Information labeling is essential for the machine studying venture’s success
Information science initiatives contain quite a lot of knowledge assortment, cleansing, and processing. We did all of the steps to make sure that the dataset high quality was good for the machine studying coaching. Though, there may be one particular essential a part of the information science venture that might make or break the venture: labeling.
Each knowledge science venture is developed to unravel a particular enterprise drawback, for instance, churn, propensity-to-buy, fraud, and so forth. It’s simple to consider the theme, however the labeling course of turns into difficult as soon as we have to think about the enterprise facet.
The identical churn venture may have a special label due to various enterprise necessities — one venture may solely think about individuals who churn inside a 12 months, and the opposite needs to foretell the general churn. See how totally different the label is already? That’s the reason the labeling course of is important.
To assist knowledge individuals engaged on their label processing, I wish to introduce a number of Python packages that I really feel are helpful for on a regular basis jobs. What have been the packages? Let’s get into it.
Compose is a Python package deal developed to automate predictive engineering work. Compose is specifically created to generate labels for supervising prediction issues. The person defines the label standards and Compose runs the historic knowledge to create the label prediction.
Compose is generally designed to work with an automatic characteristic engineering package deal referred to as featuretools and EvalML for automated machine studying, however on this article, we are going to concentrate on Compose.
Let’s begin by putting in the Compose package deal.
pip set up composeml
Additionally, for this instance, I’d use the groceries dataset from the Kaggle by Heerla Dedhia which commercially out there to make use of.
import pandas as pddf = pd.read_csv('Groceries_dataset.csv')
df['Date'] = pd.to_datetime(df['Date'])df.head()
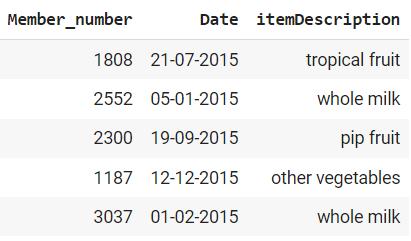
The dataset comprises 3 columns: The ID (‘Member_number’), the time of purchases (‘Date’), and the merchandise purchased (‘itemDescription’).
Now think about that we have now a enterprise query:
“Will clients buy one thing throughout the subsequent procuring interval?”
From the questions above, we may attempt to reply them utilizing the out there dataset, however we have to think about two parameters:
- What’s the product the client would purchase?
- How lengthy is the subsequent procuring interval?
Let’s say we wish to know the client if they’d purchase entire milk within the subsequent 3 days; then, we may attempt to create the labeling based mostly on this definition.
To begin utilizing the Compose package deal for the labeling job, we have to outline the label perform that matches our standards first.
def bought_product(ds, itemDescription): return ds.itemDescription.str.comprises(itemDescription).any()
The above code would verify if a buyer purchased a selected product. After creating the labeling perform, we’d arrange the label maker utilizing the next code.
lm = cp.LabelMaker(#We wish to course of every buyer so we use the Buyer ID
target_dataframe_name='Member_number',#As a result of we wish to know if the client purchased merchandise on the subsequent interval, we would wish the time column
time_index='Date',#Set the label perform
labeling_function=bought_product,#How lengthy the procuring Interval (or any interval between time)
window_size='3d'
)
After we had already set the LabelMaker class, we’d be able to run the label maker course of.
lt = lm.search(#The dataset
df.sort_values('Date'),#Variety of label per clients, -1 means discover all the present
num_examples_per_instance=-1,#What product we wish to discover
itemDescription='entire milk',minimum_data='3d',
verbose=False,)lt.head()
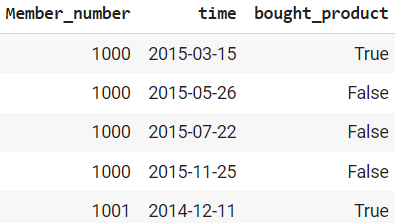
The output three columns have been defined beneath:
- The Member_number is said to the purchases. As every buyer may purchase greater than as soon as, there might be multiple instance.
- The time is the beginning of the procuring interval. It is usually a cutoff time for constructing options.
- They have been calculated by labeling perform if the product was purchased throughout the interval window.
We may use the next code to get the label abstract of our consequence.
lt.describe()
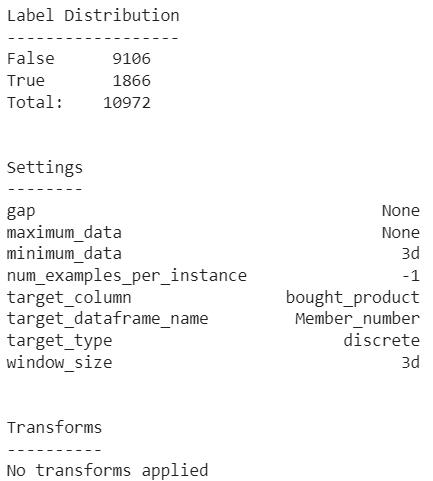
From the labeling course of, we may see that there’s an imbalance instance that occurs in our search. Plainly there aren’t many purchasers who purchased entire milk inside 3 days of the procuring interval.
That’s the instance of Compose. If you wish to check out different knowledge or take a look at one other instance, we may go to the Tutorial.
Snorkel is a Python package deal developed particularly for constructing dataset labels with none handbook labeling course of. Snorkel was aimed to scale back the period of time used for the label work with a number of strains of code. There are 3 important options of the Snorkel:
- Labeling knowledge,
- Remodeling knowledge,
- Slicing knowledge.
Though, this text would solely concentrate on the labeling knowledge course of. Let’s strive the Snorkel package deal to automate our labeling course of.
First, we have to set up the package deal.
pip set up snorkel
For tutorial functions, we’d use the YouTube remark dataset from Kaggle by Nipun Arora which is commercially out there to make use of.
import pandas as pddf = pd.read_csv('youtube_dataset.csv')
df.head()
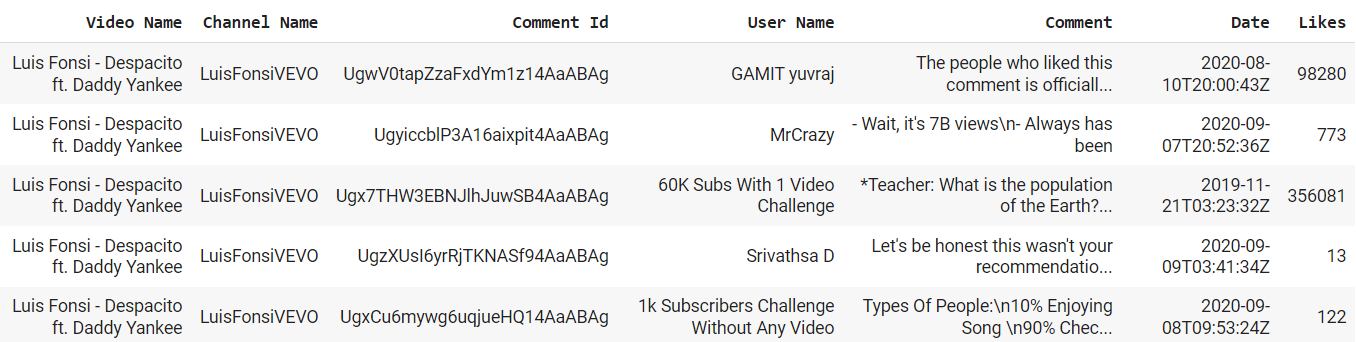
The dataset comprises many fields, together with the YouTube remark knowledge. Let’s say we wish to prepare a YouTube remark spam predictor from the dataset. On this case, we have to label the information with particular necessities — What can we think about Spam?
With Snorkel, we may create a weak supervision perform referred to as the labeling perform — supervised guidelines and heuristics that assign labels to unlabeled coaching knowledge.
For readability functions, let’s deal with Ham as 0, Spam as 1, and Abstain is -1.
ABSTAIN = -1
HAM = 0
SPAM = 1
Additionally, I’d assume that spam comprises “verify” and “checking_out” of their textual content. Let’s construct the labeling perform with the above rule.
from snorkel.labeling import labeling_function@labeling_function()def verify(x):
return SPAM if "verify" in x.textual content.decrease() else ABSTAIN
@labeling_function()def checking_out(x):
return SPAM if "trying out" in x.textual content.decrease() else ABSTAIN
With the perform prepared, we may label the remark knowledge. Nonetheless, we have to change the column identify that we wish to course of as ‘textual content’.
df = df.rename(columns = {'Remark' : 'textual content'})
As we’re additionally utilizing the Pandas DataFrame, we’d use the PandasLFApplier to use the label perform.
from snorkel.labeling import PandasLFApplierlfs = [checking_out, check]applier = PandasLFApplier(lfs=lfs)L_train = applier.apply(df=df)
The results of the applier perform is a label matrix the place the column represents the label perform, and the row represents the information level.
L_train

From the label applier perform, let’s verify how a lot the spam protection for every phrase is.
coverage_checking_out, coverage_check = (L_train != ABSTAIN).imply(axis=0)print(f"trying out protection: {coverage_checking_out * 100:.1f}%")
print(f"verify protection: {coverage_check * 100:.1f}%")

Appears not so many feedback have been Spam in line with our label perform. Let’s use the perform from the snorkel to get a extra detailed abstract.
from snorkel.labeling import LFAnalysisLFAnalysis(L=L_train, lfs=lfs).lf_summary()

Utilizing the LFAnalysis we may get extra detailed details about the labeling course of. Every of the columns represents this data:
- Polarity: Distinctive Label of Label Operate (excluding abstains),
- Protection: LF Label fraction within the dataset,
- Overlaps: Dataset fraction the place this LF and at the very least one different LF label overlap
- Conflicts: Dataset fraction the place this LF and at the very least one different LF label disagree.
That’s the fundamental utilization of the Snorkel for the labeling course of. There’s nonetheless a lot you possibly can do with the packages and study. What essential is that Snorkel would decrease your labeling exercise.
Cleanlab is a python package deal to search out label points and repair them routinely. Inherently, the package deal is totally different than the earlier two packages I’ve talked about as a result of Cleanlab requires our dataset already comprise the label.
Cleanlab goals to scale back handbook work to repair knowledge errors and helps prepare dependable ML fashions with a clear dataset. More often than not, the dangerous label occurs due to mislabeling, and Cleanlab goals to repair that.
Let’s use a dataset instance to make use of Cleanlab. First, we have to set up the package deal.
pip set up cleanlab
We might use the credit score knowledge from the Sklearn perform and set the random seed to get a steady consequence. The information come from OpenML credit score knowledge whose sources have been UCI and commercially out there to make use of.
from sklearn.datasets import fetch_openml
import random
import numpy as npSEED = 123456
np.random.seed(SEED)
random.seed(SEED)knowledge = fetch_openml("credit-g")
X_raw = knowledge.knowledge
y_raw = knowledge.goal
After that, we’d do some knowledge cleansing utilizing a number of Sklearn features.
import pandas as pd
from sklearn.preprocessing import StandardScaler
cat_features = X_raw.select_dtypes("class").columnsX_encoded = pd.get_dummies(X_raw, columns=cat_features, drop_first=True)
num_features = X_raw.select_dtypes("float64").columnsscaler = StandardScaler()
X_scaled = X_encoded.copy()
X_scaled[num_features] = scaler.fit_transform(X_encoded[num_features])y = y_raw.map({"dangerous": 0, "good": 1}) # encode labels as integers
Now we’d attempt to discover a dangerous label from the dataset pattern. In keeping with the cleanlab doc, cleanlab requires a probabilistic prediction from the mannequin for each knowledge level.
Cleanlab can be solely supposed with out-of-sample predicted chances, i.e., on examples held out from the mannequin throughout the coaching. That’s the reason we’d use the Okay-fold cross-validation to get the out-of-sample chances.
Let’s arrange the mannequin first to compute the likelihood. We might use the pattern Logistic Regression.
from sklearn.linear_model import LogisticRegressionclf = LogisticRegression()
Then we’d arrange the Okay-Fold cross-validation.
from sklearn.model_selection import cross_val_predictnum_crossval_folds = 5 pred_probs = cross_val_predict(
clf,
X_scaled,
y,
cv=num_crossval_folds,
methodology="predict_proba",
)
Lastly, we’d use the Cleanlab find_label_issues to search out the dangerous label throughout the dataset based mostly on the out-of-sample chances and the given label.
from cleanlab.filter import find_label_issuesranked_label_issues = find_label_issues(labels=y, pred_probs=pred_probs, return_indices_ranked_by="self_confidence")print(f"Cleanlab discovered {len(ranked_label_issues)} potential label errors.")

If we verify the consequence, we are going to get the place of the dangerous label.
ranked_label_issues

With this data, we have to re-check the information as soon as extra and make sure the high quality is superb.
There are nonetheless many issues you possibly can discover with Cleanlab. If you wish to know extra, please go to the documentation.
Labeling is as important as the information science venture, as many machine studying fashions rely on an accurate label. To assist the information scientist work within the labeling course of, I’m introducing 3 Python packages for the automated label course of. The packages are:
- Compose
- Snorkel
- Cleanlab
I hope it helps!
Go to me on my Social Media to have a extra in-depth dialog or any questions.
In case you are not subscribed as a Medium Member, please think about subscribing by my referral.
