Actual-time information processing is a foundational side of working fashionable technology-oriented companies. Prospects need faster outcomes than ever and can defect on the slightest alternative of getting quicker outcomes. Therefore organizations today are in a steady hunt to shave off milliseconds from their responses.
Actual-time processing is taking up most features that had been earlier dealt with utilizing batch processing. Actual-time processing requires executing enterprise logic on an incoming stream of knowledge. That is in stark distinction to the normal means of storing the info in a database after which executing analytical queries. Such purposes cannot afford the delay concerned in loading the info first to a conventional database after which executing the queries. This units the stage for streaming databases. Streaming databases are information shops that may obtain high-velocity information and course of them on the go, with out a conventional database within the combine. They don’t seem to be drop-in replacements for the normal database however are good at dealing with high-speed information. This text will cowl the 4 key design ideas and ensures of streaming databases.
Understanding Streaming Databases
Streaming databases are databases that may gather and course of an incoming sequence of knowledge factors (i.e., an information stream) in real-time. A conventional database shops the info and expects the consumer to execute queries to fetch outcomes primarily based on the most recent information. Within the fashionable world, the place real-time processing is a key criterion, ready for queries isn’t an choice. As an alternative, the queries should run constantly and all the time return the most recent information. Streaming databases facilitate this.
Within the case of streaming databases, queries should not executed however fairly registered as a result of the execution by no means will get accomplished. They run for an infinite period of time, reacting to newer information that is available in. Purposes may question again in time to get an thought of how information modified over time.
In comparison with a conventional database, a streaming database does all of the work on the time of writing. Conducting this comes with numerous challenges. For one, there may be minimal sturdiness and correctness that one expects from a conventional database. Sustaining that form of sturdiness and correctness requires difficult designs when the info is all the time in movement. Then there may be the problem of how one can allow the customers to question the info in movement. SQL has been the usual for a very long time now for all querying necessities. It’s pure that streaming databases additionally assist SQL, however implementing constructs like windowing, aggregation, and many others are advanced when the info is all the time shifting.
A persistent question is a question that operates on shifting information. They run indefinitely and preserve churning out output rows. Persistent queries pose distinctive challenges in updating the logic. The important thing query is in regards to the habits when changing the question with an improved one — Does it function on all the info that arrived until then or solely on the following set of knowledge? The identify of the primary mode of operation is backfill and the latter is exactly-once processing. To implement exactly-once processing, the execution engine will need to have an area retailer. At occasions, the queries can feed to different information streams. Such an operation is named cascading mode.
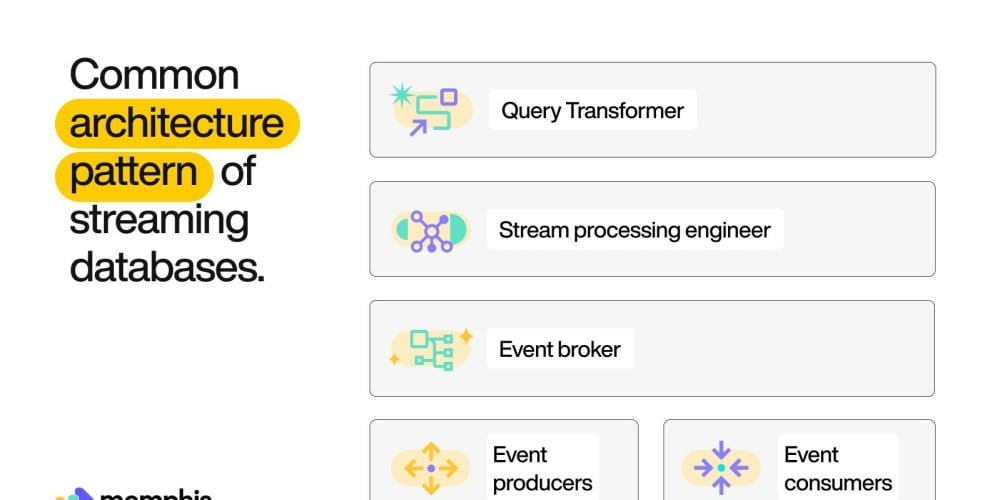
Now that the ideas are clear, allow us to spend a while on the architectural particulars of a streaming database. A streaming database is often constructed on high of a stream processing system that works primarily based on the producer-consumer paradigm. A producer is an entity that creates the occasions. A shopper consumes the occasions and processes them. The occasions are usually grouped into logical partitions of matters to facilitate enterprise logic implementation.
There’s a dealer that sits between them who ensures the reliability of the streams and format conversions that require for the producers and customers. Dealer is often distributed on a distributed platform to make sure excessive availability and robustness. A stream question engine resides on high of the processing platform. An SQL abstraction layer that converts SQL queries to stream processing logic can be current. Stitching collectively every little thing, the structure appears as under.
Now that we perceive the idea of streaming databases and protracted queries, allow us to spend a while on the standard use instances for them.
IoT Platforms
IoT platforms cope with numerous occasions being pushed from units the world over. They should spawn alerts primarily based on real-time processing and have strict SLAs with respect to response occasions. IoT platforms additionally must retailer all of the occasions acquired endlessly and require window-based aggregations on streaming information for analytics. Streaming databases and protracted queries are an excellent match right here.
Occasion Sourcing
Occasion sourcing is a paradigm the place software logic is executed by way of occasions that occurred over time fairly than the ultimate state of entities. This helps in bettering the sturdiness and reliability of the appliance for the reason that software state may be recreated anytime by replying to the occasions. That is helpful in instances the place an audit path is a compulsory requirement.
Click on Stream Analytics
Clickstream analytics platforms cope with click on occasions generated as a part of software utilization. The information from click on occasions are at occasions immediately fed to machine studying fashions that present suggestions and solutions to the purchasers. Persistent occasions and real-time processing on click on streams are an vital a part of working a enterprise like eCommerce.
Buying and selling Methods
Buying and selling programs course of tens of millions of commerce requests per second and match them towards the demand and provide equation to settle the transactions. An audit path is a compulsory requirement in such instances the place even the slightest of delays may cause large financial losses to events concerned.
Fraud Detection Methods
Fraud detection programs must act instantly as soon as detecting the eventualities that intently match the standard starting of fraud. In addition they should preserve a document of triggered the alerts and the next occasions after the incident. Take into account a monetary system fraud detection system that detects fraud primarily based on the spending patterns of the rightful proprietor. It must feed the options of occasions to a fraud detection mannequin on a real-time foundation and act instantly when flagging a doable breach. Actual-time databases are wonderful options to implement such use instances.
IT Methods Monitoring
Centralized monitoring helps organizations to maintain their IT programs all the time working Streaming databases are sometimes used to gather logs from programs and generate alerts when particular circumstances are met. The true-time alerts and audit trails generated by means of occasion storage are key parts of observable system implementation.
The streaming database market isn’t a crowded one and there are solely a handful of databases which might be battle-hardened to deal with manufacturing workloads. Kafka, Materialize, Memgraph, and many others are a number of of the steady ones. Selecting one that matches a use case requires an elaborate comparability of their options and use case dissection.
Allow us to now shift our focus to studying the important thing database design ideas and ensures behind streaming databases.
**4 Key Streaming Database Design Rules and Ensures
**The completeness of a database system is commonly represented by way of whether or not the database is ACID compliant. The ACID complaince varieties the inspiration of excellent database design ideas. ACID compliance stands for Atomicity, Consistency, Isolation, and Sturdiness. Atomicity refers back to the assure {that a} group of assertion a part of a logical operation will fail gracefully in case one of many statements have an error. Such a bunch of statements is named a transaction. Within the earlier days of streaming databases, transaction assist and therefore atomicity was usually lacking. However the newer variations do assist transactions.
Consistency refers to adhering to the principles enforced by the database like distinctive key constraints, overseas key constraints, and many others. A constant database will revert the transaction if the resultant state doesn’t adhere to those guidelines. Isolation is the idea of separate transaction execution such that one transaction doesn’t have an effect on the opposite. This allows parallel execution of transactions. Databases like KSQLDB assist robust consistency and parallel execution of queries. Sturdiness is about recovering from failure factors. The distributed nature of the structure ensures robust sturdiness for contemporary streaming databases.
Assure within the case of a streaming database refers back to the assurance on dealing with the occasions. Since information is constantly shifting, it’s troublesome to make sure the order of processing of occasions or keep away from duplicate processing. Making certain that each one information get processed precisely as soon as is an costly operation and requires state storage and acknowledgments. Equally guaranteeing that messages get processed in the identical order that they had been acquired requires advanced structure within the case of a distributed software.
Allow us to now look into the core design ideas and the way they’re achieved in streaming databases.
Auto Restoration
Auto restoration is among the most important database design precept in case of a streaming database. Streaming databases are utilized in extremely regulated domains like healthcare, monetary programs, and many others. In such domains, there aren’t any excuses for failures and incidents can lead to large financial loss and even lack of life. Think about a streaming database that’s built-in as part of a healthcare IoT platform. The sensors monitor the very important parameters of the sufferers and ship them to a streaming database hosted within the cloud. Such a system can by no means go down and the queries that generate alerts primarily based on threshold values ought to run indefinitely.
Since failure isn’t an choice for streaming databases, they’re usually carried out primarily based on a distributed structure. Streaming databases designed primarily based on a cluster of nodes present nice fault tolerance as a result of even when a number of of the nodes go down, the remainder of the system stays out there to simply accept queries. This fault tolerance should be integrated into the design of streaming databases early within the growth cycle. Allow us to see the important thing actions concerned within the auto restoration of streaming databases now.
Auto Restoration within the distributed streaming database includes the under actions:
Failure detection is step one of auto restoration. The system should be self-aware sufficient to detect failure circumstances in order that it could take essential steps for restoration. In distributed programs, failure detection is often finished by means of a heartbeat mechanism. A heartbeat is a periodic light-weight message that the nodes despatched every or to the grasp of the cluster. This lets others know that it’s alive and kicking. If the heartbeat message from a node isn’t acquired, the system assumes, it’s useless and initiates restoration procedures. The scale of heartbeat messages, the knowledge bundled in them, and the frequency of heartbeat messages are vital in optimizing the sources. A really frequent heartbeat will assist detect failures, that a lot earlier, nevertheless it additionally makes use of up processing time and creates overheads.
When a node failure happens in distributed programs, the sources owned by that node should be rebalanced to different nodes. Distributed programs use managed replication to make sure that information isn’t misplaced even when a number of of the nodes go down. As soon as a node goes down, the system ensures that information will get rebalanced throughout different nodes and maintains a replication technique as a lot as doable to scale back the chance of knowledge loss.
To keep up a extremely out there streaming database, rebalancing throughout partial failures isn’t sufficient. Because the queries are all the time working within the case of streaming databases, the system wants to make sure they preserve working. That is the place clever routing is available in. clever routing helps to make sure that the question retains working and returns the end result. The queries utilizing sources on the failed node are routed to different nodes seamlessly. This requires cautious design and is a part of the foundational necessities for a streaming database.
The ultimate restoration includes recovering the state shops which were misplaced through the incident. State shops are required to make sure the system meets the user-configured constraints precisely as soon as, at most as soon as, or not less than processing ensures. Distributed databases usually use an infinite log because the supply of reality. In addition they use separate matters the place they preserve the time offsets as a restoration mechanism. In case of a failure, this time offset subject can be utilized to recreate the timeline of occasions.
Precisely As soon as Semantics
Within the case of streaming databases, auto restoration in failure instances isn’t sufficient. Not like conventional database design, streaming database design ought to be certain that the outcomes misplaced through the time of failure don’t have an effect on the downstream shopper. There are a number of features to engaging in this. First, the system wants to make sure no information miss processing. This may be finished by reprocessing all of the information, however there are dangers concerned. For one, reprocessing with out satisfactory consideration can result in information being processed greater than as soon as. This causes inaccurate outcomes. For instance, contemplate the identical well being care IOT platform the place alerts are life-deciding ones. Duplicate processing can result in duplicate alerts and thereby the waste of sources. Duplicate processing may even result in aggregated outcomes like averages, percentile calculations, and many others.
Relying on the necessities, at occasions, some errors in occasion processing could also be acceptable. Streaming databases outline completely different message processing ensures to assist use instances with completely different necessities. There are three kinds of message ensures which might be out there — at most as soon as, not less than as soon as, and precisely as soon as. Utmost as soon as assure defines the case the place messages won’t ever be processed greater than as soon as, however at occasions might miss processing. The At-least-once assure defines the case the place duplicate processing is allowed, however lacking information isn’t acceptable.
Precisely as soon as semantics ensures {that a} message will likely be processed solely as soon as and the outcomes will likely be correct sufficient in order that the patron is oblivious to the failure incident. Allow us to discover this idea with the assistance of a diagram.

Let’s say the system is processing messages which might be coming so as. For illustration, messages are ordered beginning 1 right here. The processor receives the messages, transforms or aggregates it based on the logic, and passes them to the patron. Within the above diagram, inexperienced denotes the messages which might be but to be processed and pink denotes those which might be processed. Each time a message is processed, the processor updates a state retailer with the offset. That is to allow restoration in case of a failure. Now let’s say, the processor goes by means of an error after processing the second message and crashes. When the processor comes again up, it should restart processing from 3 and never from message 2. It ought to keep away from making a reproduction replace to the state retailer or feeding the end result kind message 2 once more to the patron.
In different phrases, the system masks failures each from a end result perspective and an inter-system communication perspective. This requires the producer, messaging system, and shopper to cooperate primarily based on agreed contracts. A message supply acknowledgment is the best assure that may assist the streaming database accomplish this. The contract ought to be capable of stand up to a dealer failure, a producer-to-broker communication failure, or perhaps a shopper failure.
Dealing with Out Of Order Data
Good database design considers dealing with out of order information as a important side. Streaming database encounter out of information as a consequence of many causes. The explanations embody community delays, producer unreliability, unsynchronized clocks and many others. Since they’re utilized in extremely delicate purposes like finance and healthcare the place order of processing is essential, streaming databases should deal with them graciously. To know the issue higher, allow us to contemplate the instance of the identical IOT healthcare platform. Let’s say as a consequence of a momentary web connection failure considered one of units didn’t ship information for a brief window of time. When it resumed, it began sending information from the resumption time. After some time, the firmware within the system despatched the remainder of the info that it had didn’t ship earlier. This results in out of order information arriving on the streaming database.
For higher context, let’s clarify this downside utilizing a diagram now. The under diagram has a producer that sends messages with numbers ranging from 1. The inexperienced blocks characterize the occasions which might be but to be despatched and the pink ones characterize the already despatched occasions right here. When messages. 1,2 and three arrive within the order of their timestamps, every little thing is ok. But when considered one of messages is delayed on the way in which or from the supply itself, it would trigger corruption to the outcomes from streaming platform. On this case, the messages 1 and three arrived sooner than 2. The streaming platform receives 2 after 1 and three, nevertheless it should be certain that the downstream shopper receives the messages within the precise order.
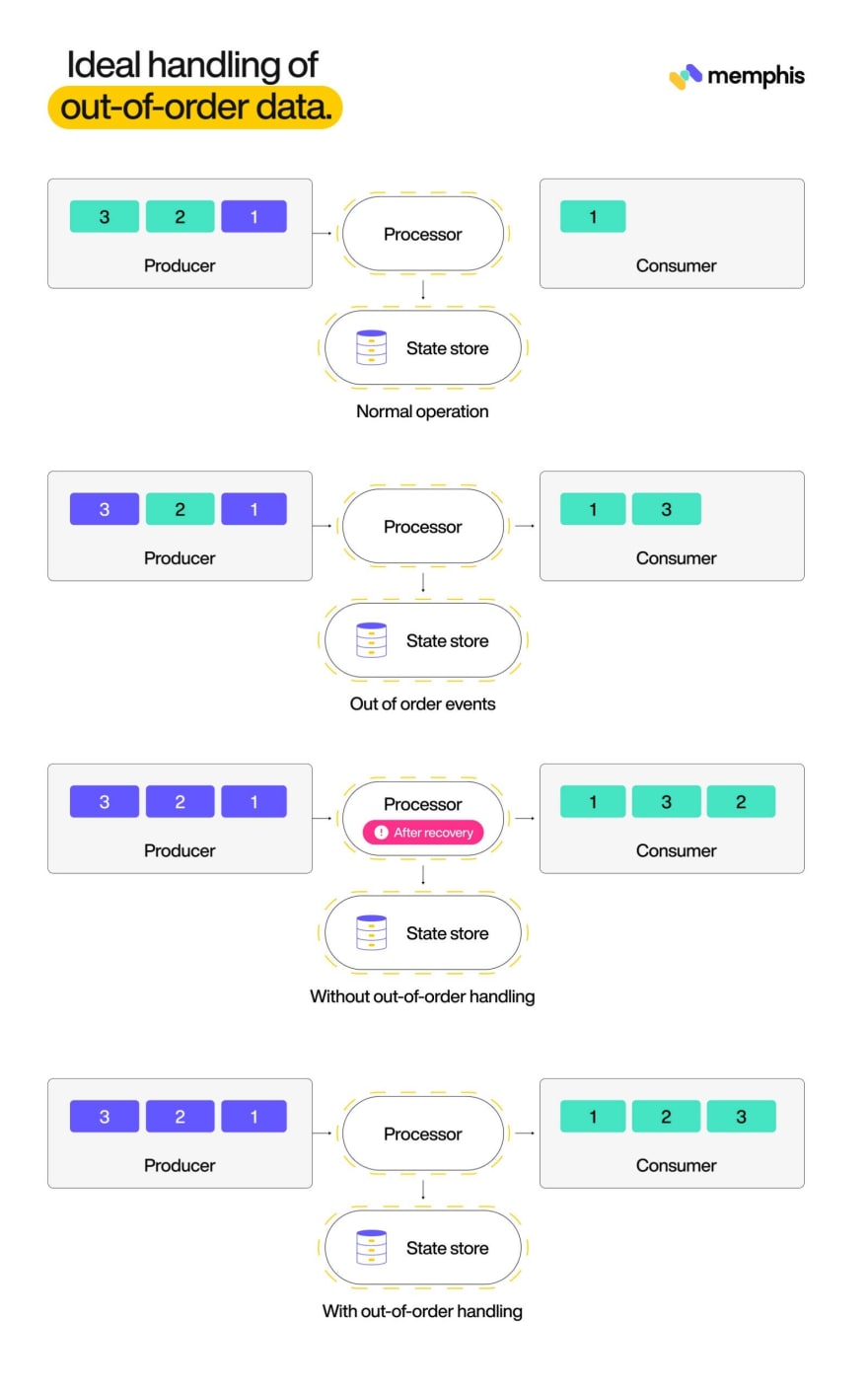
The streaming database that processes the information will present inaccurate outcomes to down stream programs if out-of-order information should not correctly addressed. For instance, shall we say, the messages denote a temperature worth and there’s a persistent question that finds the common temperature for the final one minute. A delayed temperature worth can lead to an faulty common worth. Streaming databases handles these instances in two strategies. The primary technique includes a configuration parameter that defines the period of time the processor will watch for out of order information to reach earlier than every micro batch begins. Micro batch is a bunch of information which might be a part of an actual time question. The idea of microbatch is the inspiration of persistent queries.
The second technique to deal with out-of-order information is to permit processor to replace already computed outcomes. This requires an settlement with the patron. This idea immediately conflicts with the idea of transactions and therefore requires cautious design whereas implementation. This works solely in instances the place the down stream customers is able to producing the identical output even when it acquired the enter in a special order. For instance, if the downstream shopper’s output is a desk that permits revisions, then streaming databases can use this technique.
Constant Question Outcomes
Implementing streaming databases is often primarily based on distributed structure. Conventional database design ideas contemplate atomicity and consistency as key pillars of excellent database design. However in case of streaming database, It’s powerful to perform consistency in writes as a result of the distributed nature. Take into account a streaming database that makes use of the idea of replicated partitions and deployed on a cluster of nodes. The incomes streams will likely be going to completely different partitions or nodes primarily based on the storage sample. To make sure tru write consistency, one wants to make sure the stream is confirmed solely when all of the partitions replicate it as profitable. That is troublesome when there are a number of messages as a part of a logical transaction. Monitoring individually and confirming every of the messages is crucial previous to marking the transaction as profitable.
The issue in guaranteeing write consistency trickles to learn consistency as nicely. Returning constant question outcomes are doable provided that reads are constant. Take into account a stream that acts as an information supply for a number of persistent queries that aggregates the stream based on completely different enterprise logic. A streaming database should be certain that each the queries act on a single supply of reality and the outcomes from the queries replicate non-conflicting values. That is a particularly troublesome proposition as a result of to be able to deal with out-of-order information, most databases function in a steady replace mode usually altering the outcomes that they beforehand computed. In case of concatenated queries, such updates trickle all the way down to downstream stream at completely different occasions and a few derived question state might replicate a special supply information state.
There are two methods of fixing the issue of constant question outcomes. The primary technique offers with this by guaranteeing that writes should not confirmed until the time, all queries originating from that stream completes. That is costly within the facet of the producer. As a result of to fulfill the precisely as soon as processing requirement, most streaming databases depend on aknwoedlegemtns between the dealer and the producer. If all of the writes are confirmed solely after question completion, then producers are saved at midnight for that for much longer. This strategy is the block-on-write strategy.
The second strategy to fixing consistency is to do it on the querying engine stage. Right here, the querying engine delays the outcomes of the particular queries that requires robust consistency ensures until all of the writes are confirmed. That is cheaper than the primary strategy as a result of the write efficiency of enter streams isn’t affected. Relatively than delaying the affirmation of the enter stream that acts as basis of a question, this strategy operates at question stage. So if a question doesn’t require robust consistency ensures, the outcomes for that will likely be emitted sooner than different queries that rely on the identical enter stream. Therefore, completely different queries function on completely different variations of the identical enter stream relying on their consistency configuration. This requires the streaming database to maintain a linearized historical past of all of the computations in order that it could simply conclude in regards to the variations on information on which a number of queries had been executed.
Streaming databases should stability between staleness of the info and ranges of consistency to be able to optimize the efficiency. Going up by means of the degrees of consistency might lead to diminished pace of processing and vice versa.
Conclusion
Streaming databases are the inspiration of actual time processing purposes. They don’t seem to be a substitute for conventional databases however helps fulfill distinctive necessities that want always-on processing on by no means ending streams of knowledge. Designing a streaming database is a fancy job due to the constraints concerned in dealing with streaming information. Attaining learn consistency, dealing with out-of-erder information, guaranteeing exactly-once processing and auto restoration are the standard design ideas in consideration whereas designing a streaming database.
Because of Idan Asulin Co-founder & CTO at memphis.dev for the writing.

{kind=link}