Deep Studying
Understanding CNN from the bottom up
Desk of Contents· Absolutely Linked Layer and Activation Operate· Convolution and Pooling Layer· Normalization Layer
∘ Native Response Normalization
∘ Batch Normalization· 5 Most Nicely-Recognized CNN Architectures Visualized
∘ LeNet-5
∘ AlexNet
∘ VGG-16
∘ Inception-v1
∘ ResNet-50· Wrapping Up
The introduction of LeNet in 1990 by Yann LeCun sparks the potential of deep neural networks in observe. Nonetheless, restricted computation functionality and reminiscence capability made the algorithm troublesome to implement till about 2010.
Whereas LeNet is the one which begins the period of Convolutional Neural Networks (CNN), AlexNet — invented by Alex Krizhevsky and others in 2012 — is the one which begins the period of CNN used for ImageNet classification.
AlexNet is the primary proof that CNN can carry out properly on this traditionally complicated ImageNet dataset and it performs so properly that leads society into a contest of growing CNNs: from VGG, Inception, ResNet, to EfficientNet.
Most of those architectures comply with the identical recipe: combos of convolution layers and pooling layers adopted by totally related layers, with some layers having an activation operate and/or normalization step. You’ll be taught all these mumbo jumbos first, so all architectures might be understood simply afterward.
Be aware: If you would like the editable model of the architectures defined on this story, please go to my gumroad web page beneath.
With this template, you may need to edit current architectures to your personal shows, schooling, or analysis functions, otherwise you may need to use our lovely legend to construct different wonderful deep studying architectures however don’t need to begin from scratch. It’s FREE (or pay what you need)!
Let’s return in time. In 1958, Frank Rosenblatt launched the primary perceptron, an digital system that was constructed by organic rules and confirmed a capability to be taught. The perceptron was meant to be a machine, relatively than a program, and one in every of its first implementations was designed for picture recognition.
The machine extremely resembles a contemporary perceptron. Within the trendy sense, the perceptron is an algorithm for studying a binary classifier as proven beneath. Perceptron offers a linear choice boundary between two lessons using a step operate that is determined by the weighted sum of information.
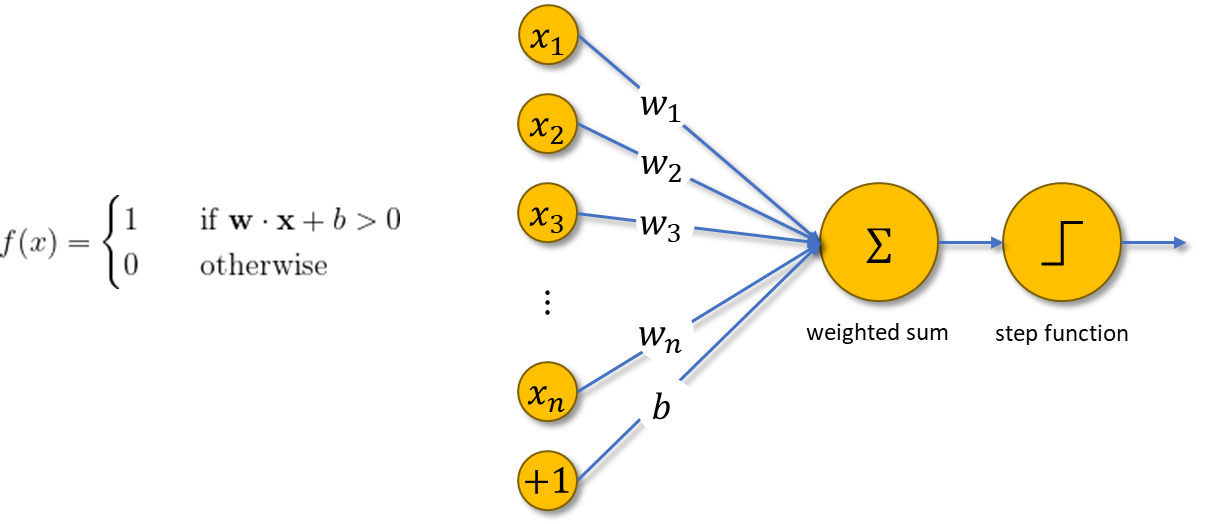
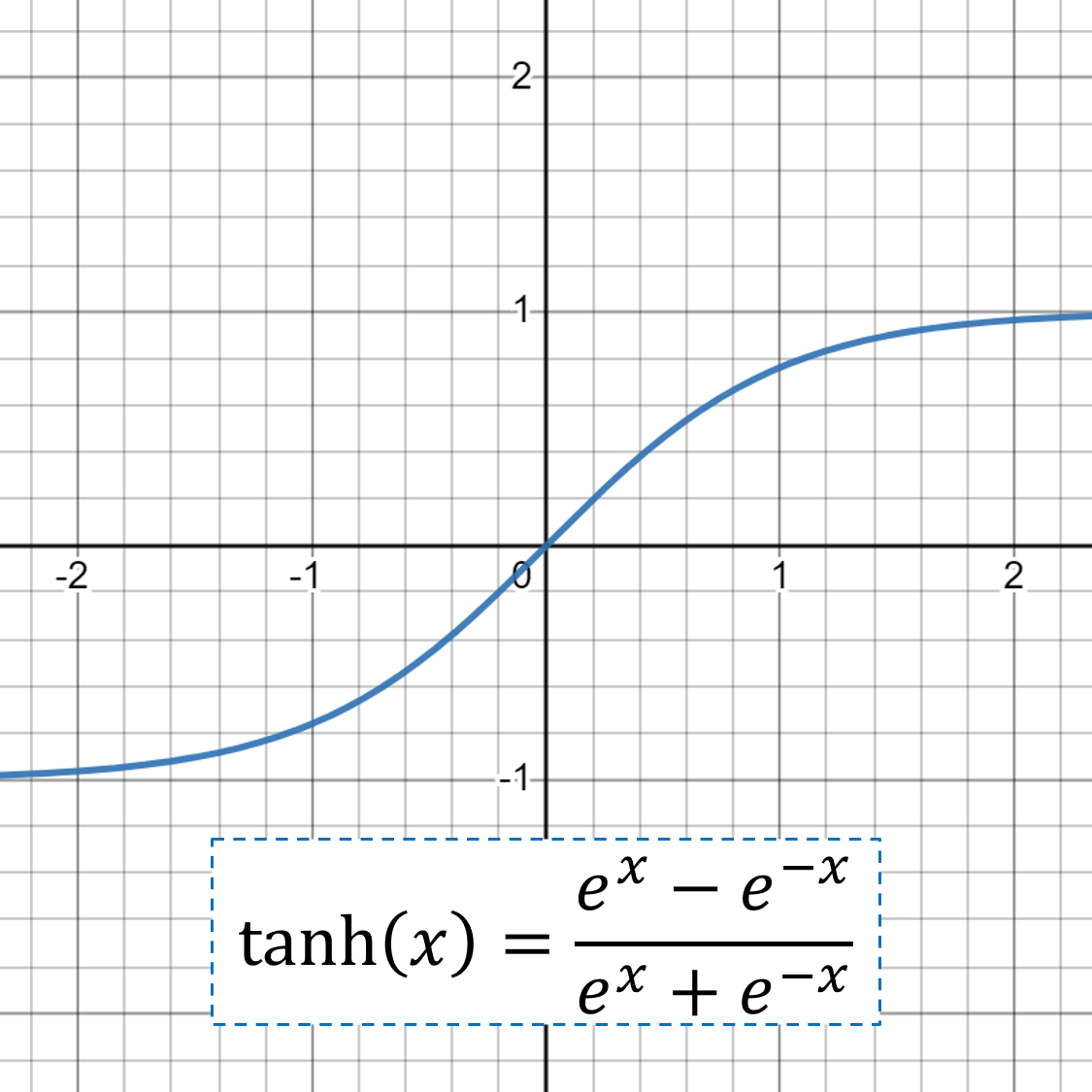
The step operate in a perceptron is an instance of an activation operate; it prompts whether or not the state of the perceptron is on (1) or off (0). These days, there are numerous sorts of activation capabilities, most of which can be utilized to introduce nonlinearities to perceptrons. Some widespread activation capabilities moreover the step operate are:


The perceptron is known as the logistic regression mannequin if the activation operate is sigmoid.
There’s additionally one other activation operate value mentioning that’s used when coping with multiclass classification duties: softmax. Contemplate a activity with Okay lessons, then softmax is expressed by

Softmax offers the expected likelihood that class i will likely be chosen by the mannequin. The mannequin with a softmax activation operate will choose the category with the best likelihood as the ultimate prediction.
Contemplate a perceptron with an arbitrary activation operate g. You possibly can stack as many perceptrons as you want on high of one another right into a single layer, and you may join the outputs of a layer to a different layer. The result’s what we name a Multi-Layer Perceptron (MLP).

In a vectorized formulation, MLP with L layers is expressed as follows.

MLP can be known as a dense neural community because it resembles how the mind works. Every unit circle within the final picture above is known as a neuron. On the earth of neural networks, MLP layers are additionally known as totally related layers since each neuron in a layer is related to all neurons within the subsequent layer.
Absolutely related layers are helpful when it’s troublesome to discover a significant option to extract options from knowledge, e.g. tabular knowledge. In relation to picture knowledge, CNN is arguably essentially the most well-known household of neural networks to have. For picture knowledge, neural networks use the RGB channel of a picture to work with.

CNN permits the neural community to reuse parameters throughout totally different spatial places of a picture. Varied decisions of filters (additionally known as kernels) may obtain totally different picture operations: identification, edge detection, blur, sharpening, and many others. The concept of CNN is to find some fascinating options of the picture by introducing random matrices as a convolution operator.
After the picture has been convolved with kernels, you’re left with what’s generally known as a characteristic map. You possibly can convolve your characteristic maps time and again to extract options, nonetheless, this seems to be extremely computationally costly. As an alternative, you possibly can scale back the dimensions of your characteristic maps utilizing the pooling layer.
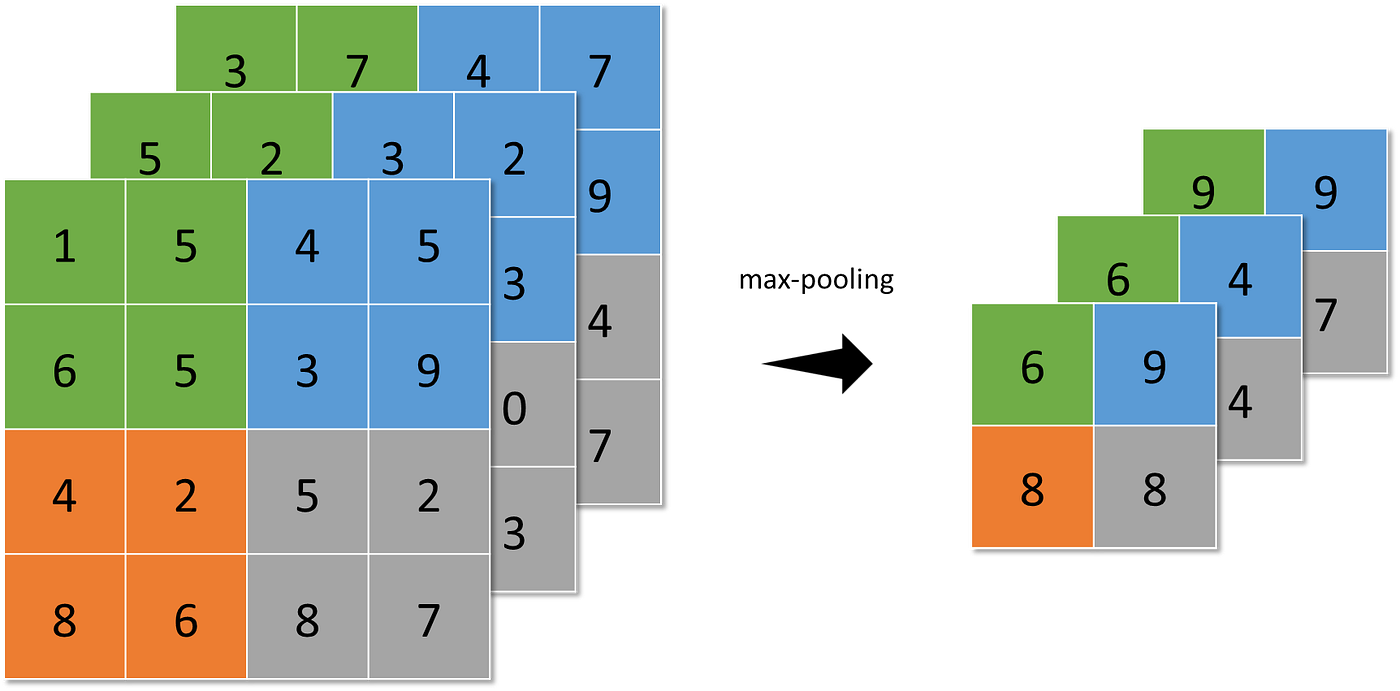
The pooling layer represents small areas of a characteristic map by a single pixel. Some totally different methods might be thought-about:
- max-pooling (the best worth is chosen from the N×N patches of the characteristic maps),
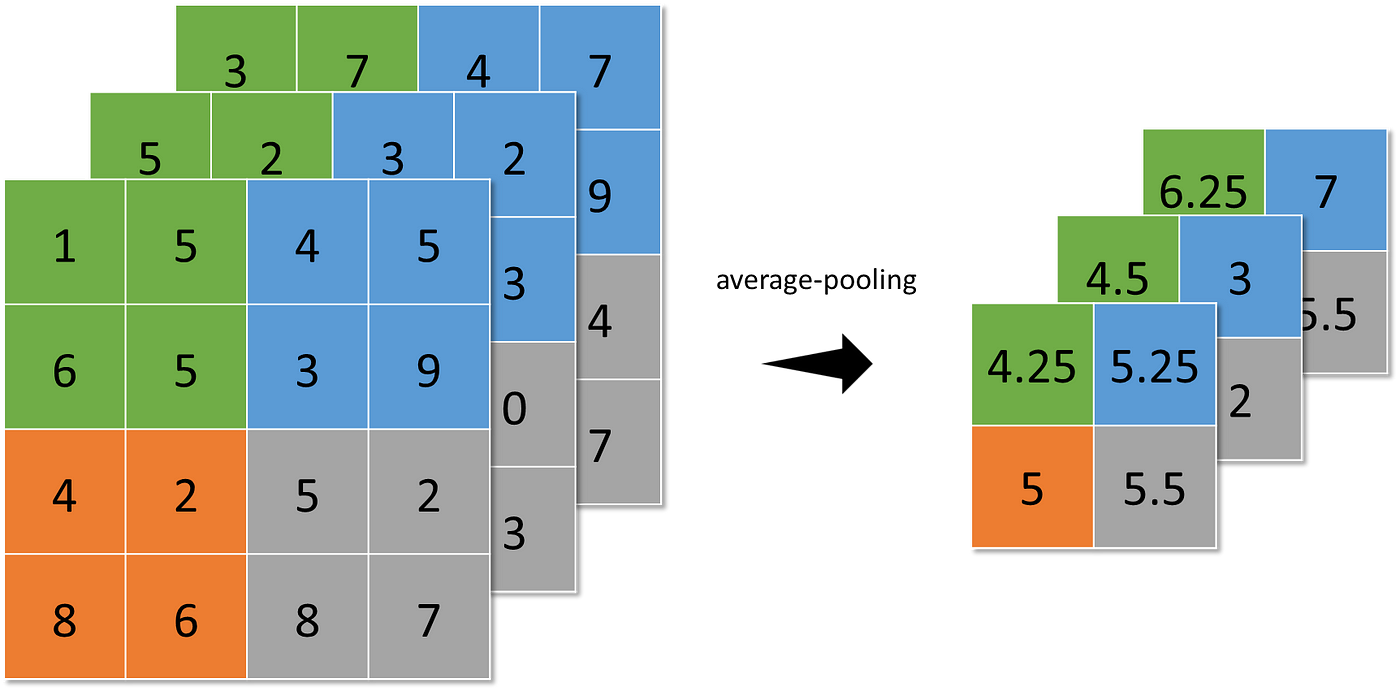
- average-pooling (sums up over N×N patches of the characteristic maps from the earlier layer and selects the common worth), and
- global-average-pooling (just like average-pooling however as an alternative of utilizing N×N patches of the characteristic maps, it makes use of all characteristic maps space without delay).
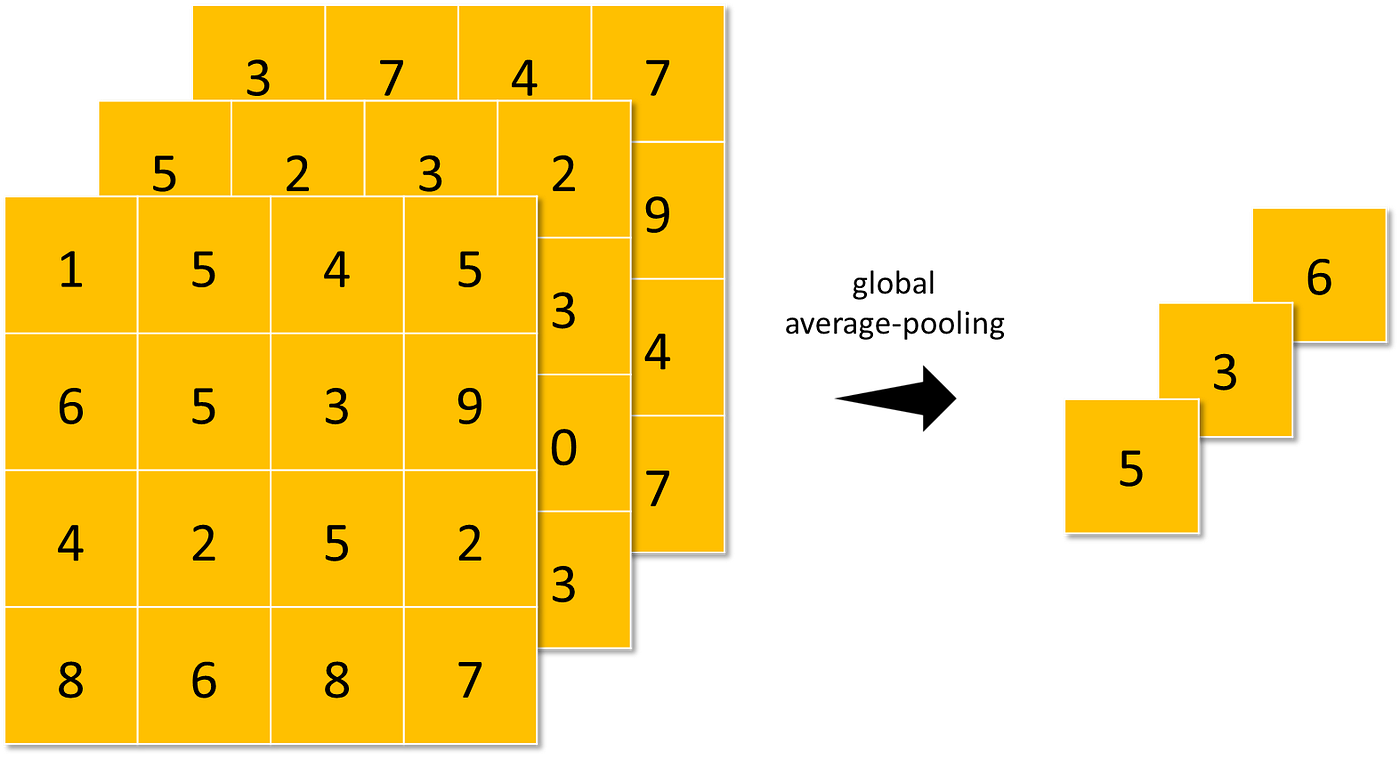
Pooling makes the neural community invariant to small transformations, distortions, and translations within the enter picture. A small distortion within the enter is not going to change the end result of pooling since you are taking the utmost/common worth in an area neighborhood.
Native Response Normalization
In his AlexNet paper, Alex Krizhevsky and others launched Native Response Normalization (LRN), a scheme to help the generalization functionality of AlexNet.
LRN implements the concept of lateral inhibition, an idea in neurobiology that refers back to the phenomenon of an excited neuron inhibiting its neighbors: this results in a peak within the type of an area most, creating distinction in that space and growing sensory notion.
Given aᵢ the exercise of a neuron computed by making use of kernel i after which making use of the activation operate, the response-normalized exercise bᵢ is given by the expression
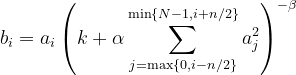
the place the sum runs over n “adjoining” kernel maps on the identical spatial place, and N is the entire variety of kernels within the layer. The constants ok, n, α, and β are hyperparameters.
To be concrete, let (ok, n, α, β) = (0, 2, 1, 1). After being utilized to LRN, we are going to calculate the worth of the highest left pixel (coloured lightest inexperienced beneath).

Right here’s the calculation.

Batch Normalization
One other breakthrough within the optimization of deep neural networks is Batch Normalization (BN). It addresses the issue known as inner covariate shift:
The modifications in parameters of the earlier neural community layers change the enter/covariate of the present layer. This modification might be dramatic as it might shift the distribution of inputs. And a layer is barely helpful if its enter change.
Let m be the batch dimension throughout coaching. For each batch, BN formally follows the steps:

the place

This manner, BN helps speed up deep neural community coaching. The community converges quicker and exhibits higher regularization throughout coaching, which has an influence on the general accuracy.
You’ve realized the next:
- Convolution Layer
- Pooling Layer
- Normalization Layer
- Absolutely Linked Layer
- Activation Operate
Now, we’re able to introduce and visualize 5 CNN architectures:
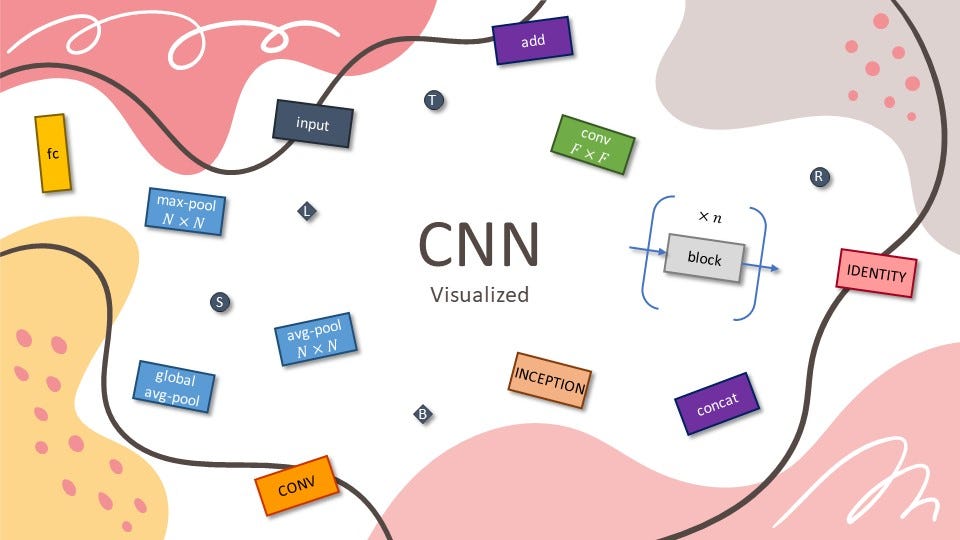
They are going to be constructed on high of the layers and capabilities you realized. So, to simplify issues, we are going to lower out some info such because the variety of filters, stride, padding, and dropout for regularization. You’ll use the next legend to help you.

Be aware: This a part of the story is essentially impressed by the next story by Raimi Karim. Ensure you test it out!
Let’s start, lets?
This begins all of it. Excluding pooling, LeNet-5 consists of 5 layers:
- 2 convolution layers with kernel dimension 5×5, adopted by
- 3 totally related layers.
Every convolution layer is adopted by a 2×2 average-pooling, and each layer has tanh activation operate besides the final (which has softmax).

LeNet-5 has 60,000 parameters. The community is educated on greyscale 32×32 digit pictures and tries to acknowledge them as one of many ten digits (0 to 9).
AlexNet introduces the ReLU activation operate and LRN into the combo. ReLU turns into so widespread that the majority CNN architectures developed after AlexNet used ReLU of their hidden layers, abandoning the usage of tanh activation operate in LeNet-5.

The community consists of 8 layers:
- 5 convolution layers with non-increasing kernel sizes, adopted by
- 3 totally related layers.
The final layer makes use of the softmax activation operate, and all others use ReLU. LRN is utilized on the primary and second convolution layers after making use of ReLU. The primary, second, and fifth convolution layers are adopted by a 3×3 max pooling.
With the development of recent {hardware}, AlexNet might be educated with a whopping 60 million parameters and turns into the winner of the ImageNet competitors in 2012. ImageNet has turn into a benchmark dataset in growing CNN architectures and a subset of it (ILSVRC) consists of varied pictures with 1000 lessons. Default AlexNet accepts coloured pictures with dimensions 224×224.
Researchers investigated the impact of the CNN depth on its accuracy within the large-scale picture recognition setting. By pushing the depth to 11–19 layers, VGG households are born: VGG-11, VGG-13, VGG-16, and VGG-19. A model of VGG-11 with LRN was additionally investigated however LRN doesn’t enhance the efficiency. Therefore, all different VGGs are carried out with out LRN.

This story focuses on VGG-16, a deep CNN structure with, properly, 16 layers:
- 13 convolution layers with kernel dimension 3×3, adopted by
- 3 totally related layers.
VGG-16 is without doubt one of the largest networks that has 138 million parameters. Similar to AlexNet, the final layer is provided with a softmax activation operate and all others are geared up with ReLU. The 2nd, 4th, seventh, tenth, and thirteenth convolution layers are adopted by a 2×2 max-pooling. Default VGG-16 accepts coloured pictures with dimensions 224×224 and outputs one of many 1000 lessons.
Going deeper has a caveat: exploding/vanishing gradients:
- The exploding gradient is an issue when massive error gradients accumulate and end in unstable weight updates throughout coaching.
- The vanishing gradient is an issue when the partial by-product of the loss operate approaches a price near zero and the community couldn’t prepare.

Inception-v1 tackles this challenge by including two auxiliary classifiers related to intermediate layers, with the hope to extend the gradient sign that will get propagated again. Throughout coaching, their loss will get added to the entire lack of the community with a 0.3 low cost weight. At inference time, these auxiliary networks are discarded.
Inception-v1 introduces the inception module, 4 collection of 1 or two convolution and max-pool layers stacked in parallel and concatenated on the finish. The inception module goals to approximate an optimum native sparse construction in a CNN by permitting the usage of a number of forms of kernel sizes, as an alternative of being restricted to single kernel dimension.
Inception-v1 has fewer parameters than AlexNet and VGG-16, a mere 7 million, regardless that it consists of twenty-two layers:
- 3 convolution layers with 7×7, 1×1, and three×3 kernel sizes, adopted by
- 18 layers that include 9 inception modules the place every has 2 layers of convolution/max-pooling, adopted by
- 1 totally related layer.
The final layer of the principle classifier and the 2 auxiliary classifiers are geared up with a softmax activation operate and all others are geared up with ReLU. The first and third convolution layers, additionally the 2nd and seventh inception modules are adopted by a 3×3 max-pooling. The final inception module is adopted by a 7×7 average-pooling. LRN is utilized after the first max-pooling and the third convolution layer.
Auxiliary classifiers are branched out after the third and sixth inception modules, every begins with a 5×5 average-pooling and is then adopted by 3 layers:
- 1 convolution layer with 1×1 kernel dimension, and
- 2 totally related layers.
Default Inception-v1 accepts coloured pictures with dimensions 224×224 and outputs one of many 1000 lessons.
When deeper networks can begin converging, a degradation drawback has been uncovered: with the community depth growing, accuracy will get saturated after which degrades quickly.
Unexpectedly, such degradation isn’t brought on by overfitting (often indicated by decrease coaching error and better testing error) since including extra layers to a suitably deep community results in greater coaching error.

The degradation drawback is addressed by introducing bottleneck residual blocks. There are 2 sorts of residual blocks:
- Identification block: consists of three convolution layers with 1×1, 3×3, and 1×1 kernel sizes, all of that are geared up with BN. ReLU activation operate is utilized to the primary two layers, whereas the enter of the identification block is added to the final layer earlier than making use of ReLU.
- Convolution block: identical as identification block, however the enter of the convolution block is first handed by a convolution layer with 1×1 kernel dimension and BN earlier than being added to the final convolution layer of the principle collection.
Discover that each residual blocks have 3 layers. In complete, ResNet-50 has 26 million parameters and 50 layers:
- 1 convolution layer with BN then ReLU is utilized, adopted by
- 9 layers that include 1 convolution block and a pair of identification blocks, adopted by
- 12 layers that include 1 convolution block and three identification blocks, adopted by
- 18 layers that include 1 convolution block and 5 identification blocks, adopted by
- 9 layers that include 1 convolution block and a pair of identification blocks, adopted by
- 1 totally related layer with softmax.
The primary convolution layer is adopted by a 3×3 max-pooling and the final identification block is adopted by a global-average-pooling. Default ResNet-50 accepts coloured pictures with dimensions 224×224 and outputs one of many 1000 lessons.
Right here’s a abstract of all architectures.


{kind=link}