
Information science is not simply Pandas, NumPy, and Scikit-learn anymore

Motivation
With 2023 simply in, it’s time to uncover new knowledge science and machine studying developments. Whereas the previous stuff remains to be important, realizing Pandas, NumPy, Matplotlib, and Scikit-learn will not simply be sufficient anymore.
Final yr’s model of this submit was extra about traditional ML, together with libraries like CatBoost, LightGBM, Optuna, or UMAP.
In 2022, I noticed many extra “My pretty connections, I’m completely happy to announce I’m an MLOps engineer” posts than in 2021. Correspondingly, there was way more content material on MLOps, and there was an enormous improve within the recognition of MLOps instruments.
So, this yr’s article is on the six rising stars within the MLOps ecosystem; instruments targeted on producing best-performing fashions in essentially the most environment friendly means attainable after which throwing them into manufacturing.
1. BentoML
You’re most likely bored with listening to, “Machine studying fashions do not dwell in Jupyter Notebooks”. If you happen to aren’t, I’ll go forward and say it as soon as once more:
Machine studying fashions don’t dwell inside Jupyter, gathering rust.
They dwell in manufacturing, doing what they’re truly purported to do — predicting new knowledge.
Probably the greatest libraries I discovered final yr to deploy fashions is BentoML. BentoML is an all-in-one framework to keep up, package deal and deploy fashions of any framework to any cloud supplier as API providers.
It helps saving/loading fashions in a unified format (versioned and tagged), enabling you to construct an organized mannequin registry.
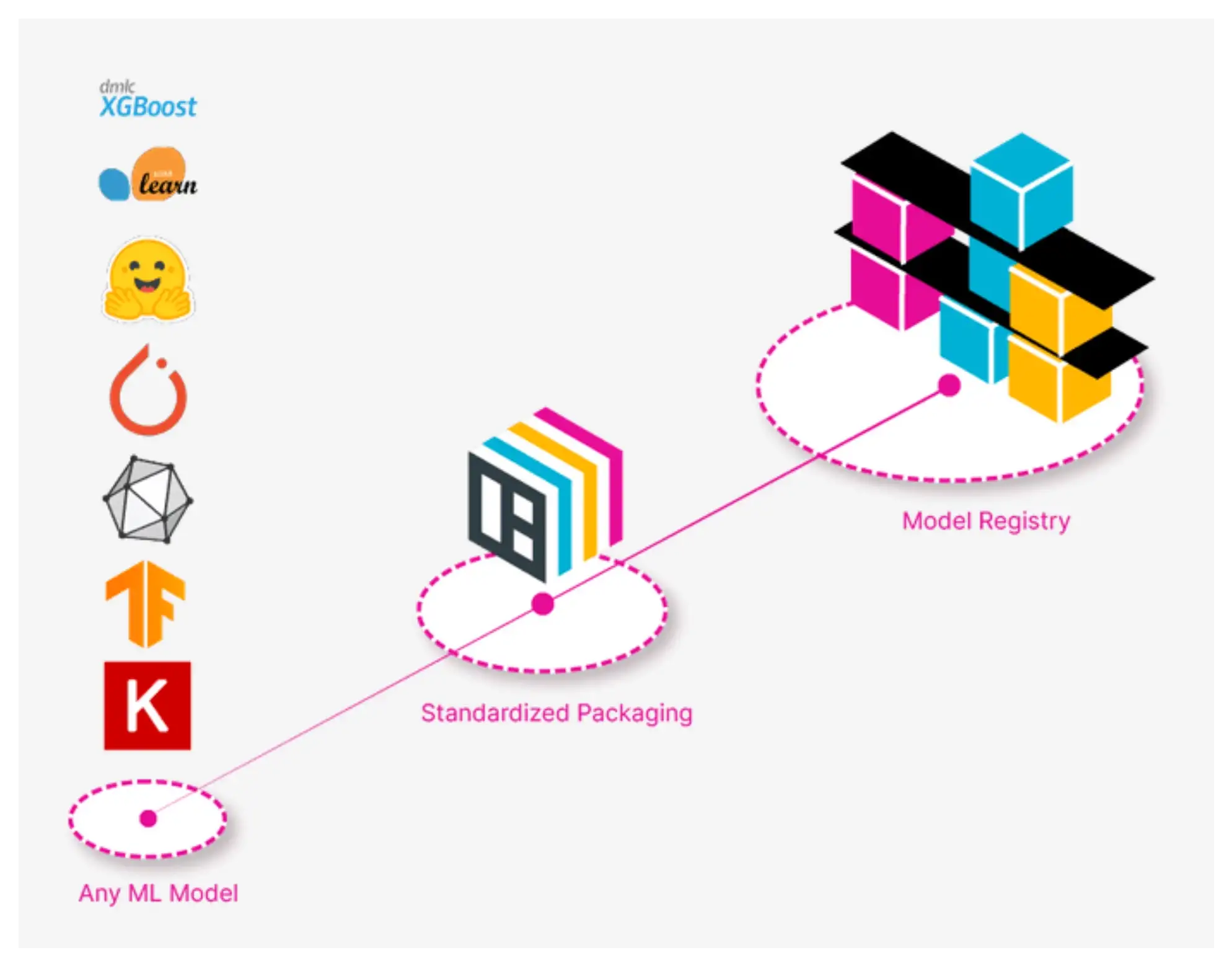
From there, you’ll be able to construct a Docker picture of your greatest mannequin with a single command and serve it regionally:
$ bentoml containerize my_classifier:newest
$ docker run -it --rm -p 3000:3000 my_classifier:6otbsmxzq6lwbgxi serve --production
Or deploy it to any cloud supplier with just a few instructions with out leaving the CLI. Right here is an instance for AWS Sagemaker:
$ pip set up bentoctl terraform
$ bentoctl operator set up aws-sagemaker
$ export AWS_ACCESS_KEY_ID=REPLACE_WITH_YOUR_ACCESS_KEY
$ export AWS_SECRET_ACCESS_KEY=REPLACE_WITH_YOUR_SECRET_KEY
$ bentoctl init
$ bentoctl construct -b model_name:newest -f deployment_config.yaml
$ terraform init
$ terraform apply -var-file=bentoctl.tfvars -auto-approve
Here’s a step-by-step tutorial the place I present methods to deploy an XGBoost mannequin to AWS Lambda:
Stats and hyperlinks:
2. MLFlow
Earlier than deploying your greatest mannequin into manufacturing, it’s essential to produce it by way of experimentation. Sometimes, this will take dozens and even a whole bunch of iterations.
Because the variety of iterations grows, it will get more durable and more durable to maintain monitor of what configurations you have already tried and which of the previous experiments look promising.
That can assist you with the method, you want a dependable framework to maintain monitor of code, knowledge, fashions, hyperparameters, and metrics concurrently.
Constructing that framework manually (or utilizing Excel like a caveman) is the worst thought on this planet, as there are such a lot of excellent Python libraries for the job.
A type of is MLFlow, my private favourite. By including the next line of code to a script that trains a scikit-learn mannequin, MLFlow will seize every part — the mannequin itself, its hyperparameters, and any metric you calculate utilizing sklearn.metrics capabilities:
mlflow.sklearn.autolog()
When you end tinkering round, you run mlflow ui on the terminal, and it brings up an experiments dashboard with controls to type and visualize your experiments:
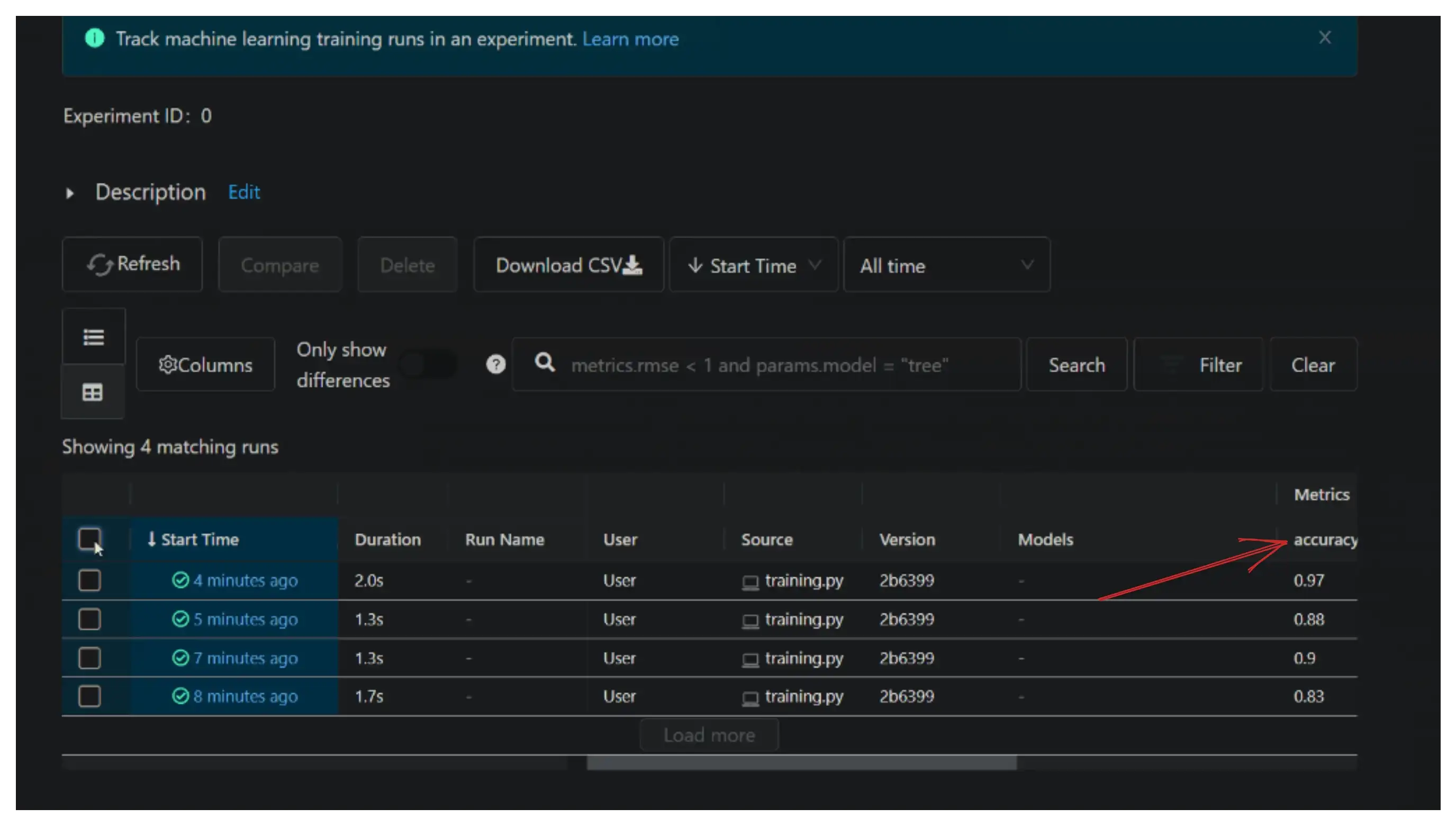
MLFlow has a mlflow.framework.autolog() function for extra frameworks than you’ll be able to title. It’s so easy and helpful that you just can’t not use it.
Right here is my tutorial on the framework, discussing its options and integration with the remainder of the instruments within the knowledge ecosystem.
Stats and hyperlinks:
3. DVC
In a sentence, DVC is Git for knowledge.
DVC (Information Model Management) is changing into a go-to knowledge and mannequin versioning library. It might probably:
- Monitor gigabyte-sized datasets or fashions like Git tracks light-weight scripts.
- Create branches of the primary code base for protected experimentation with out duplicating the massive recordsdata.
Once you monitor a big file or listing with dvc add listing, a light-weight listing.dvc metadata file is created. Then, DVC manages these mild recordsdata as placeholders for the unique, heavy-weight recordsdata.
DVC lifts the weights, whereas Git handles the small stuff like your scripts. Collectively, they make an ideal duo.
One other promoting level of DVC is sensible workflow pipelines. A typical machine studying workflow entails steps like amassing knowledge, cleansing it, function engineering, and coaching a mannequin.
DVC can create a wise pipeline from all these steps so you’ll be able to run all of them with two key phrases — dvc repro.
What is the sensible half? DVC solely executes modified steps of the pipeline, saving you hours of time and computing assets.
Add MLFlow to your coaching scripts, monitor the mannequin artifacts with DVC, and you’ve got the right trio (Git, DVC, MLFlow).
Take a look at my beginner-friendly tutorial on DVC to get began:
Stats and hyperlinks:
4. Weights & Biases
One other totally open-source experiment monitoring framework is Weights & Biases (wandb.ai). The one distinction? It’s offered by an organization with over $200M in funding and a consumer base that accommodates OpenAI, NVIDIA, Lyft, BMW, Samsung, and so forth.
Their fundamental promoting factors are:
- Glorious integration with the remainder of the ML ecosystem, similar to MLFlow
- Essentially the most lovely UI for monitoring and evaluating experiments (personally)
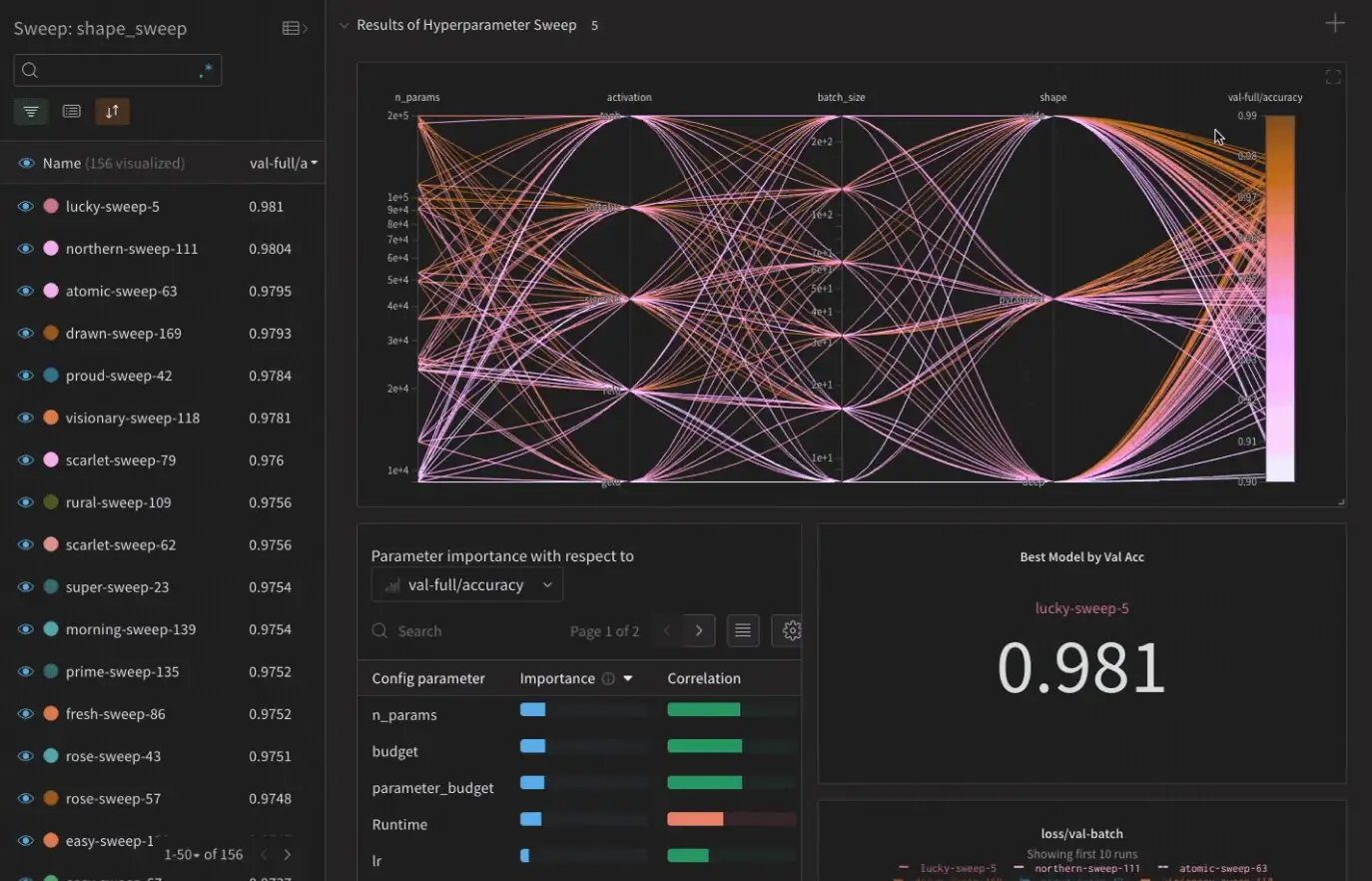
- Collaborative stories and dashboards
- Hyperparameter optimization (not attainable in MLFlow)
And one of the best half is, all of the above options can be found straight via Jupyter. This implies you do not have to ditch your favourite IDE and transfer into scripts simply to trace experiments.
So, your excellent trio may truly be Git, DVC, and Weights & Biases.
Stats and hyperlinks:
5. NannyML
Deploying fashions is barely a part of the story. To keep up a profitable ML-powered product, it’s essential to persistently monitor their efficiency.
The issue with monitoring is that you just will not have good, fats, pink errors when fashions fail. Their predictions could change into worse and worse as time passes, resulting in a phenomenon referred to as a silent mannequin failure.
For instance, you deployed a mannequin that detects Nike garments from photographs. Style is fast-changing, so Nike continuously improves its designs.
Since your mannequin coaching did not embrace the brand new designs, it begins to overlook Nike garments from photographs increasingly more. You will not obtain errors, however your mannequin will quickly be ineffective.
NannyML helps resolve this precise drawback. Utilizing a novel Confidence-Primarily based Efficiency Estimation algorithm they developed and some different strong statistical checks, they’ll detect efficiency drops or silent mannequin failures in manufacturing.
NannyML additionally options sensible alerting so you’ll be able to all the time keep in tune with what’s occurring in your manufacturing setting.
Here’s a hands-on tutorial to get you began:
Stats and hyperlinks:
6. Poetry
You have most likely heard Python programmers whine about pip and its dependency points a thousand instances already, and I used to be a type of whiners till I noticed Poetry.
Poetry is a game-changing open-source Python packaging and dependency administration framework. In its easiest use case, Poetry can detect dependency conflicts BEFORE you put in libraries with the intention to keep away from dependency hell fully.
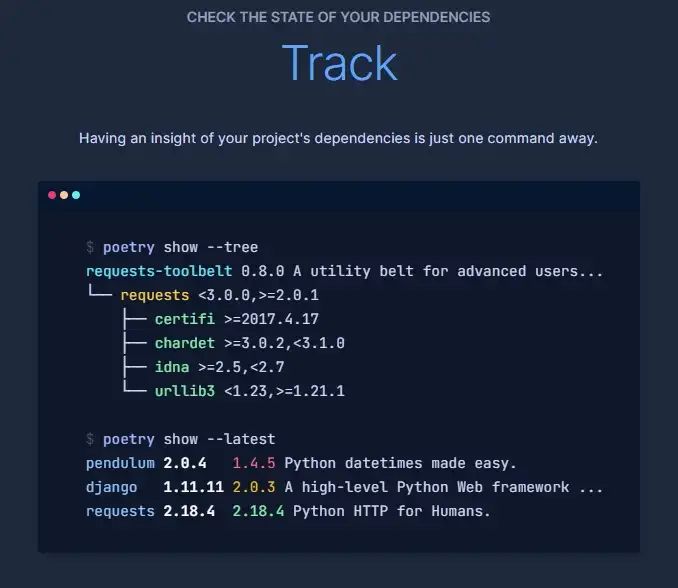
You can even configure your Python initiatives as packages with pyproject.toml recordsdata, and Poetry will care for digital environments, constructing and publishing the repo to PyPI with easy instructions.

Here’s a complete Actual Python tutorial on Poetry:
Stats and hyperlinks:
Conclusion
The sphere of information science is consistently evolving, and new instruments and libraries are being developed at a blazing tempo. The stress to maintain up is more durable than ever. On this submit, I did my greatest to slender your focus to 1 space of machine studying that is promised to skyrocket in 2023. Thanks for studying!
Do not miss out on my newest’ hits’:

{kind=link}