It doesn’t must be that difficult, proper?
With a hands-on MLFlow deployment instance
In case you’re studying this text, it’s doubtless since you’ve heard this buzzword “Kubernetes” (K8s) and also you’re more likely to be within the know-how house. You’ll additionally doubtless have some thought of what containerization (or synonymously referred to as Docker / dockerization) is, so I might skip over the main points of that and soar straight into what K8s is.
In a nutshell, K8s is just a container orchestration framework. What this basically means is that K8s is a system designed to automate the lifecycle of containerized functions — from predictability, scalability to availability.
Why will we even want Kubernetes?
The driving cause behind the rise and want for K8s stems from the rising use of microservices, away from conventional monolithic-type functions. Consequently, containers present the proper host for these particular person microservices as containers handle dependencies, are unbiased, OS-agnostic and ephemeral, amongst different advantages.
Advanced functions which have many elements are sometimes made up of a whole bunch and even 1000’s of microservices. Scaling these microservices up whereas guaranteeing availability is an especially painful course of if we have been to handle all these totally different elements utilizing custom-written packages or scripts, ensuing within the demand for a correct manner of managing these elements.
Cue Kubernetes.
Advantages of Kubernetes
Kubernetes guarantees to unravel the above downside utilizing these following options:
- Excessive Availability — this merely signifies that your software will all the time be up and working, whether or not you have got a brand new replace to roll-out or have some sudden pods crashing.
- Scalability — this ensures excessive efficiency of your software, whether or not you have got a single consumer or a thousand customers flooding your software concurrently.
- Catastrophe Restoration — this ensures that your software will all the time have the newest information and states of your software if one thing unlucky occurs to your bodily or cloud-based infrastructure.
K8s makes use of a Grasp-Slave sort of structure the place a node acts because the Grasp, calling the photographs within the cluster whereas the opposite nodes act as slaves/employee nodes, executing software workloads determined by the Grasp.
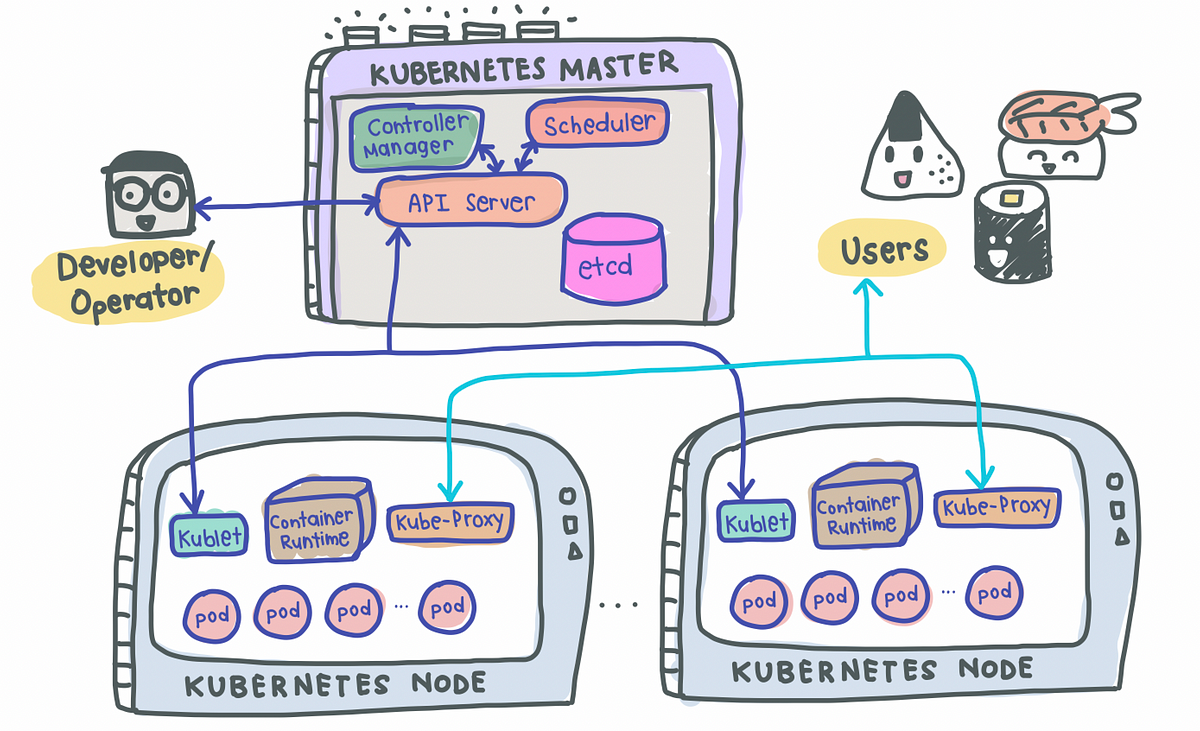
A Easy Kubernetes Structure
A easy K8s setup with a single Grasp node together with 2 employee nodes look one thing like this:
Grasp Node(s)
As its identify suggests, the Grasp node is the boss of the cluster, deciding the cluster state and what every employee node does. As a way to setup a Grasp node, 4 processes are required to run on it:
1. API Server
- Most important entrypoint for customers to work together with the cluster (i.e., cluster gateway); it’s the place requests are despatched once we use
kubectl - Gatekeeper for authentication and request validation, guaranteeing that solely sure customers are capable of execute requests
2. Scheduler
- Determine which node the following pod can be spun up on however does NOT spin up the pod itself (kubelet does this)
3. Controller Supervisor
- Detects cluster state adjustments (e.g., pods dying) and tries to revive the cluster again to its unique state
- For instance, if a pod unexpectedly dies, the Controller Supervisor makes a request to the Scheduler to resolve which node to spin up the brand new pod to exchange the useless pod. Kubelet then spins up the brand new pod.
4. etcd
- Cluster BRAIN!
- Key-Worth retailer of the cluster state
- Any cluster adjustments made can be saved right here
- Software information is NOT saved right here, solely cluster state information. Keep in mind, the grasp node doesn’t do the work, it’s the mind of the cluster. Particularly, etcd shops the cluster state data to ensure that different processes above to know details about the cluster
Slave/Employee Node(s)
Every employee node needs to be put in with 3 node processes with a view to permit Kubernetes to work together with it and to independently spin up pods inside every node. The three processes required are:
1. Kubelet a.ok.a. kubelet
- Interacts with each the node AND the container
- Accountable for taking configuration information and spinning up the pod utilizing the container runtime (see beneath!) put in on the node
2. Container Runtime
- Any container runtime put in (e.g., Docker, containerd)
3. Kube Proxy a.ok.a. kube-proxy
- A community proxy that implements a part of the Kubernetes Service idea (particulars beneath)
- Sits between nodes and forwards the requests intelligently (both intra-node or inter-node forwarding)
Now that we all know K8s work, let’s have a look at among the most frequent elements of Kubernetes that we are going to use to deploy our functions.
1. Pod
- Smallest unit of K8s and often homes an occasion of your software
- Abstraction over a container
- Every pod will get its personal IP handle (public or non-public)
- Ephemeral — new IP handle upon re-creation of pod
2. Service
- As a result of pods are supposed to be ephemeral, Service supplies a approach to “give” pods a everlasting IP handle
- With Service, if the pod dies, its IP handle won’t change upon re-creation
- Acts nearly as a load balancer that routes visitors to pods whereas sustaining a static IP
- Like load balancers, the Service may also be inside or exterior, the place exterior Service is public dealing with (public IP) and inside Service which is supposed for inside functions (non-public IP)
3. Ingress
- With Companies, we could now have an internet software uncovered on a sure port, say 8080 on an IP handle, say 10.104.35. In observe, it’s impractical to entry a public-facing software on
http://10.104.35:8080. - We might thus want an entrypoint with a correct area identify (e.g.,
https://my-domain-name.com, which then forwards the request to the Service (e.g.,http://10.104.35:8080) - In essence, Ingress exposes HTTP and HTTPs routes from outdoors the cluster to providers inside the cluster [1].
- SSL termination (a.ok.a. SSL offloading) — i.e., visitors to Service and its Pods is in plaintext
- That being mentioned, creating an Ingress useful resource alone has no impact. An Ingress-controller can also be required to fulfill an Ingress.
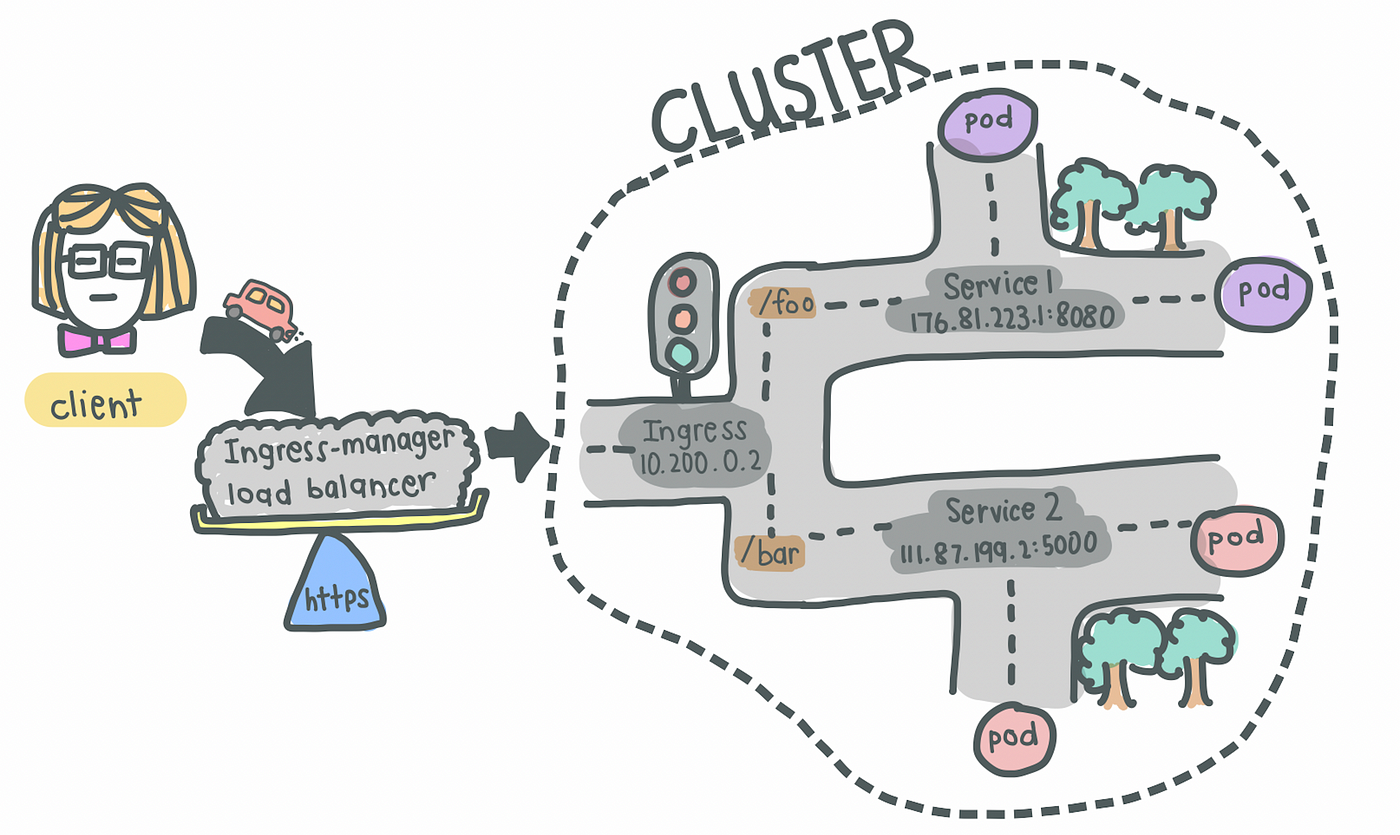
4. Ingress Controller
- Load balances incoming visitors to providers within the cluster
- Additionally manages egress visitors for providers that require communication with exterior providers
What’s the distinction between Ingress and Ingress Controller?
Ingress incorporates the foundations for routing visitors, deciding which Service the incoming request ought to path to inside the cluster.
Ingress Controller is the precise implementation of Ingress, accountable for the Layer-4 or Layer-7 proxy. Examples of Ingress Controller embody Ingress NGINX Controller and Ingress GCE. Every cloud supplier and different third social gathering suppliers could have their very own implementation of the Ingress Controller.
A full listing could be discovered right here.
5. ConfigMap
- As its identify suggests, it’s basically a configuration file that you really want uncovered for customers to switch
6. Secret
- Additionally a configuration file, however for delicate data like passwords
- Base64-encoded
7. Volumes
- Used for persistent information storage
- As pods themselves are ephemeral, volumes are used to persist data in order that present and new pods can reference some state of your software
- Acts nearly like an “exterior arduous drive” in your pods
- Volumes could be saved domestically on the identical node working your pods or remotely (e.g., cloud storage, NFS)
8. Deployment
- Used to outline blueprint for pods
- In observe, we cope with deployments and never pods themselves
- Deployments often have replicas such that when any part of the applying dies, there may be all the time a backup
- Nevertheless, elements like databases can’t be replicated as a result of they’re stateful functions. On this case, we would want the Kubernetes part: StatefulSet. That is arduous and most of the time, databases needs to be hosted outdoors the Kubernetes cluster
Okay, that was in all probability an excessive amount of to digest. Let’s soar into some hands-on observe! Do take a while to re-read the above to get a transparent understanding of every part’s accountability in your complete K8s structure.
As a result of this text focuses on understanding the elements of K8s themselves moderately than learn how to setup a K8s cluster, we are going to merely use minikube to setup our personal native cluster. After which, we are going to deploy a easy however life like software — a MLFlow server.
If you wish to observe together with the supply code, I’ve included them in a GitHub repo right here.
What we can be establishing
A typical software has an internet server with a backend service to persist information — that’s what we are going to goal to duplicate and deploy at this time. To make issues less complicated, we’ll deploy a MLFlow net server that persists information on a Cloud SQL database on Google Cloud Platform (GCP).
The setup is proven beneath:
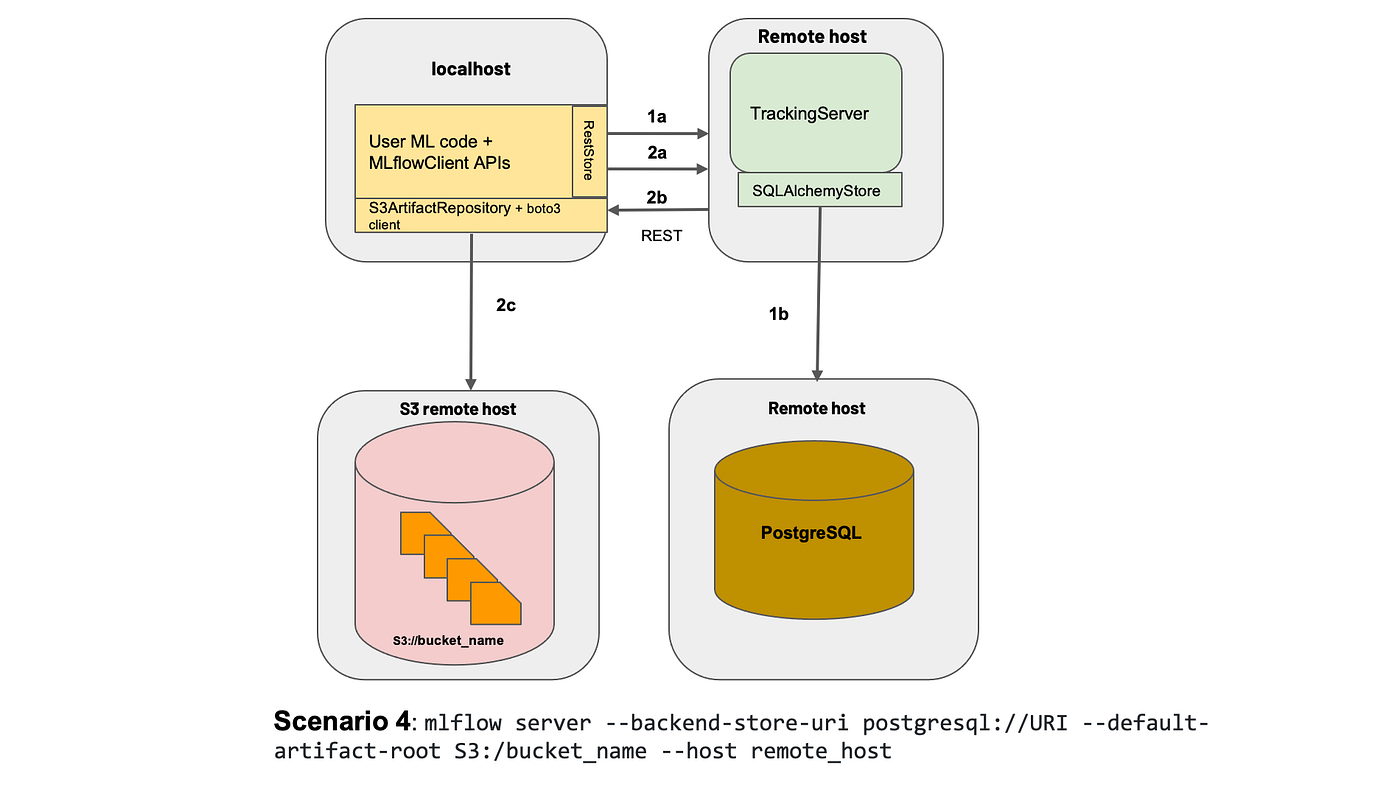
To those that are unaware, MLFlow is principally an experiment monitoring instrument that permits Information Scientists to trace their information science experiments by logging information and mannequin artifacts, with the choice of deploying their fashions utilizing a standardized bundle outlined by MLFlow. For the needs of this text, we are going to deploy the MLFlow monitoring net server with a PostgreSQL backend (hosted on Cloud SQL) and blob retailer (on Google Cloud Storage).
Earlier than that, we’ll have to put in a couple of issues (skip forward if you have already got these put in).
Set up
- Docker
- K8s command line instrument,
kubectl. Our greatest good friend — we use this to work together with our K8s cluster, be it minikube, cloud or a hybrid cluster - Minikube set up information
- Google Cloud SDK
- [Optional] Energy instruments for
kubectl,kubensandkubectx. Observe this to put in.
Organising your native cluster
Begin your cluster with minikube begin. That’s it! You’ve created your individual native Kubernetes cluster with a single command 
You possibly can confirm that the varied elements listed above are created with minikube standing. When you have a number of K8s cluster context, ensure you change to minikube.
# Verify context
kubectx# If not on minikube, change context
kubectx minikube
With our native cluster setup, let’s begin by establishing exterior elements after which transfer on to deploying Kubernetes objects.
1. Create a Dockerfile for MLFlow
We first want a Docker picture of the MLFlow net server that we are going to be deploying. Sadly, MLFlow doesn’t have an official picture that we are able to use on DockerHub, so I’ve created one right here for everybody to make use of. Let’s pull the picture I’ve created from DockerHub.
docker pull davidcjw/example-mlflow:1.0
[Optional] To check if the picture works domestically, merely run:
docker run -p 8080:8080 davidcjw/example-mlflow:1.0
2. Create a Cloud SQL (PostgreSQL) occasion on GCP
This can be used to retailer metadata for the runs logged onto MLFlow monitoring server. As talked about earlier, it’s simpler to create stateful functions outdoors of your Kubernetes cluster.
- Initially, create an account and mission on GCP if you happen to don’t have already got one
- Create an occasion utilizing the CLI with the next command:
gcloud sql cases create <your_instance_name>
--assign-ip
--authorized-networks=<your_ip_address>/32
--database-version=POSTGRES_14
--region=<your_region>
--cpu=2
--memory=3840MiB
--root-password=<your_password>
To search out <your_ip_address>, easy Google “what’s my ip”. For <area>, you’ll be able to specify a area that’s near you. For me, I’ve specified asia-southeast1.
NOTE! These configs are supposed for this instance deployment and never appropriate for manufacturing environments. For manufacturing environments, you'll wish to have minimally multi-zonal availability linked over a Non-public IP.
3. Create a Google Cloud Storage Bucket
This can be used to retailer information and mannequin artefacts logged by the consumer. Create a bucket on GCP and pay attention to the URI for later. For myself, I’ve created one at gs://example-mlflow-artefactsutilizing the next command:
gsutil mb -l <your_region> gs://example-mlflow-artefacts
4. Create ConfigMap and Secret on our native minikubecluster
Now, the thrilling half — deploying onto our Kubernetes clusters the varied elements which can be wanted. Earlier than that, it’s completely important to know a couple of issues about K8s objects.
Kubernetes assets are created utilizing .yaml information with particular codecs (seek advice from the Kubernetes documentation [2] for any useful resource sort you’re creating). They’re used to outline what containerized functions are working on which port and extra importantly, the insurance policies round how these functions behave.
The .yaml information successfully defines our cluster state!
Describing Kubernetes Objects (.yaml information):
- All the time begins with
apiVersion,sortand hasmetadata apiVersion: defines model variety of the Kubernetes API (often v1 if the model you’re utilizing is in steady mode)sort: defines the part sort (e.g. Secret, ConfigMap, Pod, and many others)metadata: information that uniquely identifies an object, together withidentify,UIDandnamespace(extra about this sooner or later!)spec(or specification) /information: particulars particular to the part
4a. Let’s begin with the ConfigMap as these configurations can be wanted once we deploy our MLFlow software utilizing Deployment (NOTE: Order of useful resource creation issues, particularly when there may be configurations or secrets and techniques hooked up to deployments).
# configmap.yaml
apiVersion: v1
sort: ConfigMap
metadata:
identify: mlflow-configmap
information:
# property-like keys; every key maps to a easy worth
DEFAULT_ARTIFACT_ROOT: <your_gs_uri>
DB_NAME: postgres
DB_USERNAME: postgres
DB_HOST: <your_cloud_sql_public_ip>
Professional Tip! All the time have a tab of the official K8s documentation open so you’ll be able to reference the instance
.yamlfile they’ve for every K8s part.
4b. Subsequent, let’s create one for Secrets and techniques. Notice that secrets and techniques must be base64-encoded. It may possibly merely be carried out utilizing:
echo -n "<your_password>" | base64
The one factor that we now have to encode is the password for our PostgreSQL occasion outlined above earlier once we created it on Cloud SQL. Let’s base64-encode that and duplicate the stdout into the .yaml file beneath.
# secrets and techniques.yaml
apiVersion: v1
sort: Secret
metadata:
identify: mlflow-postgresql-credentials
sort: Opaque
information:
postgresql-password: <your_base64_encoded_password>
Apply ConfigMap and Secret utilizing:
kubectl apply -f k8s/configmap.yaml
kubectl apply -f k8s/secrets and techniques.yaml>>> configmap/mlflow-configmap created
>>> secret/mlflow-postgresql-credentials created
Nice! We will now reference the secrets and techniques and configurations we now have created.
5. Create Deployment and Service
5a. Let’s begin with Deployment. To know deployments, let’s take a step again and recall that the primary distinction between Deployment and Pod is that the previous helps to create replicas of the pod that can be deployed. As such, the yaml file for Deployment consists of the configurations for the Pod, in addition to the variety of replicas we wish to create.
If we check out the yaml file beneath, we discover metadata and spec showing twice within the configuration, the primary time on the high of the config file and the second time beneath the “template” key. It is because every thing outlined BELOW the “template” secret is used for the Pod configuration.
Merely put, a Pod part deploys a single occasion of our software whereas a Deployment (often) consists of a couple of deployment of that Pod. If the variety of replicas in our Deployment is 1, it’s basically the identical as a single Pod (however with the choice of scaling up).
# deployment.yaml
apiVersion: apps/v1
sort: Deployment
metadata:
identify: mlflow-tracking-server
labels:
app: mlflow-tracking-server
spec:
replicas: 1
selector:
matchLabels:
app: mlflow-tracking-server-pods
# Pod configurations outlined right here in `template`
template:
metadata:
labels:
app: mlflow-tracking-server-pods
spec:
containers:
- identify: mlflow-tracking-server-pod
picture: davidcjw/example-mlflow:1.0
ports:
- containerPorts: 5000
assets:
limits:
reminiscence: 1Gi
cpu: "2"
requests:
reminiscence: 1Gi
cpu: "1"
imagePullPolicy: All the time
env:
- identify: DB_PASSWORD
valueFrom:
secretKeyRef:
identify: mlflow-postgresql-credentials
key: postgresql-password
- identify: DB_USERNAME
valueFrom:
configMapKeyRef:
identify: mlflow-configmap
key: DB_USERNAME
- identify: DB_HOST
valueFrom:
configMapKeyRef:
identify: mlflow-configmap
key: DB_HOST
- identify: DB_NAME
valueFrom:
configMapKeyRef:
identify: mlflow-configmap
key: DB_NAME
- identify: DEFAULT_ARTIFACT_ROOT
valueFrom:
configMapKeyRef:
identify: mlflow-configmap
key: DEFAULT_ARTIFACT_ROOT
Two necessary inquiries to reply: 1) How do the pod replicas group collectively to be recognized as one by the Deployment? 2) How does the Deployment know which group of pod replicas belong to it?
template > metadata > labels: Not like different elements like ConfigMap and Secret, this metadata keylabelsis obligatory as a result of every pod reproduction created underneath this deployment could have a novel ID (e.g., mlflow-tracking-xyz, mlflow-tracking-abc). To have the ability to collectively establish them as a bunch, labels are used so that every of those pod replicas will obtain these similar set of labels.selector > matchLabels: Used to find out which group of pods are underneath this deployment. Notice that the labels right here must precisely match the labels in (1).
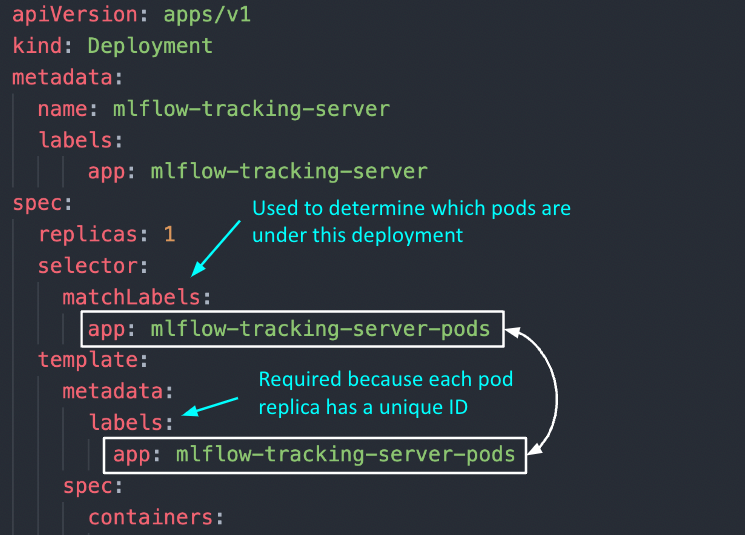
Different key configurations:
replicas: used to find out the variety of pod replicascontainers > picture: the picture that can be utilized by every podcontainers > env: right here is the place we specify the surroundings variables that can be initialized in every pod, referenced from the ConfigMap and Secret we now have created earlier.
5b. Service — As talked about above, Service is used nearly like a load balancer to distribute visitors to every of the pod replicas. As such, listed below are some necessary issues to notice about Service.
selector: This key-value pair ought to match thetemplate > metadata > labelsspecified earlier in Deployment, in order that Service is aware of which set of pods to route the request to.sort: This defaults toClusterIP, which is the inner IP handle of the cluster (an inventory of different different service sorts could be discovered right here). For our use case, we are going to useNodePortto show our net software on a port of our node’s IP handle. Do notice that the values forNodePortcan solely be between 30000–32767.targetPort: This refers back to the port that your pod is exposing the applying on, which is laid out in Deployment.
apiVersion: v1
sort: Service
metadata:
labels:
app: mlflow-tracking-server
identify: mlflow-tracking-server
spec:
sort: NodePort
selector:
app: mlflow-tracking-server-pods
ports:
- port: 5000
protocol: TCP
targetPort: 5000
nodePort: 30001
5c. Placing it collectively
You possibly can in reality put a number of .yaml configurations in a single file — particularly the Deployment and Service configurations, since we can be making use of these adjustments collectively. To take action, merely use a --- to demarcate these two configs in a single file:
# deployment.yaml
apiVersion: v1
sort: Deployment
...
---
apiVersion: v1
sort: Service
...
Lastly, we apply these adjustments utilizing kubectl apply -f k8s/deployment.yaml. Congrats! Now you can entry your MLFlow server at <node_IP>:<nodePort>. Right here’s learn how to discover out what your node_IP is:
kubectl get node -o broad# or equivalently:
minikube ip
In case you’re a Apple Silicon or Home windows consumer…
In case you’re like me utilizing the Docker driver on Darwin (or Home windows, WSL), the Node IP won’t be instantly reachable utilizing the above methodology. Full steps 4 and 5 listed on this hyperlink to entry your software.
Cleansing Up
Lastly, we’re carried out with our check software and cleansing up is so simple as minikube delete --all.
Thanks for studying and hope this helps you in your understanding of Kubernetes. Please let me know if you happen to spot any errors or if you need to know extra in one other article!
[1] What’s Ingress?
[2] Kubernetes Documentation
[3] Nana’s Kubernetes Crash Course
[4] Accessing apps (Minikube)

{kind=link}