
Would you be considering understanding which politician has made essentially the most headlines? Do you need to see which movie star has finest held the eye of journalists over time? Are you intrigued in regards to the distinction in crime information grouped by states?
In case your reply is sure to any of these questions, then we share the identical curiosity.
Taking a look at archives maintained by Newspapers, I puzzled who would undergo over twenty-five thousand pages of stories headlines sorted by date and make any heads or tails of the large image round it. How may somebody analyse traits or good points insights from an nearly countless checklist of headlines courting many years in the past by simply studying them on an internet site.
However I couldn’t cease myself from doing one thing about this downside I had at hand. I wanted to plan a technique to reliably, effectively and simply comb by the info these archives made obtainable. To perform this aim, I set out with this undertaking.
On this writeup I’ll go over how I created a elementary device or technique for anybody to simply analyse, perceive and analysis the Indian Headlines information of the previous 25 years.
PART 1: The Knowledge
To start out with my undertaking, I assumed I may simply discover a dataset which contained all the info I wanted, correctly formatted in a csv file and would solely go away me to jot down scripts to analyse that information. If solely life was that simple.
Sadly, I couldn’t discover any dataset appropriate to my wants and thus needed to dedicate a good portion of work-time of this undertaking on procuring and cleansing the info myself.
Ideally, we would wish an information file with an exhaustive, credible and unbiased assortment of headlines from a big sufficient timeline.
Sourcing the Knowledge
Within the absence of pre-prepared datasets, I needed to discover a credible supply to gather headlines information stretching for a big length of time. So what higher place than the web sites of main journalistic organisations like The Instances, The Hindu, Deccan Herald or the Indian Categorical.
However these organisations don’t publicly present a simple technique to procure the info we want. So the obvious means was to learn the info off their very own web sites. Fortuitously nearly all of those organisations present a public archive of their journalism which is healthier possibility than sitting and recording all of the headlines myself for the following decade.
However the archives that these organisations present don’t let you simply export the info they make obtainable themselves in a format which will be utilized by us. So the easiest way to acquire the info we want is to make the most of Net Scraping.
Net Scraping
Net Scraping is basically the method of routinely extract the info we want from web sites by using instruments which may parse and browse information from the supply code of those web sites (Largely HTML).
For this undertaking, I exploit the next python modules/packages that are extraordinarily suited to the duty:
- BeautifulSoup: A python library that makes it simple to scrape content material from net pages. It sits atop an HTML or XML parser, offering Pythonic idioms for iterating, looking, and modifying the parse tree.
- Requests: The requests module permits you to ship HTTP requests utilizing Python. The HTTP request returns a Response Object with all of the response information(the online web page code).
❗ I’ve not lined the Ethics of utilizing Net Scraping Strategies within the scope of this undertaking. Please do your analysis earlier than placing into apply any code/directions current right here. ❗
 |
|---|
| A screenshot of the Indian Categorical Archives web page I scraped for the aim of this undertaking. |
I made a decision to make use of the Indian Categorical Information Archives as a result of it generates its content material statically and the URL to vary pages is well iterable by code. Sure different public archives generate their net pages dynamically by JavaScript, whereas some others make it very tough to traverse the content material for the scraping script.
Now lets take a look at the code for the scraping script I wrote:
Code Implementation
That is the essential code wanted to acquire the supply HTML code from the Indian Categorical pages. The pageNumber is the variable iterated by a for loop within the vary of the pages we have to scrape.
url = "https://indianexpress.com/part/news-archive/web page/"+str(pageNumber)+"https://dev.to/"
page_request = requests.get(url)
information = page_request.content material
soup = BeautifulSoup(information,"html.parser")
The ultimate obtained supply code is saved within the soup variable.
Now, the precise headlines within the code are literally saved inside <h2> tags with the category identify as title. So all we have to do is use the BeautifulSoup library and filter the obtained code to learn off the <a> tags from the filtered title headline tags. Then we additional use get_text perform to get the headline string.
for divtag in soup.find_all('h2', {'class': 'title'}):
for atag in divtag.find_all('a'):
#HEADLINES
hl=atag.get_text()
print("Headline: ",hl) # This prints the scraped headline.
It’s far more handy for us to retailer the scraped information in a textual content file, reasonably than print it on the terminal. An answer to jot down all of this information is well carried out with the next code.
file1 = open(r"<ABSOLUTE PATH>headlines.txt","a",encoding="utf-8")
file1.write(hl.decrease()) # saved in decrease for simpler evaluation
file1.write("n")
file1.shut()
When this code is correctly looped, it may be used to scrape and procure the headline information from the entire archive reasonably than only one web page. On this case the pages lengthen to Web page 25073 and thus a the above code can merely be put right into a loop iterating over all of the pages.
After I ran the ultimate script for the primary time, I realised that scraping over 25 thousand pages with this script would take me over a number of days operating my the script 24×7, whereas any interruption to the method may erase all of the progress.
Thus for the sake of accessibility, ease-of-use and practicality of the method I carried out the code in a vogue the place it may very well be paused at any second and would save and bear in mind its progress. Whereas this addressed the issue of interruptions and with the ability to pause the script execution, it was nonetheless projected to take me a really very long time to simply be capable to scrape this information. To lower the time it will take for the entire scraping of the archive, I divided the 25 thousand pages into 20 equal teams. This allowed my workstation to concurrently run twenty situations of the identical script operating parallel workloads and lowering the time wanted over twentyfold.
PART 2: The Framework
The entire above described course of lastly netted me a listing of over 6.5 lac headlines in a textual content file within the following format:
covid-19: up govt extends closure of all colleges, faculties until january 23
renotify 27% seats reserved for obcs in native physique polls, sc tells maharashtra, sec
talks fail over motion towards karnal ex-sdm, siege continues
jagan promotes andhra as favoured funding vacation spot, defends scrapping ppas
murder-accused husband of mla visits home, bjp slams congress
over 25,000 cops, cctvs, drones to safe gujarat rath yatra on july 4
in bhutan, lecturers, medical workers will now be highest paid civil servants
‘cyclone man’ mrutyunjay mohapatra appointed imd chief
pakistan resort assault: 4 killed as armed militants storm 5-star resort in gwadar port metropolis, says police
indian man convicted in dubai for hacking 15 consumer web sites
[continued]
These headlines embody a time interval of 25 years (Thus the title) from 1997-2022.
Key phrase Evaluation
It’s clearly in a way more accessible format now, however how can we run any form of evaluation on this information file?
The easy reply is Key phrase Evaluation. Within the context of this undertaking, it’s the technique of classifying, categorizing, labelling, and analysing these headlines by the presence (or lack of) sure phrases in them.
For instance, if a sure headline has the phrase “Mahatma Gandhi”, “Bapu”, or “Gandhi Ji”, it is extremely more likely to be a headline reporting one thing about Gandhi. We shall be utilizing this type of deduction within the scope of this undertaking to analyse the dataset that now we have fashioned.
Due to this fact to train this concept, we have to implement sure instruments to be on our disposal. Within the scope of this undertaking, these instruments are mainly strategies/capabilities which discover(/combination) the headlines relying on the presence of key phrases. A number of totally different want based mostly circumstances will be imagined, however general they’ll all be divided into the next elementary implementations:
- Discovering the headlines the place any of the key phrase from a bunch is discovered.
- Discovering the headlines the place all the key phrases from a bunch are discovered.
- Discovering the headlines the place any of the key phrases from every of the a number of teams are discovered.
Another wanted use-case will be made to suit/work with these elementary capabilities. For instance, if we have to discover the headlines the place all the key phrases from every of the a number of teams in discovered, we are able to simply merge the teams and use the second perform for them. Then again if we have to discover the headlines the place the key phrases don’t happen, we are able to simply eradicate the headlines the place these key phrases do happen utilizing the primary perform.
Code Implementation
The above talked about three elementary capabilities are carried out as follows:
-
Discovering the headlines the place any of the key phrase from a bunch is discovered.
Right here, the code iterates by all of the headlines within theheadLinesListobject and if any of the key phrase supplied within the checklist is discovered then the counter maintained is bumped and at last returned.
# FUNCTION TO COUNT HEADLINES WHERE ANY OF THE WORD/S OCCURS
# - wordsToSearch is a listing of the shape ["word1","word2","word3",...]
def countOccurancesAny(wordsToSearch):
depend = 0
for headline in headLinesList:
for eachWord in wordsToSearch:
if headline.discover(eachWord.decrease()) != -1:
depend += 1
break
return depend
-
Discovering the headlines the place all the key phrases from a bunch are discovered.
The premise right here is nearly the identical as the first perform, however as an alternative of looking for one phrase after which bumping the counter, this perform has to attend and ensure all the weather of the checklist are discovered within the headline.
For optimisation functions, the loop skips cycles if any of the component just isn’t discovered.
# FUNCTION TO COUNT HEADLINES WHERE ALL OF THE WORD/S OCCURS
# - wordsToSearch is a listing of the shape ["word1","word2","word3",...]
def countOccurancesAll(wordsToSearch):
mainCount = 0
wordCount = 0
totalWords = len(wordsToSearch)
for headline in headLinesList:
wordCount = 0
for eachWord in wordsToSearch:
if headline.discover(eachWord.decrease()) == -1:
break
else:
wordCount += 1
if wordCount == totalWords:
mainCount += 1
return mainCount
-
Discovering the headlines the place any of the key phrases from every of the a number of teams are discovered.
This perform mainly nests the primary perform yet another time, discovering out if a key phrase from the teams handed off as 2D lists are current. There may be additionally optimization much like perform 2 current right here.
# FUNCTION TO COUNT HEADLINES WHERE ANY OF THE WORD/S FROM MULTIPLE GROUPS OCCURS
# - wordsToSearch is a listing of lists, every of the shape ["word1","word2","word3",...]
def countOccurancesGroupedAny(wordsToSearch):
depend = 0
countMain = 0
for headline in headLinesList:
countMain = 0
for eachGroup in wordsToSearch:
optimiseCheck1 = 0
for eachWord in eachGroup:
if headline.discover(eachWord.decrease()) != -1:
optimiseCheck1 = 1
countMain += 1
break
if optimiseCheck1 == 0:
break
if countMain == len(wordsToSearch):
depend += 1
return depend
Properly, now that now we have appeared on the instruments and platforms I developed for this undertaking, lets take a look at how these can be utilized to analyse and interpret information.
PART 3: The Evaluation
An evaluation was not a lot the main focus of this undertaking than really growing a framework permitting for straightforward evaluation of this dataset. However I’ve nonetheless executed some evaluation and visualizations to reveal the usability of the above described code.
I shall be utilizing the phrase “Fashionable” to indicate how a lot the entity has been in information. It has unreliable correlation with precise reputation.
Most Fashionable Political Get together
First, we create lists with the key phrases that shall be used to establish acceptable headlines. These lists include key phrases that I believe are sufficient to establish if a headline is aimed toward these events.Then the info is obtained and organized as a pandas dataframe after which printed sorted by headlines depend.
bjp = ["bjp","Bharatiya Janata Party"]
inc = ["INC","Congress"]
aap = ["AAP","Aam Aadmi Party"]
cpi = ["CPI","Communist Party of India"]
bsp = ["BSP","Bahujan Samaj Party"]
dmk = ["DMK","Dravida Munnetra Kazhagam"]
shivsena = ["sena","shiv sena"]
information = {'Get together': ['BJP', 'INC', 'AAP', 'CPI', 'BSP', 'DMK', 'SHIV SENA'],
'Reported': [hd.countOccurancesAny(bjp),hd.countOccurancesAny(inc),hd.countOccurancesAny(aap),hd.countOccurancesAny(cpi),hd.countOccurancesAny(bsp),hd.countOccurancesAny(dmk),hd.countOccurancesAny(shivsena)]}
df = pd.DataFrame(information)
print(df.sort_values("Reported",ascending=False))
The result’s visualised within the following graph:
As is clearly discernible, INC is essentially the most reported on by half adopted very carefully by BJP.
Most Reported Politician
The code to crunch the numbers is similar to the one we noticed above:
modi = ["Modi","Narendra Modi","Narendra Damodardas Modi"]
amitshah = ["amit shah","shah"]
rajnath = ["rajnath singh"]
jaishankar = ["jaishankar"]
mamata = ["mamata","didi"]
kejriwal = ["aravind","kejriwal"]
yogi = ["adityanath","yogi","ajay bisht"]
rahul = ["rahul"]
stalin = ["stalin"]
akhilesh = ["akhilesh"]
owaisi = ["owaisi"]
gehlot = ["gehlot"]
biswa = ["himanta biswa","biswa"]
scindia = ["scindia"]
sibal = ["sibal"]
manmohan = ["manmohan singh"]
mayavati = ["mayavati"]
mulayam = ["mulayam"]
naveen = ["patnaik"]
nitish = ["nitish"]
sonia = ["sonia"]
uddhav = ["uddhav"]
information = {
'Political' : ['Narendra Modi','Amit Shah','Rajnath Singh','S Jaishankar',
'Mamata Bannerjee','Aravind Kejrival','Yogi Adityanath','Rahul Gandhi','MK Stalin',
'Akhilesh Yadav','Asaduddin Owaisi','Ashok Gehlot','Himanta Biswa Sarma', 'Jotiraditya Scindia',
'Kapil Sibal','Manmohan Singh','Mayavati','Mulayam Singh Yadav','Naveen Patnaik','Nitish Kumar','Sonia Gandhi','Uddhav Thackeray'],
'Reported' : [hd.countOccurancesAny(modi),hd.countOccurancesAny(amitshah),hd.countOccurancesAny(rajnath),hd.countOccurancesAny(jaishankar),
hd.countOccurancesAny(mamata),
hd.countOccurancesAny(kejriwal),hd.countOccurancesAny(yogi),hd.countOccurancesAny(rahul),hd.countOccurancesAny(stalin),
hd.countOccurancesAny(akhilesh),hd.countOccurancesAny(owaisi),hd.countOccurancesAny(gehlot),hd.countOccurancesAny(biswa),hd.countOccurancesAny(scindia),
hd.countOccurancesAny(sibal),hd.countOccurancesAny(manmohan),hd.countOccurancesAny(mayavati),hd.countOccurancesAny(mulayam),hd.countOccurancesAny(naveen),
hd.countOccurancesAny(nitish),hd.countOccurancesAny(sonia),hd.countOccurancesAny(uddhav)]
}
df = pd.DataFrame(information)
print(df.sort_values("Reported",ascending=False))
For the visualization side of this I considered utilizing a Circle Packing Graph. I explored my choices with exterior visualization choices however none of them supplied what I used to be on the lookout for.
After lots of analysis I came upon a technique to generate what I needed by python code and the Circlify module.
So, I wrote the code to generate the graph I used to be on the lookout for. But it surely turned out to not be as polished or presentable as I needed it to be. However I’m nonetheless together with the code snippet I wrote:
# compute circle positions:
circles = circlify.circlify(
df['Reported'].tolist(),
show_enclosure=False,
target_enclosure=circlify.Circle(x=0, y=0, r=1)
)
# Create only a determine and just one subplot
fig, ax = plt.subplots(figsize=(10,10))
# Take away axes
ax.axis('off')
# Discover axis boundaries
lim = max(
max(
abs(circle.x) + circle.r,
abs(circle.y) + circle.r,
)
for circle in circles
)
plt.xlim(-lim, lim)
plt.ylim(-lim, lim)
# checklist of labels
labels = df['Reported']
# print circles
for circle, label in zip(circles, labels):
x, y, r = circle
ax.add_patch(plt.Circle((x, y), r, alpha=0.2, linewidth=2))
plt.annotate(
label,
(x,y ) ,
va='middle',
ha='middle'
)
plt.present()
As a substitute of the Circle Packing Graph, I made a decision to create the next visualization which presents the info generated by my above code.

Crime Statistics By States
Earlier than diving proper into the the crime information statistics, lets first write particular person code for calculating State statistics, and crime statistics.
# Crime Statistics
theft = ['robbery','thief','thieves','chori']
sexual = ['rape','rapist','sexual assault']
dowry = ['dowry','dahej']
medicine = ['drug']
traffick = ['traffick']
cyber = ['hack','cyber crime','phish']
homicide = ['murder']
information = {
'Crime':['Robbery','Sexual','Dowry',"Drugs",'Trafficking','Cyber','Murder'],
'Reported':[hd.countOccurancesAny(robbery),hd.countOccurancesAny(sexual),hd.countOccurancesAny(dowry),hd.countOccurancesAny(drugs)
,hd.countOccurancesAny(traffick),hd.countOccurancesAny(cyber),hd.countOccurancesAny(murder)]
}
df = pd.DataFrame(information)
print(df.sort_values("Reported",ascending=False))
# Crime Reported
# 6 Homicide 3271
# 1 Sexual 2533
# 5 Cyber 1538
# 3 Medicine 1403
# 0 Theft 384
# 2 Dowry 217
# 4 Trafficking 170
# States Stats
UttarPradesh = ['Uttar Pradesh', ' UP ',"Agra" ,"Aligarh" ,"Ambedkar Nagar" ,"Amethi" ,"Amroha" ,"Auraiya" ,"Ayodhya" ,"Azamgarh" ,"Baghpat" ,"Bahraich" ,"Ballia" ,"Balrampur" ,"Barabanki" ,"Bareilly" ,"Bhadohi" ,"Bijnor" ,"Budaun" ,"Bulandshahr" ,"Chandauli" ,"Chitrakoot" ,"Deoria" ,"Etah" ,"Etawah" ,"Farrukhabad" ,"Fatehpur" ,"Firozabad" ,"Gautam Buddha Nagar" ,"Ghaziabad" ,"Ghazipur" ,"Gorakhpur" ,"Hamirpur" ,"Hardoi" ,"Hathras" ,"Jalaun" ,"Jaunpur" ,"Jhansi" ,"Kannauj" ,"Kanpur Dehat" ,"Kanpur Nagar" ,"Kasganj" ,"Kaushambi" ,"Kushinagar" ,"Lalitpur" ,"Lucknow" ,"Maharajganj" ,"Mahoba" ,"Mainpuri" ,"Mathura" ,"Meerut" ,"Mirzapur" ,"Moradabad" ,"Muzaffarnagar" ,"Pilibhit" ,"Pratapgarh" ,"Prayagraj" ,"Raebareli" ,"Rampur" ,"Saharanpur" ,"Sambhal" ,"Sant Kabir Nagar" ,"Shahjahanpur" ,"Shamli" ,"Shravasti" ,"Siddharthnagar" ,"Sitapur" ,"Sonbhadra" ,"Sultanpur" ,"Unnao" ,"Varanasi" ]
AndamanNicobar = ["Andaman","Nicobar"]
AndhraPradesh = ["Andhra","Anantapur" ,"Chittoor" ,"East Godavari" ,"Alluri Sitarama Raju" ,"Anakapalli" ,"Annamaya" ,"Bapatla" ,"Eluru" ,"Guntur" ,"Kadapa" ,"Kakinada" ,"Konaseema" ,"Krishna" ,"Kurnool" ,"Manyam" ,"N T Rama Rao" ,"Nandyal" ,"Nellore" ,"Palnadu" ,"Prakasam" ,"Sri Balaji" ,"Sri Satya Sai" ,"Srikakulam" ,"Visakhapatnam" ,"Vizianagaram" ,"West Godavari"]
ArunachalPradesh = ['Arunachal',"Anjaw" ,"Changlang" ,"Dibang Valley" ,"East Kameng" ,"East Siang" ,"Kamle" ,"Kra Daadi" ,"Kurung Kumey" ,"Lepa Rada" ,"Lohit" ,"Longding" ,"Lower Dibang Valley" ,"Lower Siang" ,"Lower Subansiri" ,"Namsai" ,"Pakke Kessang" ,"Papum Pare" ,"Shi Yomi" ,"Siang" ,"Tawang" ,"Tirap" ,"Upper Siang" ,"Upper Subansiri" ,"West Kameng" ,"West Siang" ]
Assam = ['assam',"Bajali" ,"Baksa" ,"Barpeta" ,"Biswanath" ,"Bongaigaon" ,"Cachar" ,"Charaideo" ,"Chirang" ,"Darrang" ,"Dhemaji" ,"Dhubri" ,"Dibrugarh" ,"Dima Hasao" ,"Goalpara" ,"Golaghat" ,"Hailakandi" ,"Hojai" ,"Jorhat" ,"Kamrup" ,"Kamrup Metropolitan" ,"Karbi Anglong" ,"Karimganj" ,"Kokrajhar" ,"Lakhimpur" ,"Majuli" ,"Morigaon" ,"Nagaon" ,"Nalbari" ,"Sivasagar" ,"Sonitpur" ,"South Salmara-Mankachar" ,"Tinsukia" ,"Udalguri" ,"West Karbi Anglong" ]
Bihar = ['bihar', "Araria" ,"Arwal" ,"Aurangabad" ,"Banka" ,"Begusarai" ,"Bhagalpur" ,"Bhojpur" ,"Buxar" ,"Darbhanga" ,"East Champaran" ,"Gaya" ,"Gopalganj" ,"Jamui" ,"Jehanabad" ,"Kaimur" ,"Katihar" ,"Khagaria" ,"Kishanganj" ,"Lakhisarai" ,"Madhepura" ,"Madhubani" ,"Munger" ,"Muzaffarpur" ,"Nalanda" ,"Nawada" ,"Patna" ,"Purnia" ,"Rohtas" ,"Saharsa" ,"Samastipur" ,"Saran" ,"Sheikhpura" ,"Sheohar" ,"Sitamarhi" ,"Siwan" ,"Supaul" ,"Vaishali" ,"West Champaran"]
Chandigarh = ['Chandigarh']
Chhattisgarh = ['Chhattisgarh', "Balod" ,"Baloda Bazar" ,"Balrampur" ,"Bastar" ,"Bemetara" ,"Bijapur" ,"Bilaspur" ,"Dantewada" ,"Dhamtari" ,"Durg" ,"Gariaband" ,"Gaurela Pendra Marwahi" ,"Janjgir Champa" ,"Jashpur" ,"Kabirdham" ,"Kanker" ,"Kondagaon" ,"Korba" ,"Koriya" ,"Mahasamund" ,"Manendragarh" ,"Mohla Manpur" ,"Mungeli" ,"Narayanpur" ,"Raigarh" ,"Raipur" ,"Rajnandgaon" ,"Sakti" ,"Sarangarh Bilaigarh" ,"Sukma" ,"Surajpur"]
Dadra = ['Dadra', 'Daman', 'Diu']
Delhi = ['Delhi']
Goa = ['Goa']
Gujrat = ['Gujrat', "Ahmedabad" ,"Amreli" ,"Anand" ,"Aravalli" ,"Banaskantha" ,"Bharuch" ,"Bhavnagar" ,"Botad" ,"Chhota Udaipur" ,"Dahod" ,"Dang" ,"Devbhoomi Dwarka" ,"Gandhinagar" ,"Gir Somnath" ,"Jamnagar" ,"Junagadh" ,"Kheda" ,"Kutch" ,"Mahisagar" ,"Mehsana" ,"Morbi" ,"Narmada" ,"Navsari" ,"Panchmahal" ,"Patan" ,"Porbandar" ,"Rajkot" ,"Sabarkantha" ,"Surat" ,"Surendranagar" ,"Tapi" ,"Vadodara" ,"Valsad"]
Haryana = ['Haryana', "Ambala" ,"Bhiwani" ,"Charkhi Dadri" ,"Faridabad" ,"Fatehabad" ,"Gurugram" ,"Hisar" ,"Jhajjar" ,"Jind" ,"Kaithal" ,"Karnal" ,"Kurukshetra" ,"Mahendragarh" ,"Mewat" ,"Palwal" ,"Panchkula" ,"Panipat" ,"Rewari" ,"Rohtak" ,"Sirsa" ,"Sonipat" ,"Yamunanagar"]
HimachalPradesh = ['Himachal',"Bilaspur" ,"Chamba" ,"Hamirpur" ,"Kangra" ,"Kinnaur" ,"Kullu" ,"Lahaul Spiti" ,"Mandi" ,"Shimla" ,"Sirmaur" ,"Solan" ,"Una" ]
JammuKashmir = ["Jammu", "Kashmir", "J&K", "JK", "Anantnag" ,"Bandipora" ,"Baramulla" ,"Budgam" ,"Doda" ,"Ganderbal" ,"Jammu" ,"Kathua" ,"Kishtwar" ,"Kulgam" ,"Kupwara" ,"Poonch" ,"Pulwama" ,"Rajouri" ,"Ramban" ,"Reasi" ,"Samba" ,"Shopian" ,"Srinagar" ,"Udhampur"]
Jharkand = ["Jharkand", "Bokaro" ,"Chatra" ,"Deoghar" ,"Dhanbad" ,"Dumka" ,"East Singhbhum" ,"Garhwa" ,"Giridih" ,"Godda" ,"Gumla" ,"Hazaribagh" ,"Jamtara" ,"Khunti" ,"Koderma" ,"Latehar" ,"Lohardaga" ,"Pakur" ,"Palamu" ,"Ramgarh" ,"Ranchi" ,"Sahebganj" ,"Seraikela Kharsawan" ,"Simdega" ,"West Singhbhum"]
Karnataka = ['Karnataka',"Bagalkot" ,"Bangalore Rural" ,"Bangalore Urban" ,"Belgaum" ,"Bellary" ,"Bidar" ,"Chamarajanagar" ,"Chikkaballapur" ,"Chikkamagaluru" ,"Chitradurga" ,"Dakshina Kannada" ,"Davanagere" ,"Dharwad" ,"Gadag" ,"Gulbarga" ,"Hassan" ,"Haveri" ,"Kodagu" ,"Kolar" ,"Koppal" ,"Mandya" ,"Mysore" ,"Raichur" ,"Ramanagara" ,"Shimoga" ,"Tumkur" ,"Udupi" ,"Uttara Kannada" ,"Vijayanagara" ,"Vijayapura" ,"Yadgir"]
Kerala = ['Kerala', "Alappuzha" ,"Ernakulam" ,"Idukki" ,"Kannur" ,"Kasaragod" ,"Kollam" ,"Kottayam" ,"Kozhikode" ,"Malappuram" ,"Palakkad" ,"Pathanamthitta" ,"Thiruvananthapuram" ,"Thrissur" ,"Wayanad"]
Ladakh = ['Ladakh','leh','kargil']
Lakshadweep = ['Lakshadweep']
MadhyaPradesh = ["Madhya", "Agar Malwa" ,"Alirajpur" ,"Anuppur" ,"Ashoknagar" ,"Balaghat" ,"Barwani" ,"Betul" ,"Bhind" ,"Bhopal" ,"Burhanpur" ,"Chachaura" ,"Chhatarpur" ,"Chhindwara" ,"Damoh" ,"Datia" ,"Dewas" ,"Dhar" ,"Dindori" ,"Guna" ,"Gwalior" ,"Harda" ,"Hoshangabad" ,"Indore" ,"Jabalpur" ,"Jhabua" ,"Katni" ,"Khandwa" ,"Khargone" ,"Maihar" ,"Mandla" ,"Mandsaur" ,"Morena" ,"Nagda" ,"Narsinghpur" ,"Neemuch" ,"Niwari" ,"Panna" ,"Raisen" ,"Rajgarh" ,"Ratlam" ,"Rewa" ,"Sagar" ,"Satna" ,"Sehore" ,"Seoni" ,"Shahdol" ,"Shajapur" ,"Sheopur" ,"Shivpuri" ,"Sidhi" ,"Singrauli" ,"Tikamgarh" ,"Ujjain" ,"Umaria" ,"Vidisha"]
Maharashtra = ["Maharashtra", "Bombay", "Ahmednagar" ,"Akola" ,"Amravati" ,"Aurangabad" ,"Beed" ,"Bhandara" ,"Buldhana" ,"Chandrapur" ,"Dhule" ,"Gadchiroli" ,"Gondia" ,"Hingoli" ,"Jalgaon" ,"Jalna" ,"Kolhapur" ,"Latur" ,"Mumbai" ,"Mumbai Suburban" ,"Nagpur" ,"Nanded" ,"Nandurbar" ,"Nashik" ,"Osmanabad" ,"Palghar" ,"Parbhani" ,"Pune" ,"Raigad" ,"Ratnagiri" ,"Sangli" ,"Satara" ,"Sindhudurg" ,"Solapur" ,"Thane" ,"Wardha" ,"Washim" ,"Yavatmal"]
Manipur = ['Manipur', "Bishnupur" ,"Chandel" ,"Churachandpur" ,"Imphal East" ,"Imphal West" ,"Jiribam" ,"Kakching" ,"Kamjong" ,"Kangpokpi" ,"Noney" ,"Pherzawl" ,"Senapati" ,"Tamenglong" ,"Tengnoupal" ,"Thoubal" ,"Ukhrul"]
Meghalaya = ['Megh', "East Garo Hills" ,"East Jaintia Hills" ,"East Khasi Hills" ,"Mairang" ,"North Garo Hills" ,"Ri Bhoi" ,"South Garo Hills" ,"South West Garo Hills" ,"South West Khasi Hills" ,"West Garo Hills" ,"West Jaintia Hills" ,"West Khasi Hills"]
Mizoram = ['Mizoram', "Aizawl" ,"Champhai" ,"Hnahthial" ,"Khawzawl" ,"Kolasib" ,"Lawngtlai" ,"Lunglei" ,"Mamit" ,"Saiha" ,"Saitual" ,"Serchhip" ]
Nagaland = ['Nagaland', "Chumukedima" ,"Dimapur" ,"Kiphire" ,"Kohima" ,"Longleng" ,"Mokokchung" ,"Niuland" ,"Noklak" ,"Peren" ,"Phek" ,"Tseminyu" ,"Tuensang" ,"Wokha" ,"Zunheboto"]
Odisha = ['Odisha', "Angul" ,"Balangir" ,"Balasore" ,"Bargarh" ,"Bhadrak" ,"Boudh" ,"Cuttack" ,"Debagarh" ,"Dhenkanal" ,"Gajapati" ,"Ganjam" ,"Jagatsinghpur" ,"Jajpur" ,"Jharsuguda" ,"Kalahandi" ,"Kandhamal" ,"Kendrapara" ,"Kendujhar" ,"Khordha" ,"Koraput" ,"Malkangiri" ,"Mayurbhanj" ,"Nabarangpur" ,"Nayagarh" ,"Nuapada" ,"Puri" ,"Rayagada" ,"Sambalpur" ,"Subarnapur" ,"Sundergarh"]
Puducherry = ['Puducherry', "Karaikal" ,"Mahe" ,"Puducherry" ,"Yanam" ]
Punjab = ['Punjab', "Amritsar" ,"Barnala" ,"Bathinda" ,"Faridkot" ,"Fatehgarh Sahib" ,"Fazilka" ,"Firozpur" ,"Gurdaspur" ,"Hoshiarpur" ,"Jalandhar" ,"Kapurthala" ,"Ludhiana" ,"Malerkotla" ,"Mansa" ,"Moga" ,"Mohali" ,"Muktsar" ,"Pathankot" ,"Patiala" ,"Rupnagar" ,"Sangrur" ,"Shaheed Bhagat Singh Nagar" ,"Tarn Taran"]
Rajasthan = ['Rajasthan', "Ajmer" ,"Alwar" ,"Banswara" ,"Baran" ,"Barmer" ,"Bharatpur" ,"Bhilwara" ,"Bikaner" ,"Bundi" ,"Chittorgarh" ,"Churu" ,"Dausa" ,"Dholpur" ,"Dungarpur" ,"Hanumangarh" ,"Jaipur" ,"Jaisalmer" ,"Jalore" ,"Jhalawar" ,"Jhunjhunu" ,"Jodhpur" ,"Karauli" ,"Kota" ,"Nagaur" ,"Pali" ,"Pratapgarh" ,"Rajsamand" ,"Sawai Madhopur" ,"Sikar" ,"Sirohi" ,"Sri Ganganagar" ,"Tonk" ,"Udaipur"]
Sikkim = ['Sikkim','Soreng','Pakyong']
TamilNadu = ["Tamil Nadu", "Ariyalur" ,"Chengalpattu" ,"Chennai" ,"Coimbatore" ,"Cuddalore" ,"Dharmapuri" ,"Dindigul" ,"Erode" ,"Kallakurichi" ,"Kanchipuram" ,"Kanyakumari" ,"Karur" ,"Krishnagiri" ,"Madurai" ,"Mayiladuthurai" ,"Nagapattinam" ,"Namakkal" ,"Nilgiris" ,"Perambalur" ,"Pudukkottai" ,"Ramanathapuram" ,"Ranipet" ,"Salem" ,"Sivaganga" ,"Tenkasi" ,"Thanjavur" ,"Theni" ,"Thoothukudi" ,"Tiruchirappalli" ,"Tirunelveli" ,"Tirupattur" ,"Tiruppur" ,"Tiruvallur" ,"Tiruvannamalai" ,"Tiruvarur" ,"Vellore" ,"Viluppuram" ,"Virudhunagar"]
Telangana = ['Telangana',"Adilabad" ,"Bhadradri Kothagudem" ,"Hanamkonda" ,"Hyderabad" ,"Jagtial" ,"Jangaon" ,"Jayashankar" ,"Jogulamba" ,"Kamareddy" ,"Karimnagar" ,"Khammam" ,"Komaram Bheem" ,"Mahabubabad" ,"Mahbubnagar" ,"Mancherial" ,"Medak" ,"Medchal" ,"Mulugu" ,"Nagarkurnool" ,"Nalgonda" ,"Narayanpet" ,"Nirmal" ,"Nizamabad" ,"Peddapalli" ,"Rajanna Sircilla" ,"Ranga Reddy" ,"Sangareddy" ,"Siddipet" ,"Suryapet" ,"Vikarabad" ,"Wanaparthy" ,"Warangal" ,"Yadadri Bhuvanagiri"]
Tripura = ['Tripura',"Dhalai" ,"Gomati" ,"Khowai" ,"North Tripura" ,"Sepahijala" ,"South Tripura" ,"Unakoti" ,"West Tripura" ]
Uttarakhand = ['Uttarakhand',"Almora" ,"Bageshwar" ,"Chamoli" ,"Champawat" ,"Dehradun" ,"Haridwar" ,"Nainital" ,"Pauri" ,"Pithoragarh" ,"Rudraprayag" ,"Tehri" ,"Udham Singh Nagar" ,"Uttarkashi"]
WestBengal = ['Bengal', "Alipurduar" ,"Bankura" ,"Birbhum" ,"Cooch Behar" ,"Dakshin Dinajpur" ,"Darjeeling" ,"Hooghly" ,"Howrah" ,"Jalpaiguri" ,"Jhargram" ,"Kalimpong" ,"Kolkata" ,"Malda" ,"Murshidabad" ,"Nadia" ,"North 24 Parganas" ,"Paschim Bardhaman" ,"Paschim Medinipur" ,"Purba Bardhaman" ,"Purba Medinipur" ,"Purulia" ,"South 24 Parganas" ,"Uttar Dinajpur"]
information ={
"States":['Andaman Nicobar', 'Andhra Pradesh', 'Arunachal Pradesh',
'Assam', 'Bihar', 'Chandigarh',
'Chhattisgarh', 'Dadra Nagar',
'Delhi', 'Goa', 'Gujarat', 'Haryana', 'Himachal Pradesh',
'Jammu Kashmir', 'Jharkhand', 'Karnataka', 'Kerala',
'Ladakh', 'Lakshadweep', 'Madhya Pradesh', 'Maharashtra',
'Manipur', 'Meghalaya', 'Mizoram', 'Nagaland', 'Odisha',
'Puducherry', 'Punjab', 'Rajasthan', 'Sikkim', 'Tamil Nadu'
, 'Telangana', 'Tripura', 'Uttar Pradesh',
'Uttarakhand', 'West Bengal'],
"Reported":[hd.countOccurancesAny(AndamanNicobar),hd.countOccurancesAny(AndhraPradesh),hd.countOccurancesAny(ArunachalPradesh),
hd.countOccurancesAny(Assam),hd.countOccurancesAny(Bihar),hd.countOccurancesAny(Chandigarh),
hd.countOccurancesAny(Chhattisgarh),hd.countOccurancesAny(Dadra),hd.countOccurancesAny(Delhi),
hd.countOccurancesAny(Goa),hd.countOccurancesAny(Gujrat),hd.countOccurancesAny(Haryana),
hd.countOccurancesAny(HimachalPradesh),hd.countOccurancesAny(JammuKashmir),hd.countOccurancesAny(Jharkand),
hd.countOccurancesAny(Karnataka),hd.countOccurancesAny(Kerala),hd.countOccurancesAny(Ladakh),
hd.countOccurancesAny(Lakshadweep),hd.countOccurancesAny(MadhyaPradesh),hd.countOccurancesAny(Maharashtra),
hd.countOccurancesAny(Manipur),hd.countOccurancesAny(Meghalaya),
hd.countOccurancesAny(Mizoram),hd.countOccurancesAny(Nagaland),hd.countOccurancesAny(Odisha),
hd.countOccurancesAny(Puducherry),hd.countOccurancesAny(Punjab),hd.countOccurancesAny(Rajasthan),
hd.countOccurancesAny(Sikkim),hd.countOccurancesAny(TamilNadu),hd.countOccurancesAny(Telangana),
hd.countOccurancesAny(Tripura),hd.countOccurancesAny(UttarPradesh),hd.countOccurancesAny(Uttarakhand),hd.countOccurancesAny(WestBengal)]
}
df = pd.DataFrame(information)
print(df.sort_values("Reported",ascending=False))
print(df)
# States Reported
# 33 Uttar Pradesh 19712
# 20 Maharashtra 11281
# 8 Delhi 6031
# 13 Jammu Kashmir 5658
# 10 Gujarat 4998
# 12 Himachal Pradesh 4335
# 4 Bihar 3712
# 27 Punjab 3627
# 35 West Bengal 3310
# 19 Madhya Pradesh 2543
# 28 Rajasthan 2293
# 9 Goa 2170
# 11 Haryana 2123
# 1 Andhra Pradesh 2030
# 16 Kerala 2025
# 6 Chhattisgarh 1860
# 5 Chandigarh 1860
# 15 Karnataka 1812
# 30 Tamil Nadu 1799
# 3 Assam 1637
# 25 Odisha 1484
# 31 Telangana 1285
# 17 Ladakh 1158
# 7 Dadra Nagar 587
# 21 Manipur 575
# 34 Uttarakhand 563
# 22 Meghalaya 409
# 2 Arunachal Pradesh 394
# 14 Jharkhand 340
# 26 Puducherry 307
# 32 Tripura 199
# 24 Nagaland 185
# 29 Sikkim 160
# 23 Mizoram 144
# 0 Andaman Nicobar 102
# 18 Lakshadweep 29
Now we are going to proceed to mix the above code to supply statistics for state sensible crime experiences grouped by kind of crime.
I used the next code to derive values for the evaluation we’re performing, changing crimeMerged with the mix of crimes I’m analysing.
crimeMerged = homicide
information ={
"States":['Andaman Nicobar', 'Andhra Pradesh', 'Arunachal Pradesh',
'Assam', 'Bihar', 'Chandigarh',
'Chhattisgarh', 'Dadra Nagar',
'Delhi', 'Goa', 'Gujarat', 'Haryana', 'Himachal Pradesh',
'Jammu Kashmir', 'Jharkhand', 'Karnataka', 'Kerala',
'Ladakh', 'Lakshadweep', 'Madhya Pradesh', 'Maharashtra',
'Manipur', 'Meghalaya', 'Mizoram', 'Nagaland', 'Odisha',
'Puducherry', 'Punjab', 'Rajasthan', 'Sikkim', 'Tamil Nadu'
, 'Telangana', 'Tripura', 'Uttar Pradesh',
'Uttarakhand', 'West Bengal'],
"Reported":[hd.countOccurancesGroupedAny([AndamanNicobar,crimeMerged]),hd.countOccurancesGroupedAny([AndhraPradesh,crimeMerged]),hd.countOccurancesGroupedAny([ArunachalPradesh,crimeMerged]),
hd.countOccurancesGroupedAny([Assam,crimeMerged]),hd.countOccurancesGroupedAny([Bihar,crimeMerged]),hd.countOccurancesGroupedAny([Chandigarh,crimeMerged]),
hd.countOccurancesGroupedAny([Chhattisgarh,crimeMerged]),hd.countOccurancesGroupedAny([Dadra,crimeMerged]),hd.countOccurancesGroupedAny([Delhi,crimeMerged]),
hd.countOccurancesGroupedAny([Goa,crimeMerged]),hd.countOccurancesGroupedAny([Gujrat,crimeMerged]),hd.countOccurancesGroupedAny([Haryana,crimeMerged]),
hd.countOccurancesGroupedAny([HimachalPradesh,crimeMerged]),hd.countOccurancesGroupedAny([JammuKashmir,crimeMerged]),hd.countOccurancesGroupedAny([Jharkand,crimeMerged]),
hd.countOccurancesGroupedAny([Karnataka,crimeMerged]),hd.countOccurancesGroupedAny([Kerala,crimeMerged]),hd.countOccurancesGroupedAny([Ladakh,crimeMerged]),
hd.countOccurancesGroupedAny([Lakshadweep,crimeMerged]),hd.countOccurancesGroupedAny([MadhyaPradesh,crimeMerged]),hd.countOccurancesGroupedAny([Maharashtra,crimeMerged]),
hd.countOccurancesGroupedAny([Manipur,crimeMerged]),hd.countOccurancesGroupedAny([Meghalaya,crimeMerged]),
hd.countOccurancesGroupedAny([Mizoram,crimeMerged]),hd.countOccurancesGroupedAny([Nagaland,crimeMerged]),hd.countOccurancesGroupedAny([Odisha,crimeMerged]),
hd.countOccurancesGroupedAny([Puducherry,crimeMerged]),hd.countOccurancesGroupedAny([Punjab,crimeMerged]),hd.countOccurancesGroupedAny([Rajasthan,crimeMerged]),
hd.countOccurancesGroupedAny([Sikkim,crimeMerged]),hd.countOccurancesGroupedAny([TamilNadu,crimeMerged]),hd.countOccurancesGroupedAny([Telangana,crimeMerged]),
hd.countOccurancesGroupedAny([Tripura,crimeMerged]),hd.countOccurancesGroupedAny([UttarPradesh,crimeMerged]),hd.countOccurancesGroupedAny([Uttarakhand,crimeMerged]),hd.countOccurancesGroupedAny([WestBengal,crimeMerged])]
}
df = pd.DataFrame(information)
print(df.sort_values("Reported",ascending=False))
The visualization in types of a warmth map for the three heavies (when it comes to the vary of dataset) is as follows:
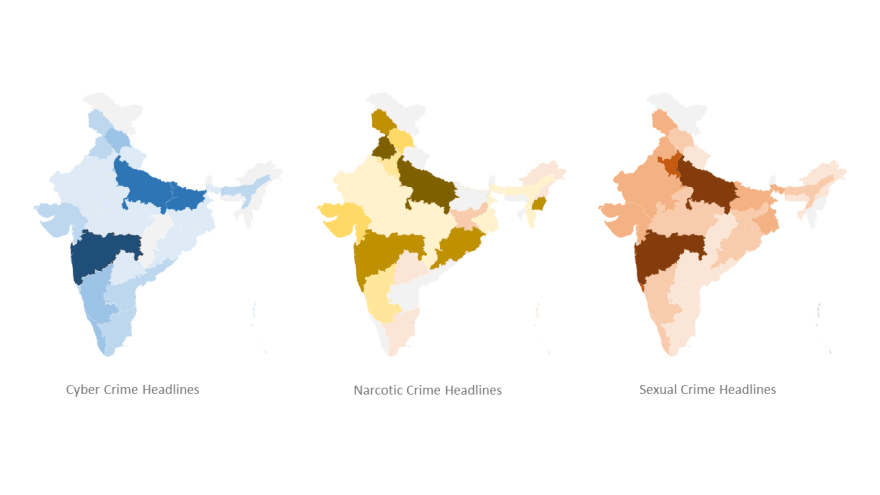 |
|---|
| Right here darker colors symbolize heavier depth of the labelled crime. |
This can be a related heatmap which encompasses a common picture of crime depth over the Indian states:
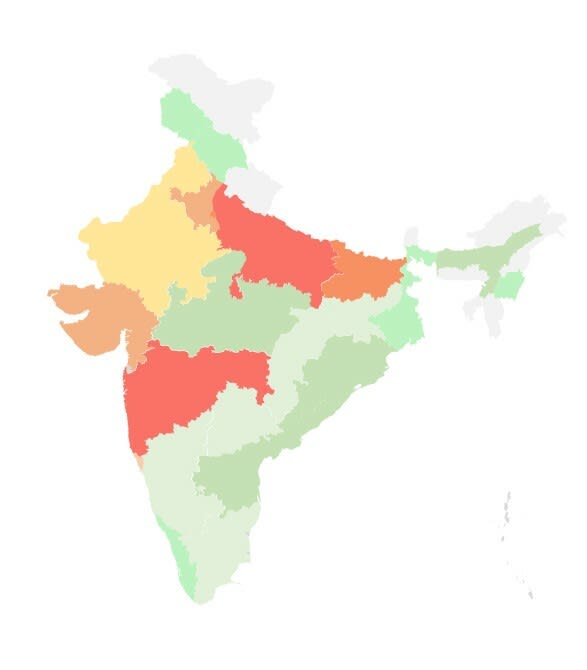 |
|---|
| Map of India: Hotter colors symbolize heavier depth. |
The crime information statistics really correspond to the actual crime stats of the states as per authorities information. The one exception are the southern states. The southern states present a lot decrease numbers in journalistic information in comparison with precise govt information. This raises an fascinating query on what the explanation will be? Is it journalistic bias? Sadly I’m not certified to reply that query however I do encourage you to search out the reply to this query.
The Three Khans of Bollywood
I nonetheless bear in mind when a well-known saying was once “Bollywood is dominated by the Three Khans”. Properly to take a lighter (away from crime and politics) take a look at the info, lets see which khan finally ends up the preferred amongst the three.

Right here is the code which was run to search out the preferred amongst the three.
srk = ["srk","shah rukh"]
salman = ["salman","sallu"]
amir = ["aamir",]
information = {"Actor":["SRK","Salman","Amir"],
"Reported":[hd.countOccurancesAny(srk),hd.countOccurancesAny(salman),hd.countOccurancesAny(amir)]
}
df = pd.DataFrame(information)
print(df.sort_values("Reported",ascending=False))
# Actor Reported
# 1 Salman 335
# 0 SRK 304
# 2 Amir 130
Because it seems its the “Bhai” of the trade. To be very trustworthy it is sensible with how loopy his followers are.
PART 4: Epilogue
The intention of this endeavour was to make obtainable a device to have the ability to carry out evaluation like those proven above. And in that I’ve succeeded.
The scripts for the Net Scraper and the Headline Evaluation Features is accessible on the undertaking repository.
It was extraordinarily enjoyable and informative engaged on this undertaking. I discovered and gained expertise with the next:
- Net Scraping (BeautifulSoup, requests)
- Key phrase Evaluation
- Knowledge Visualization
- Knowledge Evaluation (pandas, matplotlib)
- Open Supply and Model Management
Thankyou very a lot for studying by the entire write-up. I actually hope you discovered it fascinating. Please go away a remark sharing any suggestions.

{kind=link}