This publish gathers 10 concepts that I discovered thrilling and impactful this yr—and that we’ll seemingly see extra of sooner or later.
For every concept, I’ll spotlight 1-2 papers that execute them nicely. I attempted to maintain the record succinct, so apologies if I didn’t cowl all related work. The record is essentially subjective and covers concepts primarily associated to switch studying and generalization. Most of those (with some exceptions) should not developments (however I believe that some would possibly change into extra ‘stylish’ in 2019). Lastly, I might like to examine your highlights within the feedback or see highlights posts about different areas.
1) Unsupervised MT
There have been two unsupervised MT papers at ICLR 2018. They have been stunning in that they labored in any respect, however outcomes have been nonetheless low in comparison with supervised techniques. At EMNLP 2018, unsupervised MT hit its stride with two papers from the identical two teams that considerably enhance upon their earlier strategies. My spotlight:
- Phrase-Primarily based & Neural Unsupervised Machine Translation (EMNLP 2018): The paper does a pleasant job in distilling the three key necessities for unsupervised MT: a great initialization, language modelling, and modelling the inverse job (by way of back-translation). All three are additionally helpful in different unsupervised eventualities, as we’ll see beneath. Modelling the inverse job enforces cyclical consistency, which has been employed in numerous approaches—most prominently in CycleGAN. The paper performs in depth experiments and evaluates even on two low-resource language pairs, English-Urdu and English-Romanian. We’ll hopefully see extra work on low-resource languages sooner or later.
2) Pretrained language fashions
Utilizing pretrained language fashions might be the most important NLP pattern this yr, so I will not spend a lot time on it right here. There have been a slew of memorable approaches: ELMo, ULMFiT, OpenAI Transformer, and BERT. My spotlight:
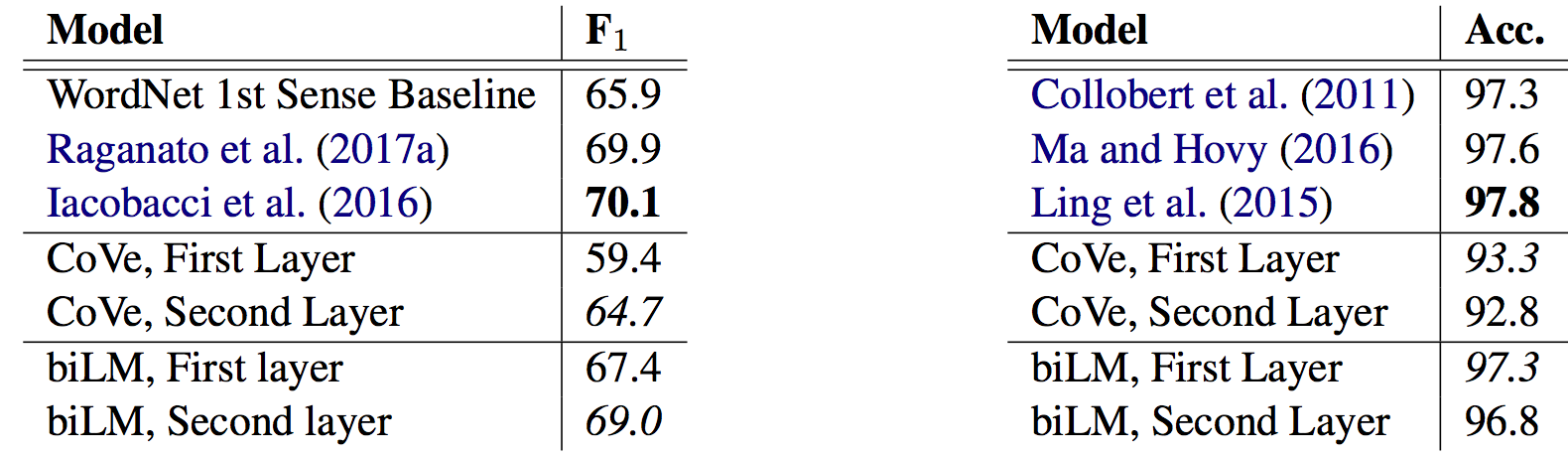
- Deep contextualized phrase representations (NAACL-HLT 2018): The paper that launched ELMo has been a lot lauded. In addition to the spectacular empirical outcomes, the place it shines is the cautious evaluation part that teases out the affect of varied elements and analyses the knowledge captured within the representations. The phrase sense disambiguation (WSD) evaluation by itself (beneath on the left) is nicely executed. Each exhibit {that a} LM by itself supplies WSD and POS tagging efficiency near the state-of-the-art.
3) Widespread sense inference datasets
Incorporating frequent sense into our fashions is likely one of the most vital instructions shifting ahead. Nonetheless, creating good datasets is just not straightforward and even well-liked ones present massive biases. This yr, there have been some well-executed datasets that search to show fashions some frequent sense equivalent to Event2Mind and SWAG, each from the College of Washington. SWAG was solved unexpectedly rapidly. My spotlight:
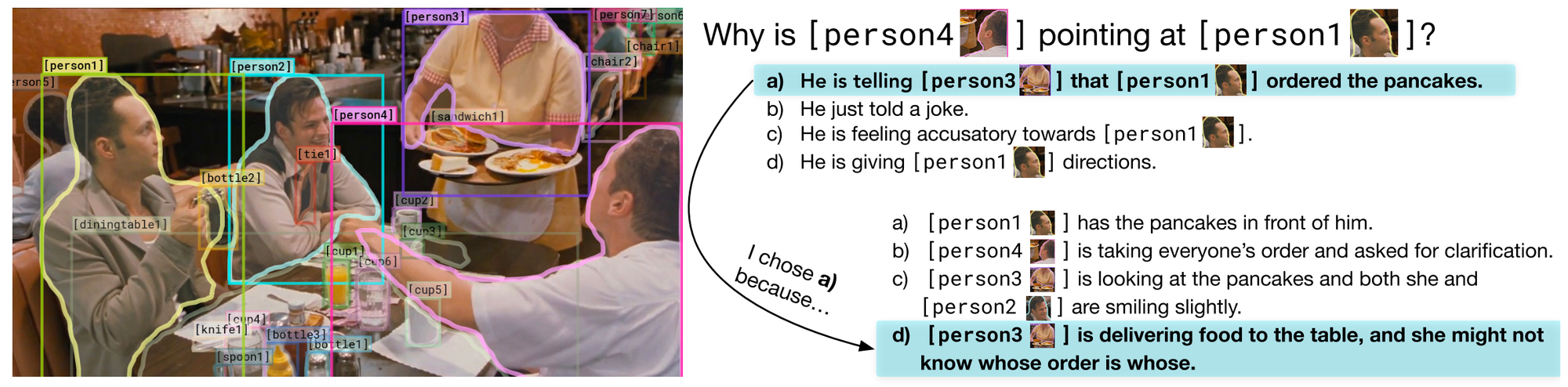
- Visible Commonsense Reasoning (arXiv 2018): That is the primary visible QA dataset that features a rationale (an explantation) with every reply. As well as, questions require complicated reasoning. The creators go to nice lengths to deal with potential bias by guaranteeing that each reply’s prior likelihood of being appropriate is 25% (each reply seems 4 instances in all the dataset, 3 instances as an incorrect reply and 1 time as the proper reply); this requires fixing a constrained optimization drawback utilizing fashions that compute relevance and similarity. Hopefully stopping potential bias will change into a typical part when creating datasets. Lastly, simply have a look at the attractive presentation of the info 👇.
Meta-learning has seen a lot use in few-shot studying, reinforcement studying, and robotics—probably the most distinguished instance: model-agnostic meta-learning (MAML)—however profitable functions in NLP have been uncommon. Meta-learning is most helpful for issues with a restricted variety of coaching examples. My spotlight:
- Meta-Studying for Low-Useful resource Neural Machine Translation (EMNLP 2018): The authors use MAML to study a great initialization for translation, treating every language pair as a separate meta-task. Adapting to low-resource languages might be probably the most helpful setting for meta-learning in NLP. Particularly, combining multilingual switch studying (equivalent to multilingual BERT), unsupervised studying, and meta-learning is a promising course.
5) Sturdy unsupervised strategies
This yr, we and others have noticed that unsupervised cross-lingual phrase embedding strategies break down when languages are dissimilar. It is a frequent phenomenon in switch studying the place a discrepancy between supply and goal settings (e.g. domains in area adaptation, duties in continuous studying and multi-task studying) results in deterioration or failure of the mannequin. Making fashions extra sturdy to such modifications is thus vital. My spotlight:
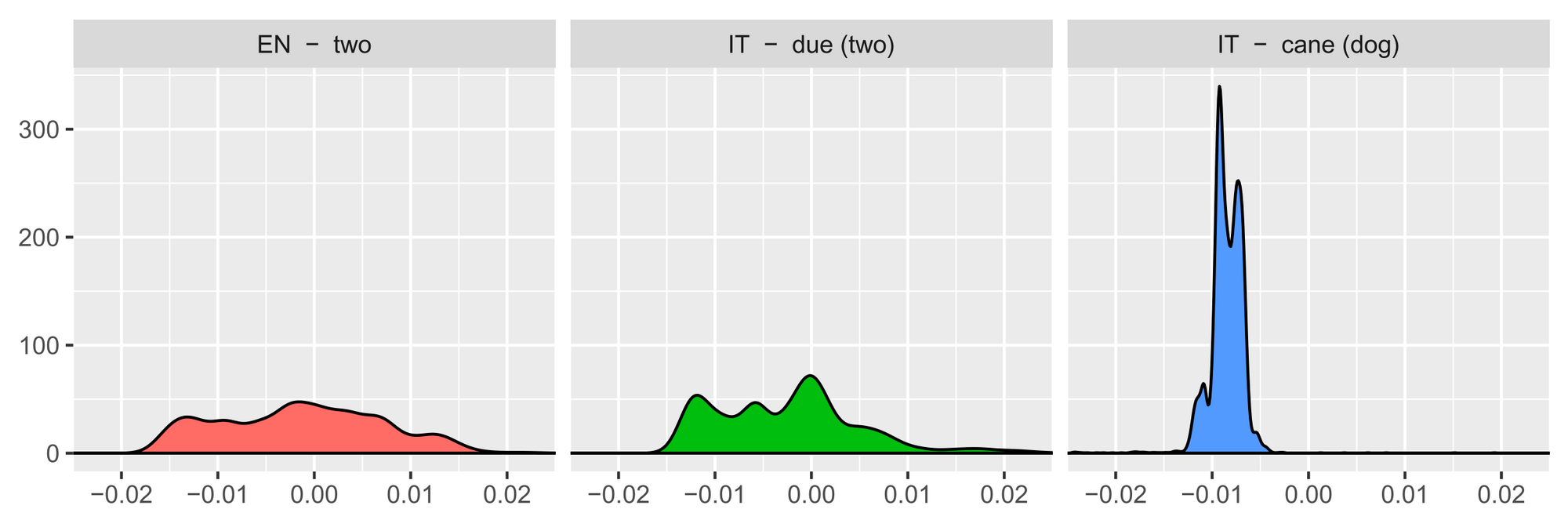
6) Understanding representations
There have been a number of efforts in higher understanding representations. Particularly, ‘diagnostic classifiers’ (duties that goal to measure if discovered representations can predict sure attributes) have change into fairly frequent. My spotlight:
7) Intelligent auxiliary duties
In lots of settings, now we have seen an rising utilization of multi-task studying with fastidiously chosen auxiliary duties. For a great auxiliary job, knowledge have to be simply accessible. One of the crucial distinguished examples is BERT, which makes use of next-sentence prediction (that has been utilized in Skip-thoughts and extra just lately in Fast-thoughts) to nice impact. My highlights:
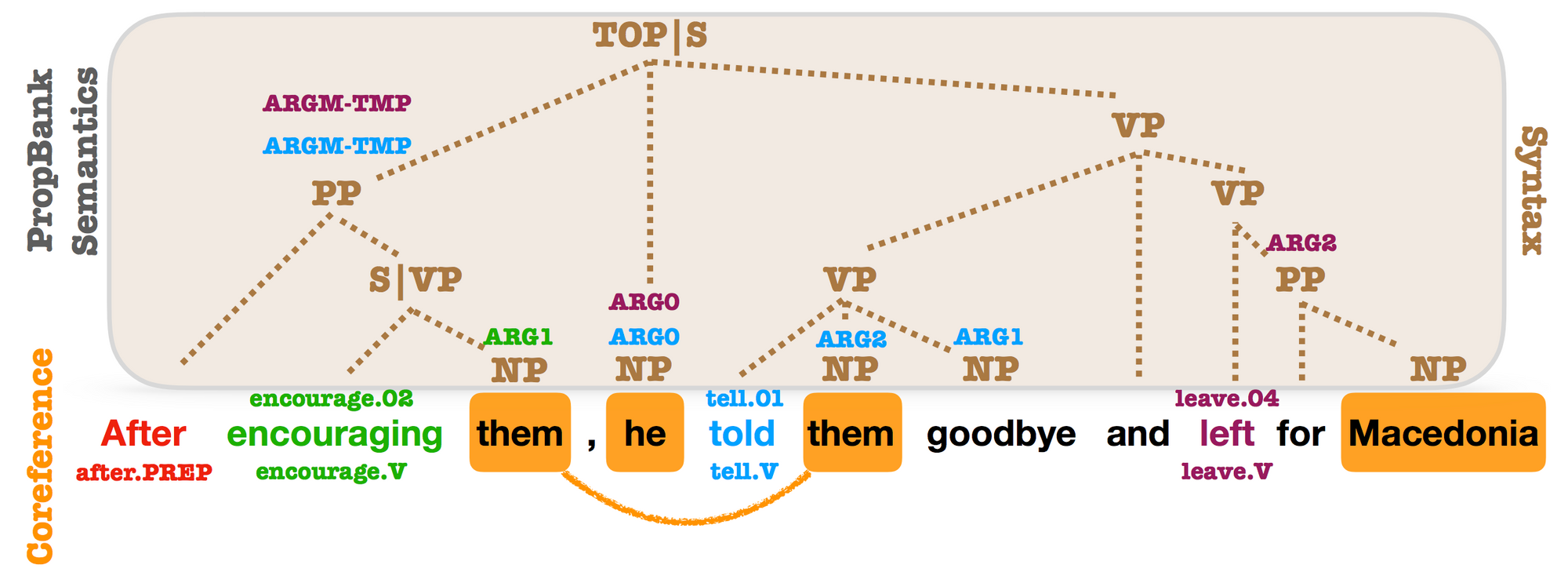
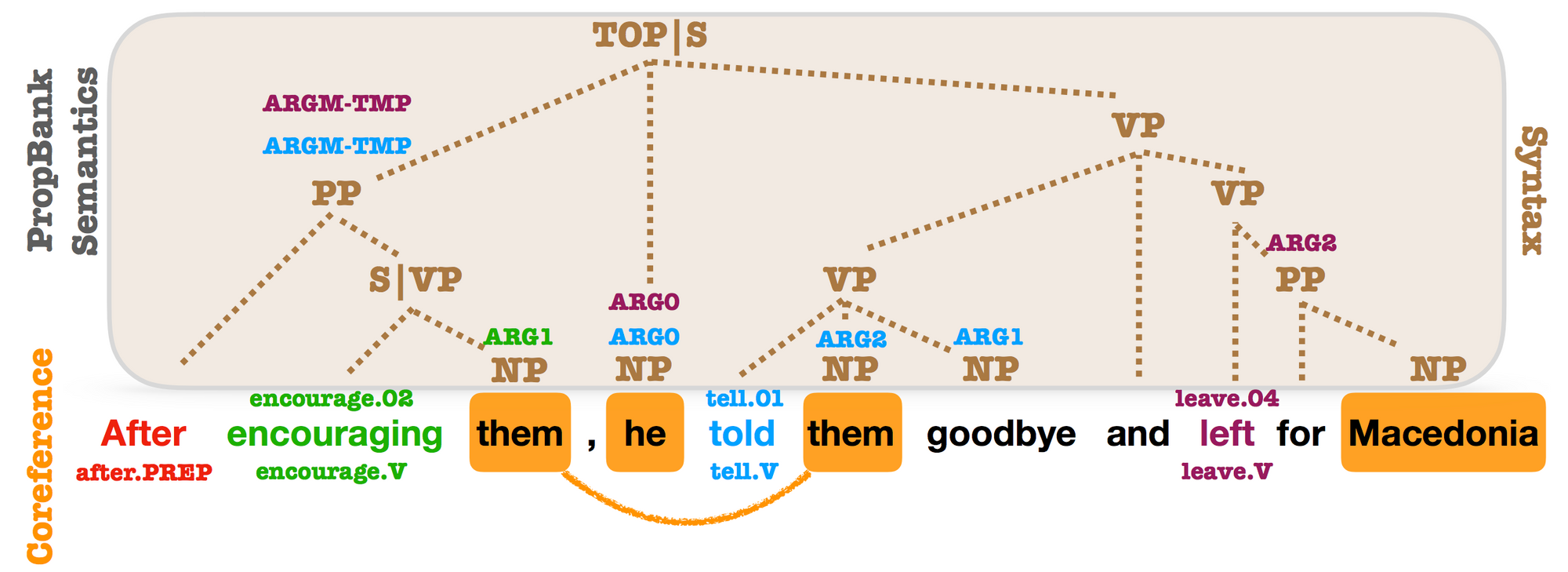
- Syntactic Scaffolds for Semantic Constructions (EMNLP 2018): This paper proposes an auxiliary job that pretrains span representations by predicting for every span the corresponding syntactic constituent kind. Regardless of being conceptually easy, the auxiliary job results in massive enhancements on span-level prediction duties equivalent to semantic function labelling and coreference decision. This papers reveals that specialised representations discovered on the degree required by the goal job (right here: spans) are immensely helpful.
- pair2vec: Compositional Phrase-Pair Embeddings for Cross-Sentence Inference (arXiv 2018): In an analogous vein, this paper pretrains phrase pair representations by maximizing the pointwise mutual info of pairs of phrases with their context. This encourages the mannequin to study extra significant representations of phrase pairs than with extra common targets, equivalent to language modelling. The pretrained representations are efficient in duties equivalent to SQuAD and MultiNLI that require cross-sentence inference. We will count on to see extra pretraining duties that seize properties notably suited to sure downstream duties and are complementary to extra general-purpose duties like language modelling.
8) Combining semi-supervised studying with switch studying
With the current advances in switch studying, we should always not overlook extra express methods of utilizing goal task-specific knowledge. In actual fact, pretrained representations are complementary with many types of semi-supervised studying. We’ve got explored self-labelling approaches, a specific class of semi-supervised studying. My spotlight:
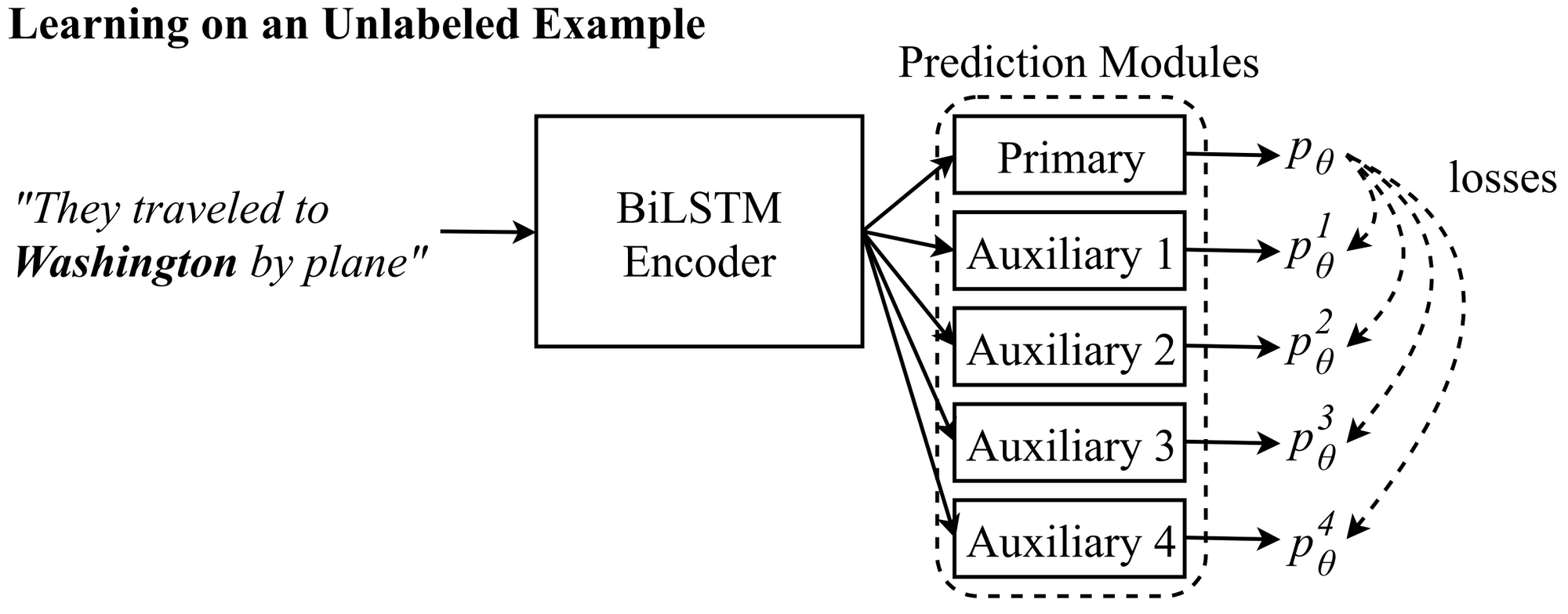
- Semi-Supervised Sequence Modeling with Cross-View Coaching (EMNLP 2018): This paper reveals {that a} conceptually quite simple concept, ensuring that the predictions on completely different views of the enter agree with the prediction of the primary mannequin, can result in positive aspects on a various set of duties. The concept is much like phrase dropout however permits leveraging unlabelled knowledge to make the mannequin extra sturdy. In comparison with different self-ensembling fashions equivalent to imply trainer, it’s particularly designed for specific NLP duties. With a lot work on implicit semi-supervised studying, we’ll hopefully see extra work that explicitly tries to mannequin the goal predictions going ahead.
9) QA and reasoning with massive paperwork
There have been a number of developments in query answering (QA), with an array of new QA datasets. In addition to conversational QA and performing multi-step reasoning, probably the most difficult side of QA is to synthesize narratives and huge our bodies of data. My spotlight:
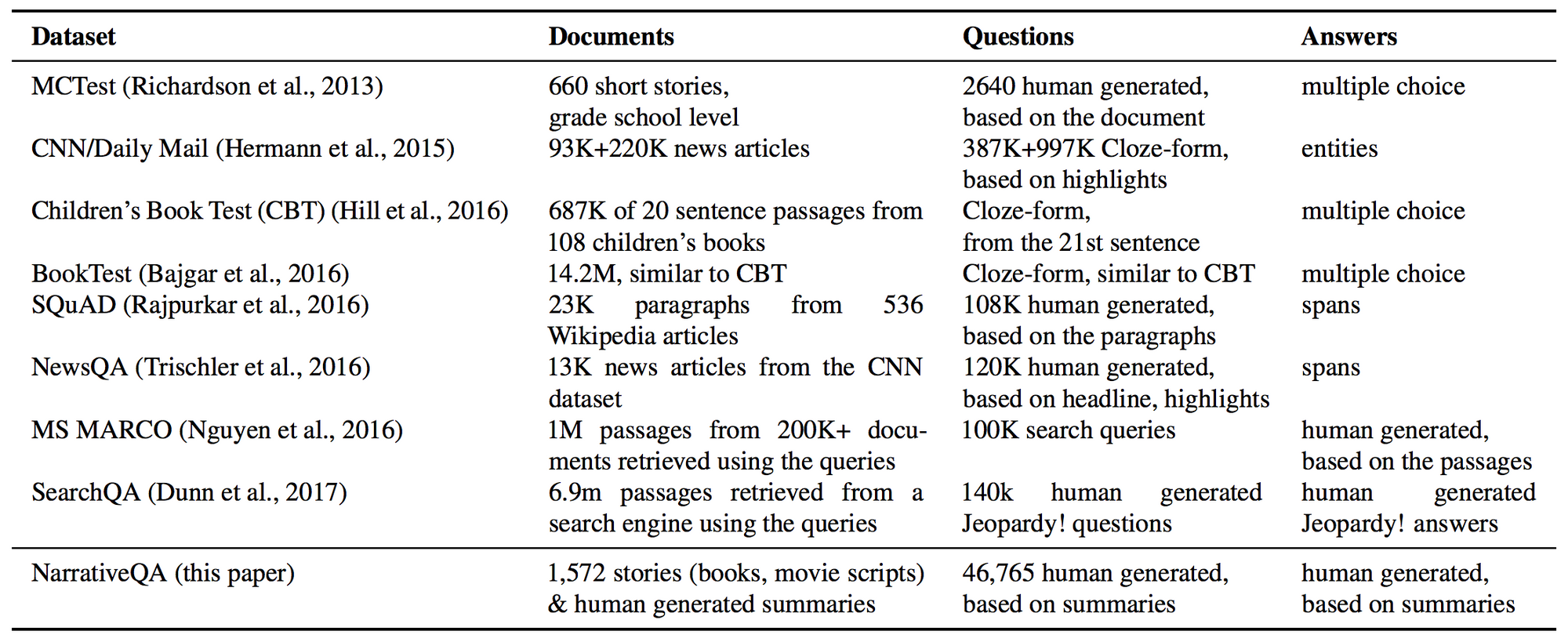
- The NarrativeQA Studying Comprehension Problem (TACL 2018): This paper proposes a difficult new QA dataset primarily based on answering questions on whole film scripts and books. Whereas this job continues to be out of attain for present strategies, fashions are supplied the choice of utilizing a abstract (moderately than all the e-book) as context, of choosing the reply (moderately than generate it), and of utilizing the output from an IR mannequin. These variants make the duty extra possible and allow fashions to steadily scale as much as the complete setting. We’d like extra datasets like this that current bold issues, however nonetheless handle to make them accessible.
10) Inductive bias
Inductive biases equivalent to convolutions in a CNN, regularization, dropout, and different mechanisms are core elements of neural community fashions that act as a regularizer and make fashions extra sample-efficient. Nonetheless, arising with a broadly helpful inductive bias and incorporating it right into a mannequin is difficult. My highlights:
- Sequence classification with human consideration (CoNLL 2018): This paper proposes to make use of human consideration from eye-tracking corpora to regularize consideration in RNNs. On condition that many present fashions equivalent to Transformers use consideration, discovering methods to coach it extra effectively is a vital course. It is usually nice to see one other instance that human language studying may also help enhance our computational fashions.
- Linguistically-Knowledgeable Self-Consideration for Semantic Position Labeling (EMNLP 2018): This paper has rather a lot to love: a Transformer educated collectively on each syntactic and semantic duties; the flexibility to inject high-quality parses at take a look at time; and out-of-domain analysis. It additionally regularizes the Transformer’s multi-head consideration to be extra delicate to syntax by coaching one consideration head to take care of the syntactic mother and father of every token. We’ll seemingly see extra examples of Transformer consideration heads used as auxiliary predictors specializing in specific features of the enter.


{kind=link}