
On this article, we’re going to see learn how to get a regression mannequin abstract from sci-kit be taught.
It may be finished in these methods:
- Scikit-learn Packages
- Stats mannequin bundle
Instance 1: Utilizing scikit-learn.
Chances are you’ll wish to extract a abstract of a regression mannequin created in Python with Scikit-learn. Scikit-learn doesn’t have many built-in capabilities for analyzing the abstract of a regression mannequin as a result of it’s usually used for prediction. Scikit be taught has completely different attributes and strategies to get the mannequin abstract.
We imported the mandatory packages. Then the iris dataset is loaded from sklearn.datasets. And have and goal arrays are created then take a look at and prepare units are created utilizing the train_test_split() methodology and the easy linear regression mannequin is created then prepare knowledge is fitted into the mannequin, and predictions are carried out on the take a look at set utilizing .predict() methodology.
Python3
|
|
Output:
[ 1.23071715 -0.04010441 2.21970287 1.34966889 1.28429336 0.02248402
1.05726124 1.82403704 1.36824643 1.06766437 1.70031437 -0.07357413
-0.15562919 -0.06569402 -0.02128628 1.39659966 2.00022876 1.04812731
1.28102792 1.97283506 0.03184612 1.59830192 0.09450931 1.91807547
1.83296682 1.87877315 1.78781234 2.03362373 0.03594506 0.02619043]
mannequin intercept : 0.2525275898181484
mannequin coefficients : [-0.11633479 -0.05977785 0.25491375 0.54759598]
Mannequin rating : 0.9299538012397455
Instance 2: Utilizing the abstract() methodology of Stats mannequin bundle
On this methodology, we use the statsmodels. method.api bundle. If you wish to extract a abstract of a regression mannequin in Python, it is best to use the statsmodels bundle. The code beneath demonstrates learn how to use this bundle to suit the identical a number of linear regression mannequin as within the earlier instance and procure the mannequin abstract.
To entry and obtain the CSV file click on right here.
Python3
|
|
Output:
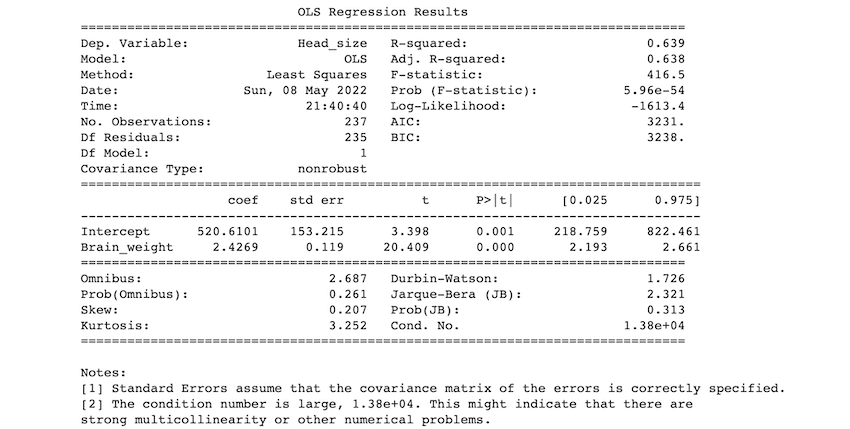
Description of a number of the phrases within the desk :
- R-squared worth: The R-squared worth ranges from 0 to 1. An R-squared of 100% signifies that adjustments within the unbiased variable utterly clarify all adjustments within the dependent variable (s). If the r-squared worth is 1, it signifies an ideal match. The r-squared worth in our instance is 0.638.
- F-statistic: The F-statistic compares the mixed impact of all variables. Merely put, in case your alpha stage is bigger than your p-value, it is best to reject the null speculation.
- coef: the coefficients of the regression equation’s unbiased variables.
Our predictions:
If we use 0.05 as our significance stage, we reject the null speculation and settle for the choice speculation as p< 0.05. Because of this, we are able to conclude that there’s a relation between head dimension and mind weight.


{kind=link}