

Overcome LDA’s Shortcomings with Embedded Matter Fashions
The 2003 paper, Latent Dirichlet Allocation, established LDA as what’s now in all probability the most effective recognized and most generally used algorithm for subject modeling (Blei et al. 2003). But regardless of its ubiquity and longevity, these skilled with LDA are acquainted with its limitations. Along with its instability, detailed under, LDA requires greater than slightly textual content pre-processing to acquire good outcomes. Even placing apart the implementation particulars, LDA suffers from a extra common drawback that plagues subject modelers whatever the algorithm they use — the dearth of a floor reality upon which to judge their fashions.
The one dependable and constant strategy to set up a floor reality for subject fashions is to empanel consultants to create a standard corpus subject vocabulary after which to have a number of annotators apply the vocabulary to the textual content — a time consuming and costly course of. This ‘by-hand’ methodology, practiced within the social-sciences for many years, is precisely the issue that unsupervised subject modeling seeks to handle.
The sensible limitations to acquiring an goal commonplace in opposition to which a mannequin could be measured and evaluated has undoubtedly led many ML/AI practitioners to move by subject modeling for different, much less fraught endeavors. But regardless of its shortcomings, subject modeling generally, and LDA particularly, have proved sufficiently helpful to retain their recognition. One paper addressing the difficulty pithily summarizes subject modeling’s continued attraction within the face of its drawbacks observing that
…though there isn’t any assure {that a} ‘subject’ will correspond to a recognizable theme or occasion or discourse, they typically achieve this in ways in which different strategies don’t (Nguyen et al. 2020) (emphasis added).
For these authors, and plenty of others, subject modeling has proved to be ‘ok’ to warrant their continued consideration.
This text explores the concept a brand new approach, subject modeling with language embeddings, successfully addresses two of essentially the most obvious points encountered when utilizing LDA. This new strategy is detailed within the paper BERTopic: Neural Matter Modeling with a Class-Primarily based TF-IDF Process (Grootendorst 2022). BERTopic is an end-to-end instrument for producing subject fashions from embeddings information. As a default, it leverages HDBSCAN to establish subjects contained inside language embeddings. Though HDBSCAN is stochastic and topic to run-over-run variations, in my expertise it produces rather more steady and predictable subject groupings than LDA does. Secondly, as a result of BERTopic subject fashions are distinct from the embedding information they summarize, it’s potential to judge how nicely a specific run does or doesn’t signify the underlying information construction. This characteristic successfully creates a model-by-model ground-truth that can be utilized for analysis and tuning. There’s nothing comparable with LDA.
Use BERTopic, not LDA! LDA is a robust instrument for subject modeling however its instability is a significant, typically unacknowledged, stumbling block. BERTopic doesn’t undergo from the instability drawback. Importantly, this text seeks to display that phrase embeddings, used as the idea for subject modeling, can successfully create a ground-truth upon which a given subject mannequin could be evaluated and tuned. From a sensible standpoint BERTopic can also be simpler to make use of as there isn’t any textual content pre-processing and as is demonstrated under, is far much less useful resource intensive than LDA.
I’ve no official relationship to the BERTopic venture (nor with LDA or EnsembleLDA for that matter). As a companion to this text I’ve created a Tableau presentation that may permit readers to interactively discover the fashions created for the article. The information used on this article are publicly licensed and obtainable and could be discovered on Kaggle (CC0 license). I’ve pushed some technical particulars and notes into an appendix discovered on the finish of the article.
The case in opposition to LDA unfolds alongside two axes. The primary is the algorithm’s inherent instability. I’ve beforehand written about LDA subject mannequin instability and the difficulties inherent in establishing an objectively appropriate variety of goal subjects for a given LDA mannequin. All of the fashions generated for this text have been generated from the identical corpus. LDA or EnsembleLDA was run in opposition to the corpus in three completely different configurations. Every pair is evaluated to find out how nicely they agree with each other.
The primary LDA run, utilizing default parameters for the Gensim LDA implementation resulted within the following heatmap which compares the doc/subject assignments for every mannequin’s subjects:
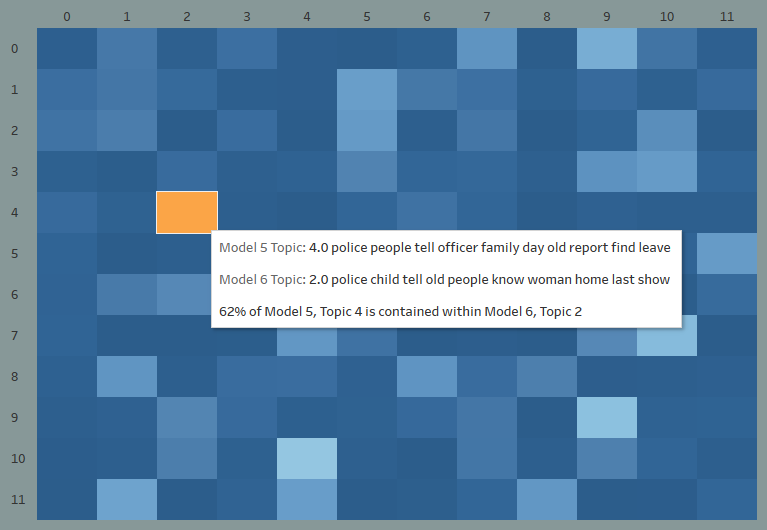
The orange cell represents the variety of paperwork which happen within the first mannequin’s subject 2 and the second’s subject 4 and registers a 62% overlap. This was by a big margin the most effective correlated subject pair for this run. Even though every mannequin rested on the identical information and an identical parameters, these fashions signify very completely different units of subjects. Nonetheless, it’s potential to get higher outcomes by rising the quantity of processing energy we throw on the drawback.
EnsembleLDA, explicitly offers with the LDA mannequin instability concern by harmonizing a number of fashions right into a single mannequin occasion. Utilizing the identical information and settings as above we see a marked enchancment in mannequin correlation:

But this enchancment comes at a price. Working on a Colab+ occasion, the primary two poorly correlated runs every took solely a matter of seconds to generate. The above improved run took greater than three hours per mannequin. If we throw extra sources on the drawback, rising processing time to over 9 hours per mannequin, the outcomes proceed to enhance:

However nonetheless, though the ultimate set of are higher correlated, the influence of LDA mannequin instability is notable. Within the first run, an arbitrary variety of subjects, twelve, was chosen and fed as a parameter to the mannequin. Nonetheless, the following 4 fashions have been generated with EnsembleLDA. One compelling characteristic of EnsembleLDA is that the algorithm, unsupervised, will converge on an optimized variety of subjects. But whereas EnsembleLDA does an honest job in choosing the variety of subjects, we should observe that within the examples there’s nonetheless no settlement about what number of subjects there are. In EnsembleLDA fashions we see eight, eleven, ten and 9 subjects respectively. So though the later fashions have considerably decreased drift of their doc/subject assignments, there’s nonetheless not settlement on the variety of subjects on this dataset.
What about different approaches to guage the correctness of LDA fashions? One of the widespread approaches is to make use of npmi based mostly coherence scores (Lau et. al. 2014). There are a variety of various variations, right here we use ‘c_v’, a standard selection. The consequence for the primary two fashions is .291 and .295 respectively. These are poorer scores than these of the second set of fashions which got here in at .578 and .566. Nonetheless, though the final set of fashions present a noticeably improved settlement between its subjects than the penultimate pair, their scores: .551 and .549, are worse than that second set. Whereas npmi based mostly metrics carry out nicely within the lab, in my expertise they typically fall nicely in need of their promise.
Visualizing the paperwork in scatterplots gives an informative visible reference that helps in understanding the distribution of every of the thirty thousand paperwork inside every mannequin. Here’s a TSNE 2D discount of one of many two finest correlated EnsembleLDA fashions:
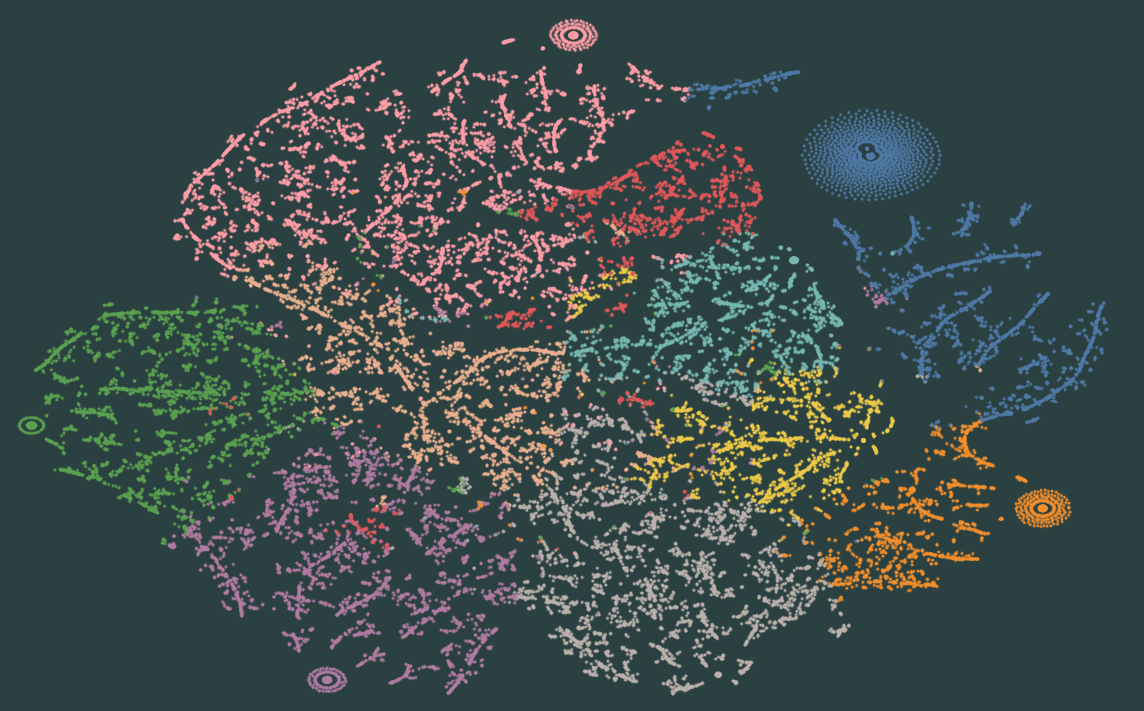
We will clearly see spatial separation between the subjects. The interactive model of this visualization permits the consumer to zoom in and hover over every dot which represents a person doc. On this method it’s potential to get a way of how the doc’s content material led them to be categorized in a specific method.
I like to recommend studying up on BERTopic’s structure and strategy in its documentation and within the articles and papers printed by its writer, Maarten Grootendorst if you’re unfamiliar with the package deal. In brief, BERTopic employs HDBSCAN (or any one other clustering mechanism you care to make use of) to find out subjects inside a corpus. Then it makes use of a variant of TF-IDF — c-TF-IDF which as a substitute of particular person paperwork to extract significant vocabularies, aggregates all the subject’s paperwork and extracts significant vocabularies from all the subject. Whereas I contemplate c-TF-IDF to be a big contribution in its personal proper, on this article I’ll deal with the subject discovery by way of the HDBSCAN clustering of the BERT sentence embeddings and evaluate it to the LDA fashions above with out referring to the c-TF-IDF vocabulary discovery part.
The problem of mannequin instability is virtually non-existent with BERTopic. Here’s a heatmap evaluating the doc assignments from two completely different fashions created with the identical corpus and utilizing the identical parameters:
By design, HDBSCAN is not going to try and categorize paperwork which fall under a threshold, these are assigned to class -1. Additionally, BERTopic re-numbers all of the subjects from the most important to smallest variety of complete paperwork which accounts for the symmetrical diagonal on the matrix above — this can be a purely aesthetic characteristic of BERTopic.
It’s notable is that consecutive BERTopic runs will largely produce the identical variety of subjects. Whereas there’s some drift and variation from mannequin to mannequin when it comes to doc project, in comparison with LDA, the diploma of instability is minimal. Lastly, these fashions have been created in a matter of minutes utilizing a Colab+ account with the GPU enabled, an enormous sensible distinction in contrast with the useful resource intensive LDA implementations which required hours of compute time.
The cautious reader will discover that BERTopic fashions used above solely produced six subjects (along with the -1 ‘subject’). When working with this corpus I found that when HDBSCAN was run in opposition to the embeddings that there was a ‘pure’ segmentation during which sports activities tales encompassed roughly one sixth of the information and damaged into 5 subject areas (apparently organized as: Soccer/Rugby/Cricket, Race Vehicles, Golf, Tennis, Boxing, Swimming/Working/Olympics) and all the remaining have been organized right into a super-cluster of non-sports associated paperwork. In consequence, I cut up the dataset into two components, sports activities and not-sports. When BERT was run these two segmented corpora, the sports activities phase retained the identical inner group as appeared within the authentic corpus, dividing the sports activities into six segments. Nonetheless the ‘non-sports’ blob that was previously one single class broke down into ten separate subjects. My assumption concerning the cause that HDBSCAN had hassle subdividing the non-sports super-cluster was that the inherent geometries of the information when it was all in a single group have been merely past HDBSCANs talents to phase the bigger set into finer groupings whereas concurrently dividing up the sports activities subjects. When the corpus was damaged into two separate components, every little thing fell into place.
Due to this, and since there aren’t any instruments (but) inside BERTopic to carry out this sort of operation, the subject groupings under are assembled from two completely different BERTopic fashions. The instruments and strategies used to reach on the appropriate HDBSCAN parameters are past the scope of this text.
Beneath is a 2D TSNE projection of the BERT embeddings overlaid with the ultimate subjects from BERTopic with the -1 paperwork eliminated:
On the higher left facet of the picture the big pink cluster is usually soccer with rugby and cricket. The opposite sports activities: Race Vehicles, Golf, Tennis, Boxing, and Swimming/Working/Olympics, are within the 5 clusters instantly under and to the left of it. The Tableau presentation permits the consumer to freely traverse the dataset and see right down to the doc stage to study extra about how BERTopic segmented this corpus.
One other segmentation that demonstrates the flexibility of BERTopic to make fine-grained, beneficial distinctions between subjects. This capacity appears far exterior LDA’s grasp. One other instance of the delicate distinctions observable within the BERTopic mannequin could be seen with the big central inexperienced cluster and the 2 separated inexperienced clusters to its left. These are all a part of one subject with its subject phrases:
Canine, animals, animal, canines, species, simply, like, cat, zoo, time
The leftmost cluster appears to be principally or all about canines, the center about cats, and the big grouping (spatially organized from left to proper) about unique animals, wild animals, marine life after which a grouping on the edges of this bigger cluster having to do with archeological points and a smattering of organic science paperwork thrown in. This sort of clear spatial/semantic group could be discovered all through the BERTopic mannequin.
We will use the scatterplots to match the 2 completely different fashions created by BERTopic and LDA. First we are able to overlay the LDA subjects onto the BERTopic mannequin:
The LDA subjects are typically nicely correlated with the coordinate positions extrapolated from the BERT embeddings. In different phrases the smaller variety of LDA subjects kind of match into the subject groupings that BERTopic generated. Utilizing a heatmap of the identical BERT to LDA mappings we see one other view of the identical, fairly nicely ordered information:

The 0 and 1 LDA subjects are the sports activities associated tales. We will see that LDA broke these paperwork into two clusters and BERTopic into 6. Six different BERTopic subjects roughly correspond to the LDA subjects, however the remaining 4 BERTopic subjects clusters haven’t any clear relationship to the LDA subjects.
The reverse view, projecting the BERT Subjects on the LDA coordinates reveals a extra chaotic view:
On this case we are able to see that whereas some areas are broadly congruent, the place there are disagreements issues are fairly disorganized. For instance, the pink space on the appropriate with the 2 ‘eyes’ are the sports activities tales. Each fashions did a superb job choosing out the soccer tales. Nonetheless, the LDA mannequin was unable to distinguish successfully between the completely different sorts of sports activities.
The flipped heatmap reveals the extent of confusion in numerous kind:
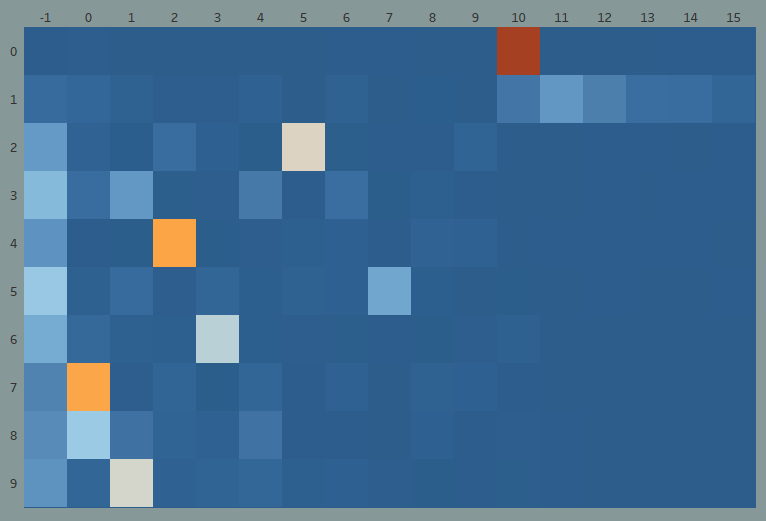
Solely three LDA subjects could be stated to be correlated to any diploma with their BERTopic equivalents.
The 2 fashions above, one created with BERTopic and the opposite with EnsembleLDA, are clearly completely different and it’s onerous to search out rather more than passing settlement about their respective doc/subject assignments. The place can we flip to rationalize this disagreement? Matter modelers cope with this sort of uncertainty on a regular basis. Since there isn’t any ground-truth upon which to base an goal measure, modelers are left to reach at the most effective knowledgeable subjective judgement that they will muster.
But I argue that embeddings based mostly subject fashions provide a substitute for resorting to purely subjective measures. With the above information I felt assured in an evaluation of the scatterplots that the BERTopic mannequin is extra exact in its subject cluster definition. Moreover, there was no method I used to be in a position to determine to leverage the LDA scatterplots to discern something significant concerning the group of the underlying information or what might be accomplished to enhance the mannequin. Whereas every particular person scatterplot is an honest illustration of that specific mannequin, so far as I may inform it has nothing to say concerning the underlying semantic construction of the paperwork themselves. Time and again the BERT based mostly scatterplots revealed surprisingly nicely organized and necessary details about the paperwork, expressed in rationalized spatial relationships. There’s nothing corresponding to be discovered within the LDA visualizations.
Hopefully this text has sparked an curiosity in subject modeling with embeddings generally, and BERTopic particularly. The easy sensible info introduced right here: that BERTopic requires no textual content pre-processing; the demonstrated problems with LDA mannequin instability; and the dramatic distinction in compute sources required between the 2, is hopefully sufficient to peek the curiosity of each starting and skilled subject modelers.
Nonetheless, past these sensible concerns, is the instinct that the embeddings that BERTopic makes use of for its subject mannequin successfully set up a heretofore elusive floor reality for subject modeling. Primarily based on my explorations to this point it appears affordable to argue that the BERT embeddings create a firmer floor upon which to created subject fashions than does LDA.
After we view LDA embeddings we’re seeing the outcomes of a mathematical course of that has solely the speedy corpus upon which to function and extrapolate semantic that means. Every LDA mannequin represents a small, closed universe of relationships. When utilizing embeddings we’re connecting our information to a a lot, a lot bigger physique of data that claims to, at some stage, signify language itself. It appears to me that this bigger relationship is seen when analyzing embeddings based mostly mannequin information.
The information used for these examples is a randomly chosen, 30,000 article subset (CC0 license) of a bigger publicly licensed dataset known as Information Articles (CC0 license).
As famous within the article I stepped exterior of BERTopic to reach at optimized HDBSCAN parameters to make use of with BERTopic to get the output proven right here. The strategy used to reach at them was to extract the embeddings (truly the UMAP discount of the embedding) from the BERTopic mannequin after which to run a sequence of experiments that various the min_sample_size and min_cluster_size HDBSCAN parameters. The output was judged on the variety of subjects clusters recognized and the variety of outlier, -1, doc assignments. What I discovered with this dataset was that there have been ‘pure’ numbers of subjects created when operating randomly chosen values for dozens of runs. With this information the numbers of subjects clustered round 3, 7, after which jumped to over 50. I selected parameters that produced these cluster configurations with the smallest variety of outliers after which ran scatterplots. Primarily based on these outcomes I decided that it would make sense to interrupt the corpus into two components and re-run the tuning experiments. The ultimate result’s what’s proven above and types the information for the Tableau presentation. I hope to write down up this method in additional element sooner or later, these within the specifics are inspired to contact me through my LinkedIn account present in my profile.
Teachers have acknowledged and addressed the dearth of a ground-truth as being an impediment for subject modeling. To learn extra about this concern I recommend:
Nguyen, D., Liakata, M., DeDeo, S., Eisenstein, J., Mimno, D., Tromble, R., & Winters, J. (2020). How We Do Issues With Phrases: Analyzing Textual content as Social and Cultural Information. Frontiers in Synthetic Intelligence, 3, 62.
O’connor, B., Bamman, D., & Smith, N. A. (n.d.). Computational textual content evaluation for social science: Mannequin assumptions and complexity. Retrieved June 28, 2022, from https://folks.cs.umass.edu/~wallach/workshops/nips2011css/papers/OConnor.pdf
Matter Modeling within the Humanities: An Overview. (n.d.). Retrieved June 28, 2022, from https://mith.umd.edu/information/topic-modeling-in-the-humanities-an-overview/
Referenced within the article:
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Studying Analysis: JMLR. https://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf?ref=https://githubhelp.com
Grootendorst, M. (2022). BERTopic: Neural subject modeling with a class-based TF-IDF process. In arXiv [cs.CL]. arXiv. http://arxiv.org/abs/2203.05794
Lau, J. H., Newman, D., & Baldwin, T. (2014). Machine Studying Tea Leaves: Mechanically Evaluating Matter Coherence and Matter Mannequin High quality. Proceedings of the 14th Convention of the European Chapter of the Affiliation for Computational Linguistics, 530–539.

{kind=link}