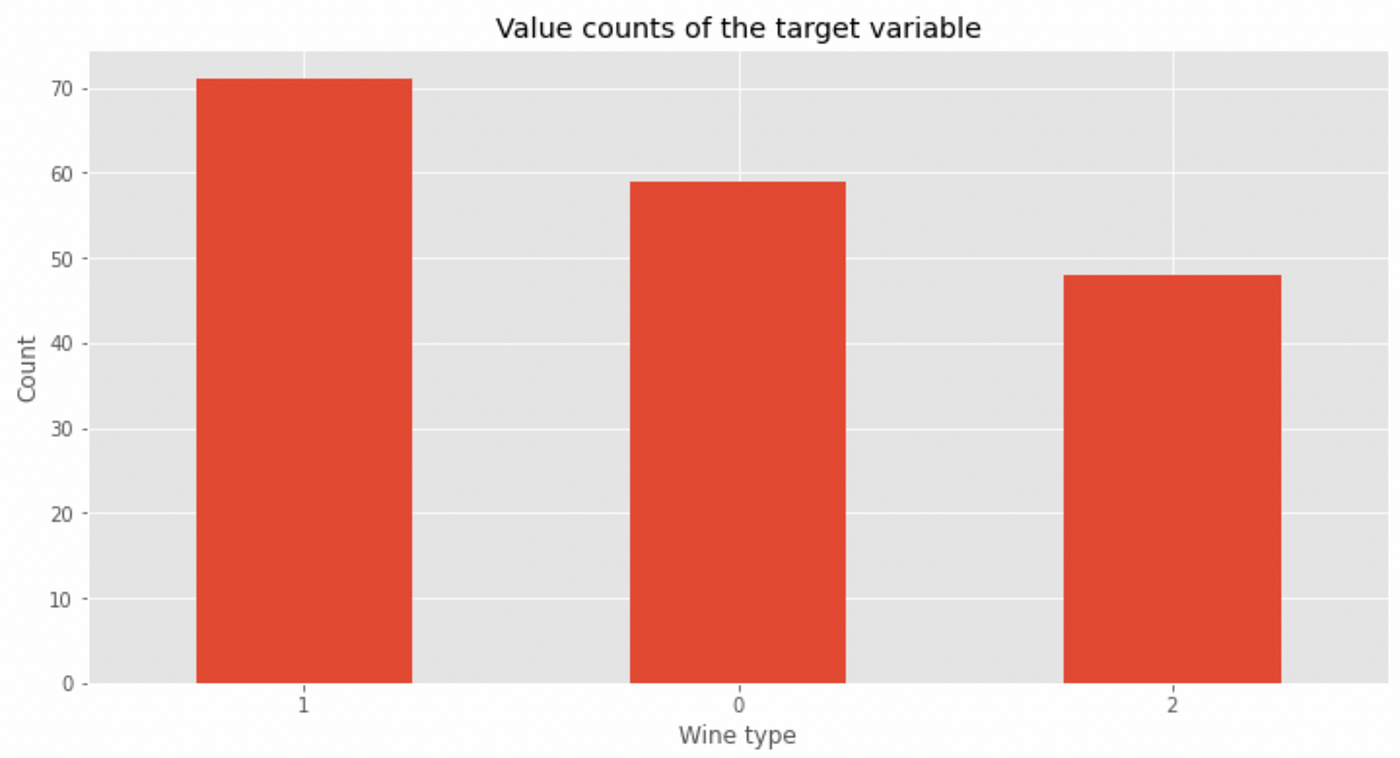
value_counts() can be utilized with any variable, however works finest with categorical variables reminiscent of our goal. This perform additionally informs us of how balanced the courses are throughout the dataset. On this case, class 2 seems lower than the opposite two courses — within the modeling part maybe we are able to implement information balancing methods to not confuse our mannequin.
Numeric variables
If as an alternative we need to analyze a numeric variable, we are able to describe its distribution with describe() as we’ve got seen earlier than and we are able to show it with .hist().
Take for instance the variable magnesium
Let’s use .describe() first
after which plot the histogram
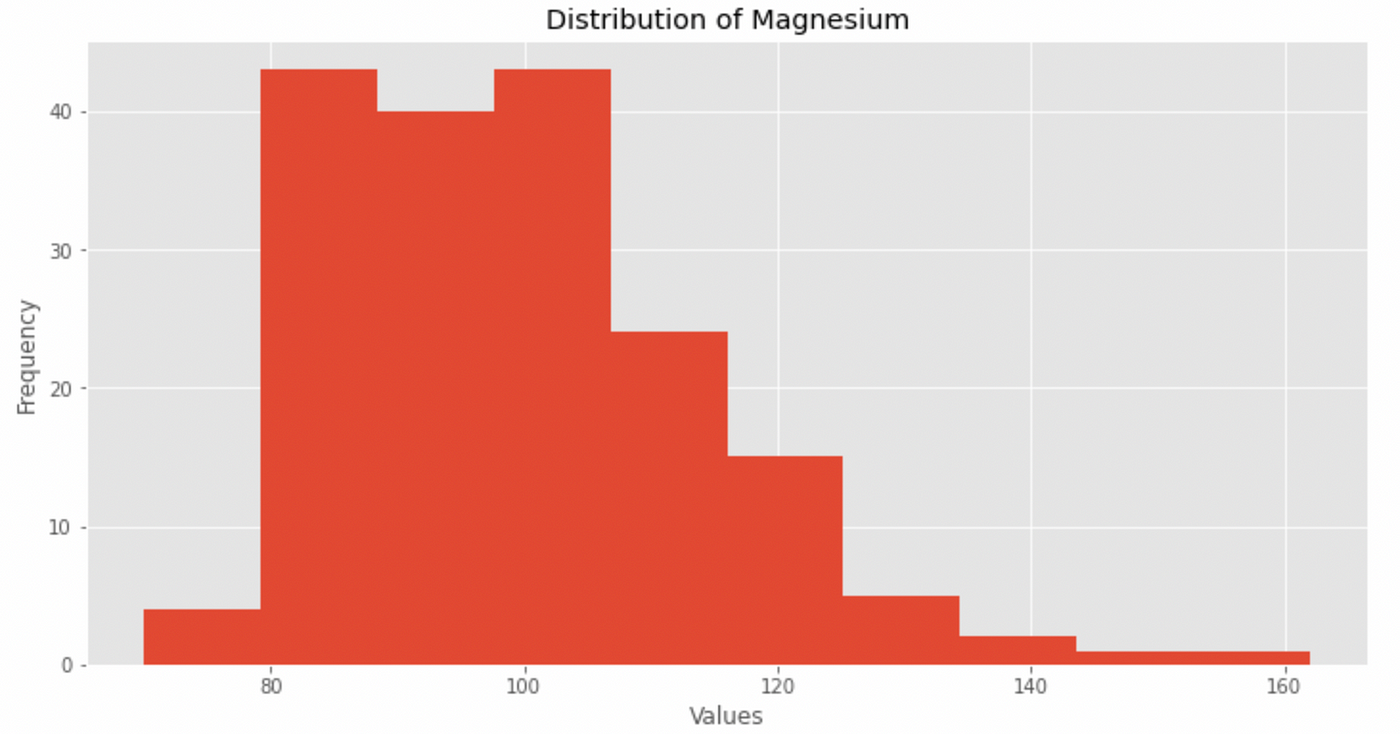
We additionally consider distribution kurtosis and asymmetry:
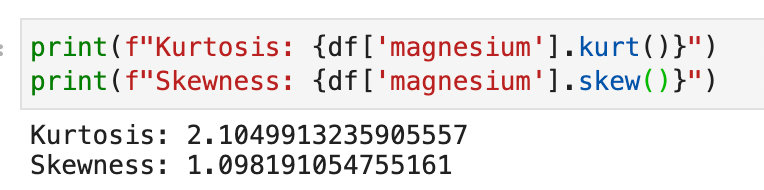
From this data we see how the distribution:
- doesn’t comply with a standard curve
- present spikes
- has kurtosis and asymmetry values better than 1
We do that for every variable, and we could have a pseudo-complete descriptive image of their conduct.
We want this work to totally perceive every variable, and unlocks the research of the connection between variables.
Now the concept is to search out attention-grabbing relationships that present the affect of 1 variable on the opposite, ideally on the goal.
This job unlocks the primary intelligence choices — in a enterprise context reminiscent of digital advertising and marketing or internet marketing, this data affords worth and the power to behave strategically.
We will begin exploring relationships with the assistance of Seaborn and pairplot.
sns.pairplot(df)
As you’ll be able to see, pairplot shows all of the variables towards one another in a scatterplot. It is vitally helpful for greedy crucial relationships with out having to undergo each single mixture manually. Be warned although — it’s computationally costly to compute, so it’s best suited to datasets with comparatively low variety of variables like this one.
Let’s analyze the pairplot ranging from the goal
One of the simplest ways to grasp the connection between a numeric variable and a categorical variable is thru a boxplot.
Let’s create a boxplot for alcohol, flavanoids, color_intensity and proline. Why these variables? As a result of visually they present barely extra marked segmentations for a given wine kind. For instance, let’s have a look at proline vs goal
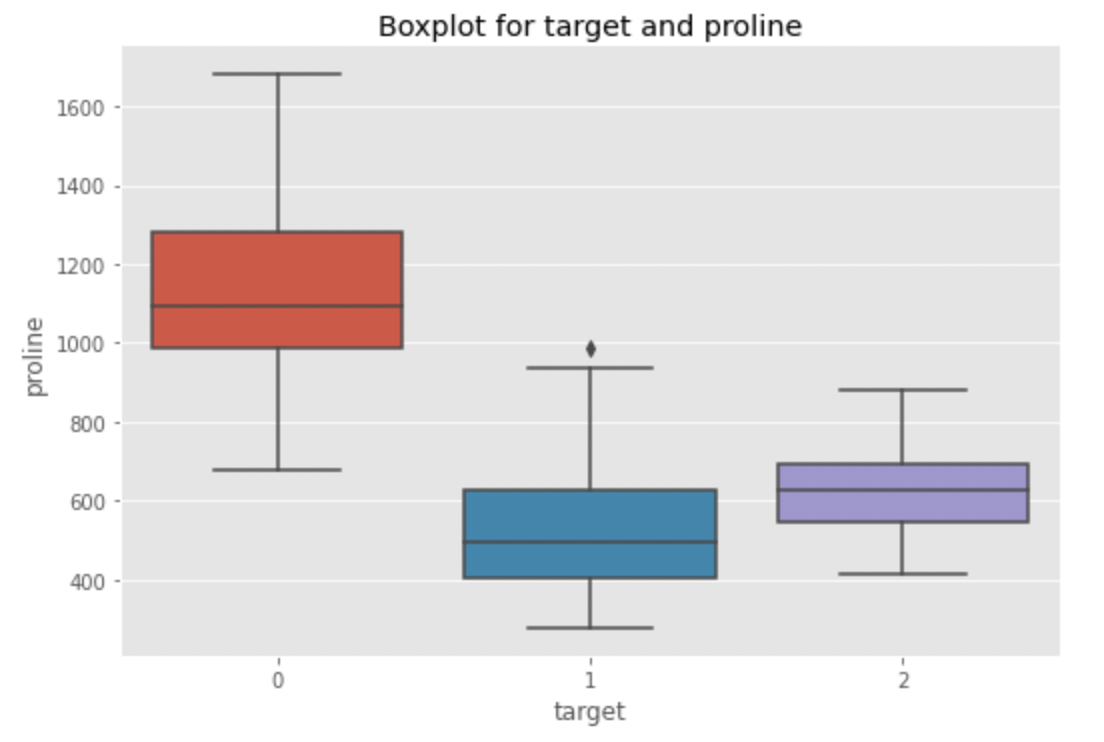
In actual fact, we see how the proline median of kind 0 wine is greater than that of the opposite two sorts. Might it’s a differentiating issue? Too early to inform. There could also be different variables to think about. Let’s see flavanoids now
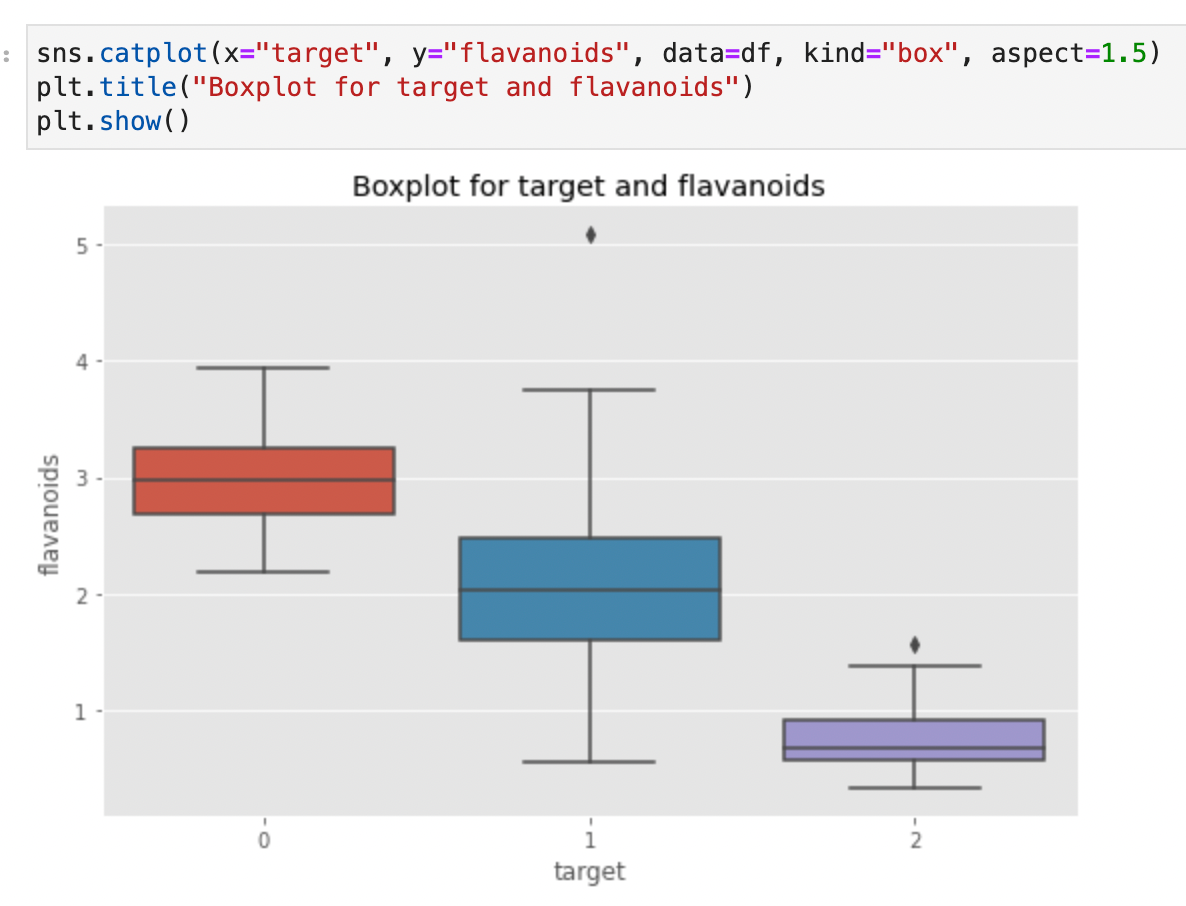
Right here too, the kind 0 wine appears to have increased values of flavanoids. Is it attainable that kind 0 wines have increased mixed ranges of proline and flavanoids? With Seaborn we are able to create a scatterplot and visualize which wine class some extent belongs to. Simply specify the hue parameter
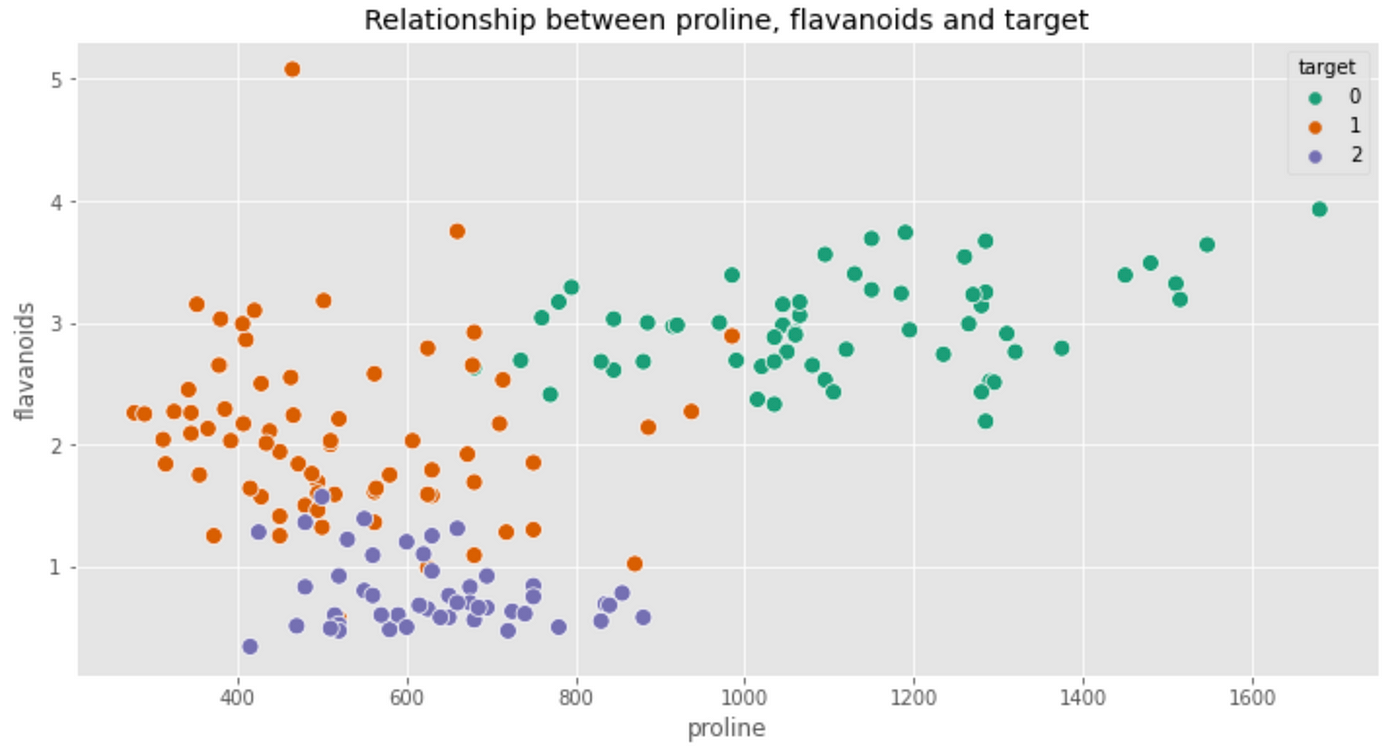
Our instinct was heading in the right direction! Sort 0 wines present clear patterns of flavanoids and proline. Specifically, the proline ranges are a lot increased whereas the flavanoid degree is steady across the worth of three.
Now let’s see how Seaborn can once more assist us increase our exploration because of the heatmap. We’re going to create a correlation matrix with Pandas and to isolate probably the most correlated variables
The warmth map is beneficial as a result of it permits us to effectively grasp which variables are strongly correlated with one another.
When the goal variable decreases (which should be interpreted as a bent to go to 0, due to this fact to the kind of wine 0) the flavanoids, complete phenols, proline and different proteins have a tendency to extend. And viceversa.
We additionally see the relationships between the opposite variables, excluding the goal. For instance, there’s a very robust correlation between alcohol and proline. Excessive ranges of alcohol correspond to excessive ranges of proline.
Let’s sum all of it up with the brainstorming part.
We’ve got collected loads of information to assist the speculation that class 0 wine has a specific chemical composition. It stays now could be to isolate what are the circumstances that differentiate kind 1 from kind 2. I’ll go away this train to the reader. At this level of the evaluation we’ve got a number of issues we are able to do:
- create a report for the stakeholders
- do modeling
- proceed with the exploration to additional make clear enterprise questions
The significance of asking the precise questions
Whatever the path we take after the EDA, asking the precise questions is what separates a great information analyst from a mediocre one. We could also be specialists with the instruments and tech, however these expertise are comparatively ineffective if we’re unable to retrieve data from the information.
Asking the precise questions permits the analyst to “be in sync” with the stakeholder, or to implement a predictive mannequin that basically works.
Once more, I urge the reader to open up their favourite textual content editor and populate it with questions every time doubts or particular ideas come up. Be obsessive — if the reply is within the information, then it’s as much as us to search out it and talk it in the very best approach.
The method described to this point is iterative in its nature. In actual fact, the exploratory evaluation goes on till we’ve got answered all of the enterprise questions. It’s not possible for me to indicate or show all of the attainable methods of knowledge exploration —we don’t have particular enterprise necessities or legitimate real-world dataset. Nevertheless, I can convey to the reader the significance of making use of a template like the next to be environment friendly within the evaluation.
If you wish to assist my content material creation exercise, be happy to comply with my referral hyperlink under and be part of Medium’s membership program. I’ll obtain a portion of your funding and also you’ll be capable to entry Medium’s plethora of articles on information science and extra in a seamless approach.
What’s your methodology to your exploratory analyses? What do you consider this one? Share your ideas with a remark 👇
Thanks to your consideration and see you quickly! 👋

{kind=link}